在最小化日志操作解析,應用的文章中有朋友反映生成測試數據較慢.在此跟大家分享一個簡單的應用,在生成數據過程中采用批量提交的方式以加快數據導入.
此應用不光生成測試數據上,在BCP導入數據中,復制初始化快照過程中等都可以根據系統環境調整 batchSize 的大小來提高導入/初始化速度.
應用思想:這里簡單介紹下組提交概念,由于關系型數據庫依靠日志來保證數據完整性,即先寫日志,每當一個事務完成時就需要commit日志刷入磁盤,在高并發短小事務的前提下由于日志頻繁落盤導致整體寫吞吐下降.用Group Commit方式將一批事務(相同,或不同session)成組批量提交完成,降低日志寫的頻繁度,使得日志批量刷入磁盤,從而提高性能.但此方式會一定程度降低響應時間(因為提交的事務可能等待其他事務一起提交)
Sql server中沒有提供組提交的響應方式,但開發人員可以在應用可控前提下,自行根據環境實現類似功能:)
這里引用生成測試數據的方式分別應用"代碼 1"一般生成數據方式,"代碼 2"批量提交生成數據方式給大家做個簡單的實例.
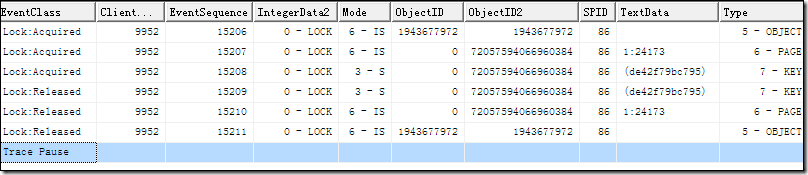
圖1-1為兩種生成方式下性能計數器Log Flushs/sec的比較,用來描述“Sql Server Group Commit"的優勢
代碼1 按照一般方式生成測試數據:在我本機的執行時間為56s
create table t1(id int not null identity (1,1),dystr varchar(200),fixstr char(500));godeclare @beginTime datetime,@endTime datetimeset @beginTime=GETDATE()set nocount ondeclare @i intset @i=0while(@i<200000)begin insert into t1(dystr,fixstr)values('aaa'+str(RAND()*100000000),'bbb'+str(RAND()*100000000)) set @i=@i+1endset @endTime=GETDATE()select @endTime-@beginTime----------56s my PC代碼2 按照批量方式(組提交)生成測試數據. 在我本機的執行時間為4s!
Checkpoint-----flush data to diskDbcc dropcleanbuffers -----drop data cachecreate table t2(id int not null identity (1,1),dystr varchar(200),fixstr char(500));godeclare @beginTime datetime,@endTime datetimeset @beginTime=GETDATE()set nocount on declare @batchSize intset @batchSize=1000declare @i intset @i=0while(@i<20000)begin if (@i%@batchSize=0) begin if (@@TRANCOUNT>0)COMMIT TRAN BEGIN TRAN end insert into t2(dystr,fixstr)values('aaa'+str(RAND()*100000000),'bbb'+str(RAND()*100000000)) set @i=@i+1end if (@@TRANCOUNT>0)COMMIT TRANselect @endTime-@beginTime----------4s my PC兩種方式下Perf count中Log Flushs/sec對比
新聞熱點






疑難解答