以前有 DBA 在身邊的時(shí)候,從來不曾考慮過數(shù)據(jù)庫(kù)性能的問題,但是,當(dāng)一個(gè)應(yīng)用程序從頭到腳都由自己完成,而且數(shù)據(jù)庫(kù)面對(duì)的是接近百萬(wàn)的數(shù)據(jù),看著一個(gè)頁(yè)面加載速度像烏龜一樣,自己心里真是有種挫敗感。代碼的優(yōu)化問題,這是屬于程序員的職責(zé)范圍之內(nèi),對(duì)于我來說,這一方面比較好探查些,因?yàn)槎际亲约菏煜さ模?EF 或 SQL Server PRofiler 跟蹤一下程序代碼產(chǎn)生的 SQL,如果有問題,直接優(yōu)化程序代碼就可以了,如果 SQL 沒問題,那就得優(yōu)化數(shù)據(jù)庫(kù)了,對(duì)于我來說,這是一個(gè)無(wú)人區(qū)。
前兩天,自己瞎搞了一個(gè)測(cè)試:程序員眼中的 SQL Server-非聚集索引能給我們帶來什么?,因?yàn)閷?duì)索引不是很熟悉,所以測(cè)試得到結(jié)果沒有任何價(jià)值,甚至有些誤導(dǎo)人,這邊說聲抱歉,在哪跌倒在哪爬起來。
應(yīng)用場(chǎng)景還是用商品表(Product)作為示例,表結(jié)構(gòu)如下:

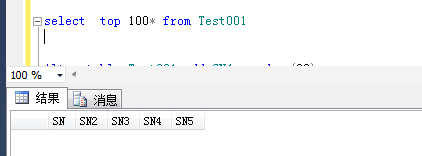
存在這樣一種業(yè)務(wù)場(chǎng)景:獲取某個(gè)供應(yīng)商(ProviderID),狀態(tài)為已售(State 為 1)的商品列表,排序方式為生產(chǎn)日期(ProduceTime)降序,有可能我們應(yīng)用程序在顯示數(shù)據(jù)的時(shí)候用到分頁(yè),這邊我們查詢前 100 行。翻譯為 SQL 代碼:
SELECT TOP 100 [ID],[Name],[Remarks],[ProviderID],[ProduceTime],[State]FROM [TestDB].[dbo].[Product]WHERE [ProviderID]=1 AND [State]=1ORDER BY [ProduceTime] DESC上面這個(gè)業(yè)務(wù)場(chǎng)景,在我們一般的應(yīng)用程序中基本上都會(huì)遇到,有時(shí)候數(shù)據(jù)量不是很大的時(shí)候,我們一般不會(huì)做任何數(shù)據(jù)庫(kù)優(yōu)化,但是你看了下面的實(shí)踐,你是否應(yīng)該考慮下,為你現(xiàn)在的數(shù)據(jù)庫(kù)加個(gè)索引呢?
SQL Server 執(zhí)行計(jì)劃
SQL Server 執(zhí)行計(jì)劃,是我們分析 SQL 執(zhí)行情況的一大利器,通過它,我們也可以很方面的查看索引的執(zhí)行,在實(shí)踐之前,需要了解一些必備技能,以下知識(shí)點(diǎn)摘自-看懂 SqlServer 查詢計(jì)劃。
SQL Server 有二種索引:聚集索引和非聚集索引。二者的差別在于:【聚集索引】直接決定了記錄的存放位置, 或者說:根據(jù)聚集索引可以直接獲取到記錄。【非聚集索引】保存了二個(gè)信息:1.相應(yīng)索引字段的值,2.記錄對(duì)應(yīng)聚集索引的位置(如果表沒有聚集索引則保存記錄指針)。 因此,如果能通過【聚集索引】來查找記錄,顯然也是最快的。
SQL Server 會(huì)有以下方法來查找您需要的數(shù)據(jù)記錄:
所以,當(dāng)發(fā)現(xiàn)某個(gè)查詢比較慢時(shí),可以首先檢查哪些操作的成本比較高,再看看那些操作在查找記錄時(shí), 是不是【Table Scan】或者【Clustered Index Scan】,如果確實(shí)和這二種操作類型有關(guān),則要考慮增加索引來解決了。 不過,增加索引后,也會(huì)影響數(shù)據(jù)表的修改動(dòng)作,因?yàn)樾薷臄?shù)據(jù)表時(shí),要更新相應(yīng)字段的索引。所以索引過多,也會(huì)影響性能。 還有一種情況是不適合增加索引的:某個(gè)字段用0或1表示的狀態(tài)。例如可能有絕大多數(shù)是1,那么此時(shí)加索引根本就沒有意義。 這時(shí)只能考慮為0或者1這二種情況分開來保存了,分表或者分區(qū)都是不錯(cuò)的選擇。
應(yīng)用分析我們先不建任何索引(除了主鍵 ID 的聚集索引),來看一下上面 SQL 代碼,在 SQL Server 執(zhí)行計(jì)劃中的執(zhí)行情況:

可以看到,查詢開銷基本上被 SORT 霸占了,看到這種情況,按照正常的思維,我們首先考慮的是為 ProduceTime 創(chuàng)建一個(gè)非聚集索引,然后按照 DESC 排序,但有時(shí)候我們要沉下心思考一下,是不是用 ID 排序會(huì)更好呢?因?yàn)樵?Product 表中,ID 為自增字段,ProduceTime 在添加的時(shí)候獲取的是當(dāng)前時(shí)間,在 SQL 排序中,其實(shí) ID 和 ProduceTime 的排序效果是一樣的,但是執(zhí)行性能方面確實(shí)天壤之別,我們看一下執(zhí)行計(jì)劃就知道了:

從上面的執(zhí)行計(jì)劃中,我們可以很直觀的看出差別,所以在寫 SQL 的時(shí)候,一定要慎重啊,這邊為了方便展示,我們還是以 ProduceTime 字段進(jìn)行排序,按照 ID 排序,雖然沒有了 SORT 性能開銷,但是發(fā)現(xiàn)查詢記錄為“Clustered Index Scan”,這是全表查詢的意思,我們理想的應(yīng)該是“Index Seek”或者“Clustered Index Seek”,因?yàn)檫@種是按照索引查詢,速度最快。按照我們程序員的理解,應(yīng)該創(chuàng)建一個(gè)非聚集索引,比如下面 IX_Product_Provider_State 索引:

創(chuàng)建好之后,我們?cè)賮韴?zhí)行一下 SQL 代碼:

“Key Lookup(Clustered)”記錄,其實(shí)還是全表進(jìn)行查找,默認(rèn)通過聚集索引(PK_Product),我們可能會(huì)有疑問,索引就是按照查詢及排序方式創(chuàng)建的啊,為什么還是這種情況?這時(shí)候我們看一下 SELECT 后面的字段就知道了,我們查詢顯示的是 Product 表中所有字段,但是 IX_Product_Provider_State 非聚集索引,只是針對(duì)的查詢條件字段,并沒有吧查詢顯示字段包含進(jìn)來,在創(chuàng)建索引窗口中,“索引鍵 列” TAB 的旁邊有個(gè)“包含性 列”,我們把其他顯示字段加進(jìn)來,看下執(zhí)行效果:

“Index Seek”,這就是我們想要的效果,其實(shí)關(guān)于索引的創(chuàng)建有很多的現(xiàn)實(shí)問題,比如組合字段索引和單個(gè)字段索引有何不同?就像上面示例中的查詢用例,如果 ProduceTime 排序在其他查詢條件中也存在,是不是應(yīng)該拉出來創(chuàng)建一個(gè)索引?還是像上面一樣,和查詢條件一起創(chuàng)建一個(gè)組合字段索引?還有一種情況就是,在一個(gè)應(yīng)用程序查詢中,存在單個(gè)字段的查詢,也存在組合字段的查詢,那這時(shí)候我們是創(chuàng)建單個(gè)字段索引?還是創(chuàng)建組合字段索引呢?這幾個(gè)問題,你創(chuàng)建一下索引,然后用“ SQL 執(zhí)行計(jì)劃”試試就知道了。
總結(jié)針對(duì)上面的查詢用例,我個(gè)人覺得,最好的方案是:排序字段使用 ID,按照實(shí)際應(yīng)用場(chǎng)景,提取出需要查詢的字段,避免 SELECT *,這樣會(huì)減少在添加“包含性 列”的字段,創(chuàng)建 IX_Product_Provider_State 非聚集索引,索引字段為:ProviderID 和 State,如果 State 的值不是多變的(比如值為 1 和 0),盡量不要?jiǎng)?chuàng)建 State 字段的非聚集索引。
做完這些,你會(huì)發(fā)現(xiàn),你的應(yīng)用程序像飛的一樣。
ps:我要飛得更高。。。
參考資料:
新聞熱點(diǎn)






疑難解答
圖片精選