我們在學(xué)sqlserver的時候,大多教科書和前輩們都說狀態(tài)少的字段不要建索引,由此帶來的開銷還不如不建索引,但是這句話有多少人真的知道,
或者說有多少人真的對此有比較深刻的理解,而不是聽別人道聽途說。。。這樣記得快,忘記的也不慢。。。這篇我來分析一下這句話到底有幾個意思。
一:現(xiàn)象
首先我們還是用測試數(shù)據(jù)來發(fā)現(xiàn)問題,我先建立一個Person,有5個字段,建表sql如下:
DROP TABLE dbo.PersonCREATE TABLE Person(ID INT PRIMARY KEY IDENTITY,NAME VARCHAR(900),Age INT,Email VARCHAR(20),isMan INT )-- 在isMan字段創(chuàng)建非聚集索引(0:女 1:男)CREATE INDEX idx_isMan ON dbo.Person(isMan)DECLARE @ch AS INT=0WHILE @ch<=100000BEGIN INSERT INTO dbo.Person(NAME,Age,Email,isMan) VALUES ( REPLICATE(CHAR(@ch),50), @ch, CAST(CAST(RAND()*1000000000 AS INT) AS VARCHAR(10))+'QQ.com', @ch%2 ) SET @ch=@ch+1END
通過上面的sql可以發(fā)現(xiàn)表中有5個字段,ID為聚集索引,isMan為非聚集索引,isMan也就是兩種狀態(tài)(0,1),并且插入10w條記錄,截圖如下:

sql都做完了,接下來要做的事情就是查詢下: isMan=1的記錄,如下圖:


麻蛋。。。。哥哥明明是在isMan上做數(shù)據(jù)檢索的,怎么就變成 “聚集索引掃描”了???這他么的什么意思嘛,居然不走我的“idx_isMan”索引,
卻走他么的“聚集索引(PK__Person__3214EC276EF57B66)”。。。。同時也看到上面的”邏輯讀取”為521。。。說明在內(nèi)存中走了521個數(shù)據(jù)頁。
但是我不服呀。。。我一定要讓執(zhí)行計劃走我的索引。。。辦法就是強(qiáng)制指定。。。如下圖。



看到上面的圖,你是不是已經(jīng)瘋了。。。老子才撈5w的數(shù)據(jù),你給我走了10w多次數(shù)據(jù)頁。。。這么說1條記錄要走兩個數(shù)據(jù)頁。。。而掃描聚集
索引才走521個數(shù)據(jù)頁,相差200倍。。。難怪執(zhí)行計劃打死也不走“idx_isMan”這條索引。。。要是這樣走了人家還不拿刀捅了sqlserver么???
二:分析原因
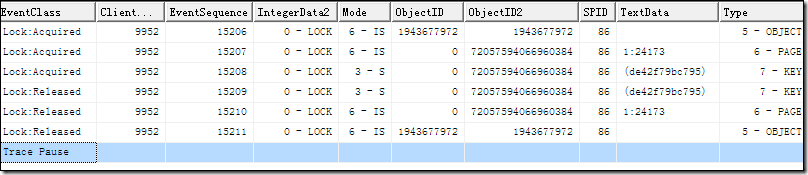
現(xiàn)在很生氣,整個人都不好了,為什么會這樣???為了找出問題,我們還得看數(shù)據(jù)頁。
1 DBCC TRACEON(3604,2588)2 DBCC IND(Ctrip,Person,-1)



通過上面的三個圖,大概可以看到,10w條數(shù)據(jù)用了697數(shù)據(jù)頁,其中聚集索引有521個,非聚集索引為176個,這也說明了上面的”聚集索引掃描“走
遍了它自己所有的數(shù)據(jù)頁來才撈出數(shù)據(jù),同時還發(fā)現(xiàn)這兩個索引都有一個共同特征就是,只有一個根節(jié)點(diǎn)(indexLevel=1)和無數(shù)個(indexLevel=0)
葉子節(jié)點(diǎn),然后我腦子里面就有一幅圖出來了。。。

上面就是我構(gòu)思出來的圖,這個專業(yè)一點(diǎn)的名字叫做書簽查找。。。我們通過建立”idx_isMan“索引后,就會構(gòu)建右半圖的B樹結(jié)構(gòu),其中索引記錄
會存放兩個值,一個是索引值isMan和一個聚集索引值ID,如果你不相信的話,可以通過DBCC Page去探索"idx_isMan"的索引頁,你也可以通過
DBCCSHOW_STATISTICS 去查看,如圖:

然后引擎通過“idx_isMan“掃描后,拿到了key值,但是非常可惜,我是select * 的,所以必須還要噴出記錄中的Name,Emai等l字段,但是
”index_isMan"中并沒有保存這幾個字段,所以必須通過key去”聚集索引“的B樹中去找。。。最后通過”聚集索引“的B樹找到了目標(biāo)記錄,這也
就是所謂的執(zhí)行計劃中的”鍵查找“,然后噴出”Name,Email“等字段。。。。問題就在這里。。。因?yàn)槲疫@樣來回的蹦跶蹦跶。。。造成了找出
完整的一個記錄,需要蹦跶2-3次數(shù)據(jù)頁。。。具體的尋找記錄,可參考圖中的”紫色線條“,最后也就造成了10w多次蹦跶。。。
三:啟示
那這個例子給我們什么啟示呢???仔細(xì)想想你就知道。。。使用非聚集索引,千萬不要撈取過多的數(shù)據(jù)。。。因?yàn)檫^多的數(shù)據(jù)會造成在多個
B樹中來回的蹦跶。。。想要做到撈取數(shù)據(jù)較少,就必須在高唯一性的字段上建立索引,這樣的話在非聚集索引B樹中符合的數(shù)據(jù)相對較少,也就
減少了我蹦跶到”主鍵索引“的B樹次數(shù)。。。這樣的話來回蹦跶的次數(shù)遠(yuǎn)遠(yuǎn)比”聚集索引“掃描來的實(shí)惠,對不對。。。
所以結(jié)論出來了:必須在唯一性較高的字段上建立非聚集索引。
新聞熱點(diǎn)






疑難解答
圖片精選