說到sql的參數化處理,我也是醉了,因為sql引擎真的是一個無比強大的系統,我們平時做系統的時候都會加上緩存,我想如果沒有緩存,就不會有什么
大網站能跑的起來,而且大公司一般會在一個東西上做的比較用心,比較細,sqlserver同樣也使用了緩存,其中就包括Data cache 和Plan cache兩個大頭。
現在我們也知道了Plan cache包括上一篇生成的xml結構和sql text,更有趣的是,sql text 還可以做到參數化。。。也就是模板化了。。
一:Sql參數化
<1>先來做一個Person表,插入1000條數據,然后清空下緩存,再select出一個數據,如圖:
1 DROP TABLE dbo.Person2 CREATE TABLE Person(ID INT IDENTITY,NAME CHAR(5) DEFAULT 'aaaaa')3 INSERT INTO dbo.Person DEFAULT VALUES4 go 10005 6 DBCC freePRoccache7 SELECT * FROM dbo.Person WHERE ID=100

<2> 數據已經查詢出來了,下面我們看下dm_exec_sql_text中的sql會是怎樣?
1 SELECT usecounts,objtype,cacheobjtype, plan_handle,query_plan,text FROM sys.dm_exec_cached_plans2 CROSS APPLY sys.dm_exec_query_plan(plan_handle)3 CROSS APPLY sys.dm_exec_sql_text(plan_handle)4 WHERE text LIKE '%Person%'

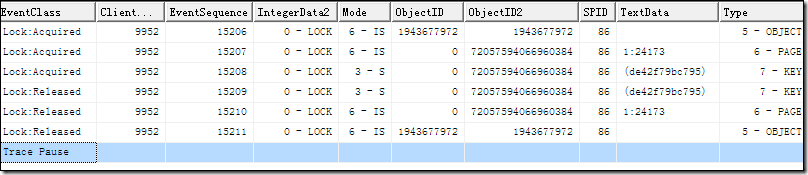
從上面的圖中可以看到,當我select一下后,出現了兩個sql text,第一個叫Adhoc(即時查詢),一個叫Prepared(參數化),然后我點擊第二個記錄
的query_plan,會出現圖形化的執行計劃,如下圖:

跟著好奇心,我繼續點擊第三個記錄的query_plan會是怎樣???

通過這兩個sql text的執行計劃,不知道你觀察出來下面四點了沒有:
(1)我的sql是執行表掃描的,這個沒有問題,問題在于我的兩個sql text中,第一個plan居然沒有完整的執行計劃,而僅僅是一個圖形化的select,
第二個參數化sql,它的plan是一個完整的執行計劃。。。那這說明什么呢???既然Prepared是完整的執行計劃,那干嘛還要把adhoc這個
sql緩存起來呢???其實這個我也不清楚。。。我猜測肯定是讓引擎快速的找到prepared這個完整的執行計劃吧。。。
(2) 就是想為什么sqltext要做參數化,仔細想想應該明白參數化的目的就是為了重用執行計劃,因為這時候的xml已經生成好了,不然的話,你
每次執行的sql中只要參數不同都要生成一次query_plan的xml,是不是會拉查詢速度的后腿呢???
(3) 你有沒有關注到參數化的類型是tinyint,看到這個tinyint我馬上就想破它了,我們知道tinyint就是byte類型,表示的范圍也就到256...也許
引擎看我where 100才覺得我好欺負。。。那我現在想法就是where 500,看看會是什么效果???
1 SELECT * FROM dbo.Person WHERE ID=5002 3 SELECT usecounts,objtype,cacheobjtype, plan_handle,query_plan,text FROM sys.dm_exec_cached_plans4 CROSS APPLY sys.dm_exec_query_plan(plan_handle)5 CROSS APPLY sys.dm_exec_sql_text(plan_handle)6 WHERE text LIKE '%Person%'

從圖中可以看到,當我where 500的時候,引擎會再次生成一個prepared的sqltext,這樣就有兩個prepared了,那我在想,為什么不直接
給一個(@1 int)呢???像目前這樣sql引擎的處理方式,會有幾條prepared記錄的xml和sqltext的,是不是有點浪費內存呢?
(4) 仔細想想你會知道,sql引擎還是挺色膽包天的,因為prepared的記錄已生成,執行計劃也就生成了。。。。那說明什么呢???說明這時候
的xml已經是死的了,也就說明執行計劃也是定死的了,難道@1參數的不同不會導致執行計劃有變更么???如果有變更難道還讓我執行原來
這個表掃描執行計劃么???有點奇葩,好了,我準備在下面仔細說說。
二:參數的變化對prepared的影響
如果你看過之前的博文,你應該明白有一個叫做書簽查找的玩意。。。它的原理是在非聚集索引上通過B樹查找,當查找到目標鍵的時候拿到這
個鍵的聚集索引key,然后通過key來取數據的記錄,如果你的非聚集索引的鍵值的唯一性比較高,這時候sql引擎會走書簽查找,但是如果你的鍵值
唯一性比較低或者在數據量比較小的情況,sql引擎就不會走書簽查找,而轉向聚集索引掃描。。。那這說明什么呢?說明執行計劃在有些時候會跟
(@1 int)這個值有關系。。。那這樣的話貌似就不能重用執行計劃了,對吧。。。。為了驗證sql引擎怎么處理的,我們來做一個測試。
1.先清空緩存,再在Name列上建索引,然后我們select下,如下圖:
1 DBCC freeproccache2 CREATE INDEX idx_Name ON dbo.Person(NAME)3 SELECT * FROM dbo.Person WHERE NAME='aaaaa'
2. 然后還是繼續看看xml和sqltext

你有什么發現嗎?在記錄中并沒有發現什么prepared記錄,這說明什么。。。說明sqlserver很聰明,它知道Name可能會有 “表掃描”到
“書簽掃描”的來回切換,為了驗證問題,我繼續向Person表插入1w條數據,然后再插入一個唯一性數據。如下圖:
1 INSERT INTO dbo.Person DEFAULT VALUES2 go 100003 INSERT INTO dbo.Person(NAME ) VALUES ('ccccc')
確實,如我猜想的一樣,sqlserver很聰明的。。。如果它覺得這個Name不靠譜的話,它是絕對不敢給這條sqltext生成prepared的。。。轉過
頭來再想想第一條為什么會有sqltext,那是因為a列不管取值多少,都改變不了走表掃描的現實,所以sql引擎才敢這么大膽。。。突然覺得人生
不就是這樣嘛????很多人都是不把穩的事情是絕對不敢做的。。。
新聞熱點






疑難解答