標(biāo)簽:SQL SERVER/MSSQL SERVER/數(shù)據(jù)庫(kù)/DBA/索引體系結(jié)構(gòu)/非聚集索引
概述非聚集索引與聚集索引具有相同的 B 樹結(jié)構(gòu),它們之間的顯著差別在于以下兩點(diǎn):
既可以使用聚集索引來(lái)為表或視圖定義非聚集索引,也可以根據(jù)堆來(lái)定義非聚集索引。非聚集索引中的每個(gè)索引行都包含非聚集鍵值和行定位符。此定位符指向聚集索引或堆中包含該鍵值的數(shù)據(jù)行。
非聚集索引行中的行定位器或是指向行的指針,或是行的聚集索引鍵,如下所述:
對(duì)于索引使用的每個(gè)分區(qū),非聚集索引在 index_id >0 的 sys.partitions 中都有對(duì)應(yīng)的一行。默認(rèn)情況下,一個(gè)非聚集索引有單個(gè)分區(qū)。如果一個(gè)非聚集索引有多個(gè)分區(qū),則每個(gè)分區(qū)都有一個(gè)包含該特定分區(qū)的索引行的 B 樹結(jié)構(gòu)。例如,如果一個(gè)非聚集索引有四個(gè)分區(qū),那么就有四個(gè) B 樹結(jié)構(gòu),每個(gè)分區(qū)中一個(gè)。
根據(jù)非聚集索引中數(shù)據(jù)類型的不同,每個(gè)非聚集索引結(jié)構(gòu)會(huì)有一個(gè)或多個(gè)分配單元,在其中存儲(chǔ)和管理特定分區(qū)的數(shù)據(jù)。每個(gè)非聚集索引至少有一個(gè)針對(duì)每個(gè)分區(qū)的 IN_ROW_DATA 分配單元(存儲(chǔ)索引 B 樹頁(yè))。如果非聚集索引包含大型對(duì)象 (LOB) 列,則還有一個(gè)針對(duì)每個(gè)分區(qū)的 LOB_DATA 分配單元。此外,如果非聚集索引包含的可變長(zhǎng)度列超過(guò) 8,060 字節(jié)行大小限制,則還有一個(gè)針對(duì)每個(gè)分區(qū)的 ROW_OVERFLOW_DATA 分配單元。有關(guān)分配單元的詳細(xì)信息,請(qǐng)參閱表組織和索引組織。B 樹的頁(yè)集合由 sys.system_internals_allocation_units 系統(tǒng)視圖中的 root_page 指針定位。
要很好的理解這篇文章的內(nèi)容之前需要先閱讀我前面寫的上中部分的兩篇文章:
SQL Server 深入解析索引存儲(chǔ)(中)
SQL Server 深入解析索引存儲(chǔ)(上)
正文非聚集索引結(jié)構(gòu)
生成測(cè)試數(shù)據(jù)
CREATE TABLE Torder(ID INT IDENTITY(1,1) NOT NULL,NAME CHAR(100) NOT NULL,PRo VARCHAR(8000) NULL,Statu INT NOT NULL,IDATE DATETIME DEFAULT(GETDATE()))GO---插入1000條測(cè)試數(shù)據(jù)DECLARE @ID INT=1WHILE(@ID<=1000)BEGININSERT INTO Torder(NAME,pro,Statu)VALUES('商品'+CONVERT(CHAR(20),@ID),REPLICATE(1,8000),LEFT(@ID,1))SET @ID=@ID+1 ENDGO---創(chuàng)建非聚集索引CREATE INDEX IX_Torder ON Torder(NAME,Statu)INCLUDE(IDATE)SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_pageFROM sys.objects soINNER JOIN sys.partitions sp ON so.object_id = sp.object_idINNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_idINNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_idWHERE so.object_id = object_id('Torder') 
由于創(chuàng)建的表只有非聚集索引,所以整個(gè)表的頁(yè)存儲(chǔ)中有三部分?jǐn)?shù)據(jù):堆頁(yè)面、溢出頁(yè)面、索引頁(yè)面;
堆中共有20個(gè)數(shù)據(jù)頁(yè)和一個(gè)IAM頁(yè);
溢出單元有1001個(gè)頁(yè)面包括一個(gè)IAM頁(yè);
索引中共有20個(gè)頁(yè)其中18個(gè)數(shù)據(jù)頁(yè)一個(gè)ROOT頁(yè)和一個(gè)IAM頁(yè).
一個(gè)堆頁(yè)對(duì)應(yīng)多個(gè)溢出頁(yè),因?yàn)镻ro有8000個(gè)字節(jié)所以一行占一頁(yè),而表的其它字段只有116個(gè)字節(jié)一個(gè)堆頁(yè)可以存50條記錄,所以并不是一個(gè)溢出頁(yè)就唯一對(duì)應(yīng)一個(gè)堆頁(yè)
分析頁(yè)的存儲(chǔ)信息
---開啟跟蹤標(biāo)志DBCC TRACEON(3604,2588)--DBCC TRACEOFF(3604,2588)---獲取對(duì)象的數(shù)據(jù)頁(yè),結(jié)構(gòu):數(shù)據(jù)庫(kù)、對(duì)象、顯示DBCC IND(Ixdata,Torder,-1)
上一章中已經(jīng)講過(guò)了堆頁(yè)面和溢出頁(yè)面,所以現(xiàn)在就講非聚集索引頁(yè)

看過(guò)前面的文章應(yīng)該一眼就能看出1281頁(yè)是ROOT頁(yè),現(xiàn)在就分析1281頁(yè)
分析非聚集索引根頁(yè)
DBCC page(Ixdata,1,1281,3)

現(xiàn)在來(lái)分析行定位指針是怎樣的:0x6801000001002F00
除去開頭的16進(jìn)制標(biāo)示,剩下總共8個(gè)字節(jié),從右往左其中行號(hào)2個(gè)字節(jié),文件標(biāo)示ID2個(gè)字節(jié),剩下的4個(gè)字節(jié)就是頁(yè)號(hào)了,所以
行號(hào)(002f)=47
文件頁(yè)(0001)=1
頁(yè)號(hào)(00000168)=360頁(yè)
現(xiàn)在查看360頁(yè)的信息
DBCC page(Ixdata,1,360,3)

47行的記錄正好是“商品150”
分析非聚集索引索引頁(yè)

通過(guò)對(duì)比會(huì)發(fā)現(xiàn)索引頁(yè)比根頁(yè)多出了索引包含列值和鍵的哈希值,這個(gè)里面的keyhashvalue應(yīng)該是NAME字段的值通過(guò)某種方法算出來(lái)的,應(yīng)該不包括statu字段,這里只是猜測(cè)通過(guò)平時(shí)的查詢你會(huì)產(chǎn)生這樣的猜測(cè),當(dāng)你where條件只有statu的時(shí)候是不走索引查找的。
測(cè)試簡(jiǎn)單的查詢
這里的'商品150'和'商品153'都是1280頁(yè)中的記錄,1280頁(yè)是索引頁(yè),其中'商品150'是該頁(yè)的第一條記錄
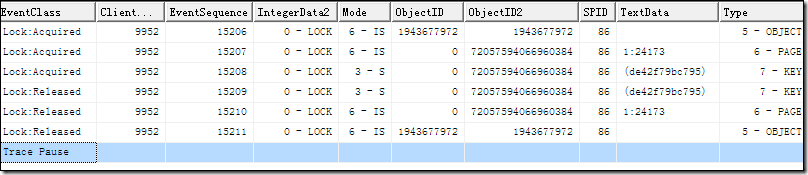
SET TRANSACTION ISOLATION LEVEL REPEATABLE READBEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品153'--COMMIT 另開一個(gè)窗口SELECT[request_session_id],c.[program_name],DB_NAME(c.[dbid]) AS dbname,[resource_type],[request_status],[request_mode],[resource_description],OBJECT_NAME(p.[object_id]) AS objectname,p.[index_id]FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS pON a.[resource_associated_entity_id]=p.[hobt_id]LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查詢申請(qǐng)鎖的數(shù)據(jù)庫(kù)ORDER BY [request_session_id],[resource_type]


從上面的查詢過(guò)程可以知道頁(yè)面總共讀取了三次(索引葉一次堆頁(yè)一次溢出頁(yè)一次)。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READGO BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品150'



通過(guò)對(duì)比查詢'商品150'和'商品153'可以看到如果查找的頁(yè)面的第一條記錄,它需要再讀取該索引頁(yè)的前一個(gè)頁(yè)面,如果該索引頁(yè)是第一頁(yè)就無(wú)需再讀除本身的其他索引頁(yè)了,文章寫到后面反過(guò)來(lái)思考才知道為什么非聚集索引還需要多查找一個(gè)頁(yè)面了。因?yàn)榉蔷奂饕窃试S存在重復(fù)值所以才需要再往前查找,如果前面一個(gè)頁(yè)查找不到則結(jié)束,如果前面一個(gè)頁(yè)還沒查完會(huì)再往前一個(gè)頁(yè)進(jìn)行查,當(dāng)然查詢商品153的時(shí)候就已經(jīng)判斷了前一條記錄的鍵值是不一樣的否則也是要再查詢前一個(gè)頁(yè),這也是非聚集索引的一個(gè)特殊情況吧!
索引掃描
update Torderset statu=100where id=1SET TRANSACTION ISOLATION LEVEL REPEATABLE READGO BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE [Statu]=100
該查詢總共掃描了18個(gè)索引頁(yè)+1個(gè)堆頁(yè)+1個(gè)溢出頁(yè).
創(chuàng)建聚集索引
ALTER TABLE dbo.Torder ADD CONSTRAINT PK_Torder PRIMARY KEY CLUSTERED ( ID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_pageFROM sys.objects soINNER JOIN sys.partitions sp ON so.object_id = sp.object_idINNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_idINNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_idWHERE so.object_id = object_id('Torder') 
非聚集索引數(shù)據(jù)頁(yè)比之前少了一頁(yè)

由于現(xiàn)在的指針比之前的16進(jìn)制指針要所占有的字節(jié)要少,所以只需要17個(gè)頁(yè)面就可以存下。
分析索引頁(yè)148

SET TRANSACTION ISOLATION LEVEL REPEATABLE READBEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品152'在另一個(gè)窗口打開SELECT[request_session_id],c.[program_name],DB_NAME(c.[dbid]) AS dbname,[resource_type],[request_status],[request_mode],[resource_description],OBJECT_NAME(p.[object_id]) AS objectname,p.[index_id]FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS pON a.[resource_associated_entity_id]=p.[hobt_id]LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查詢申請(qǐng)鎖的數(shù)據(jù)庫(kù)ORDER BY [request_session_id],[resource_type]


從上面的邏輯讀取和查詢步驟可以證實(shí)前面的猜測(cè),應(yīng)該是隱藏了一張行定位表。
如果表有聚集索引或索引視圖上有聚集索引,則行定位器是行的聚集索引鍵。如果聚集索引不是唯一的索引,SQL Server 將添加在內(nèi)部生成的值(稱為唯一值)以使所有重復(fù)鍵
新聞熱點(diǎn)






疑難解答
圖片精選