關于oracle大表分區的一點點心得
2024-08-29 13:39:05
供稿:網友
數據庫大表的優化:采用蔟表(clustered tables)及蔟索引(Clustered Index)
蔟表和蔟索引是Oracle所提供的一種技術,其基本思想是將幾張具有相同數據項、并且經常性一起使用的表通過共享數據塊(data block)的模式存放在一起。各表間的共同字段作為蔟鍵值(cluster key),數據庫在訪問數據時,首先找到蔟鍵值,以此同時獲得若干張表的相關數據。蔟表所能帶來的好處是可以減少I/O和減少存儲空間,其中我更看重前者。采用表分區(partition)
表分區技術是在超大型數據庫(VLDB)中將大表及其索引通過分區(patition)的形式分割為若干較小、可治理的小塊,并且每一分區可進一步劃分為更小的子分區(sub partition)。而這種分區對于應用來說是透明的。通過對表進行分區,可以獲得以下的好處:
1)減少數據損壞的可能性。
2)各分區可以獨立備份和恢復,增強了數據庫的可治理性。
3)可以控制分區在硬盤上的分布,以均衡IO,改善了數據庫的性能。
蔟表與表分區技術的側重點各有不同,前者側重于改進關聯表間查詢的效率,而表分區側重于大表的可治理性及局部查詢的性能。而這兩項對于我的系統來說都是極為重要。由于本人技術限制,目前尚不確定兩者是否可以同時實現,有那位在這方面有經驗的給點指導將不勝感激。
在兩者無法同時實現的情況下,應依照需實現的功能有所取舍。綜合兩種模式的優缺點,我認為采用表分區技術較為適用于我們的應用。
Oracle的表分區有以下幾種類型:
1)范圍分區:將表按某一字段或若干個字段的取值范圍分區。
2)hash分區:將表按某一字段的值均勻地分布到若干個指定的分區。
3)復合分區:結合了前面兩種分區類型的優點,首先通過值范圍將表進行分區,然后以hash模式將數據進一步均勻分配至物理存儲位置。
綜合考慮各項因素,以第三種類型最為優越。(本人實在技術有限僅采用了第1種范圍分區,因為比較簡單,便于治理)
優化的具體步驟:
1.確定需要優化分區的表:
經過對系統數據庫表結構和字段,應用程序的分析,現在確定那些大表需要進行分區:
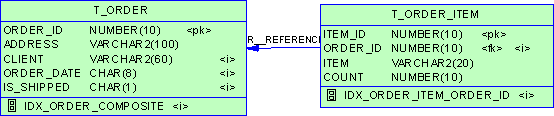
如帳戶交易明細表acct_detail.
2.確定表分區的方法和分區鍵:
分區類型:采用范圍分區。
分 區 鍵:
按trans_date(交易時間)字段進行范圍分區.
3.確定分區鍵的分區范圍,及打算分多少分區:
如:帳戶交易明細表acct_detail.
根據字段(trans_date)分成一下分區:
1).分區1:09/01/2003
2).分區2:10/01/2003
3).分區3:11/01/2003
4).分區4:12/01/2003
5).分區5:01/01/2004
6).分區6:02/01/2004
該表明顯需要在以后增加分區。
4.建立分區表空間和分區索引空間
1).建立表的各個分區的表空間:
1.分區1:crm_detail_200309
CREATE TABLESPACE crm_detail_200309 DATAFILE
‘/u1/oradata/orcl/crm_detail_20030901.dbf’
SIZE 2000M EXTENT MANAGEMENT LOCAL UNIFORM size 16M;
其它月份以后同以上(我在此采用oracle的表空間本地治理的方法)。
2). 建立分區索引表空間
1.分區1:index_detail_200309
CREATE TABLESPACE index_detail_200309 DATAFILE
‘/u3/oradata/orcl/index_detail_20030901.dbf’
SIZE 2000M EXTENT MANAGEMENT LOCAL UNIFORM size 16M;
5.建立基于分區的表:
create table table name
(
........
enable row movment --此語句是能修改行分區鍵值,也就是如不添加該句不能修改記錄的分區鍵值,不能使記錄分區遷移
PARTITION BY RANGE (TRANS_DATE)
(
PARTITION crm_detail_200309 VALUES LESS THAN
(TO_DATE (‘09/01/2003’,’mm/dd/yyyy’
TABLESPACE crm_detail_200309,
其他分區.....
;
6.建立基于分區的索引:
create index index_name on table_name (分區鍵+…)
global --這里是全局分區索引,也可以建本地索引
PARTITION BY RANGE (TRANS_DATE)
(
PARTITION index_detail_200309 VALUES LESS THAN
(TO_DATE ('09/01/2003','mm/dd/yyyy' )
TABLESPACE index_detail_200309,
其他索引分區...
;
對表的分區就這樣完成了,第一次主要確定表分區的分區策約是最重要的,可我覺得對表分區難在以后對表分區的治理上面,因為隨著數據量的增加,表分區必然存在刪除,擴容,增加等。
在這些過程中還牽涉到全局等索引,因為對分區表進行ddl操作為破壞全局索引,故全局索引必須在ddl后要重rebuild.
------------------------簽----名----
$-)
movb $0x88,%ah
int $0x15
movw %ax,(02)
movw $SYSSEG, %ax