有時我們在操作數據時,需要剔除單列數據的重復值,下面小編為大家介紹Excel剔除單列數據的重復值五種方法,滿足大家的日常需求。
方法一:菜單按鈕
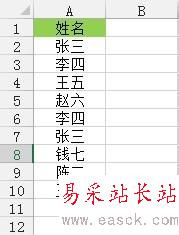
如下圖,是本次操作的源數據。
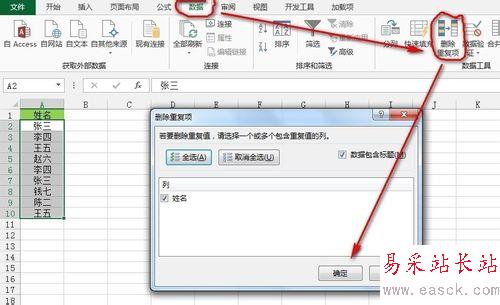
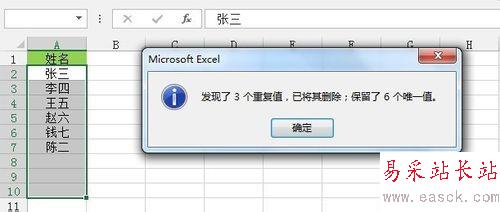
單擊“數據”選項卡--》“數據工具”功能區--》“刪除重復項”,彈出“刪除重復項”對話框,單擊“確定”即可刪除單列數據重復值。如下圖所示:
方法二:數據透視表法
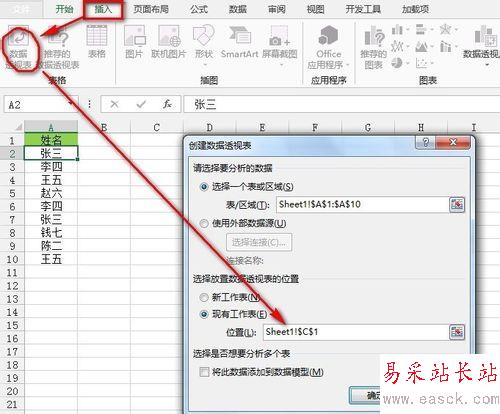
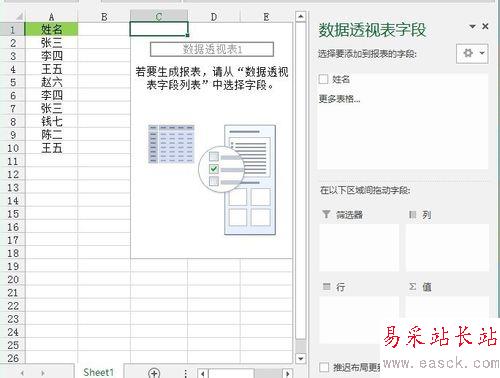
依然使用上面的數據源,單擊“插入”選項卡--》“表格”功能區--》“數據透視表”,出現如下圖的提示框,這里我選擇現有工作表的C1單元格(大家根據需要可以選擇新工作表),單擊“確定”完成數據透視表的創建,如下圖:
接著,勾選“姓名”前面的復選框,“姓名”字段就出現在《行》字段的框框里,如下圖:
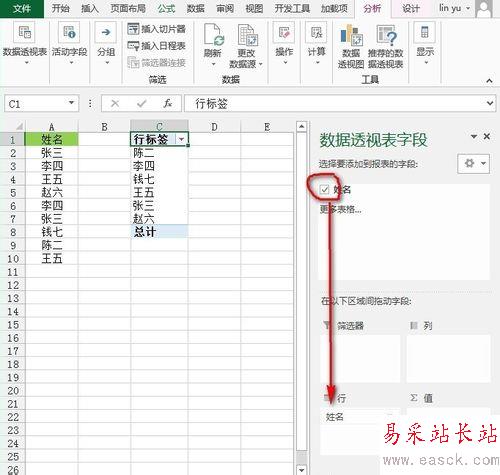
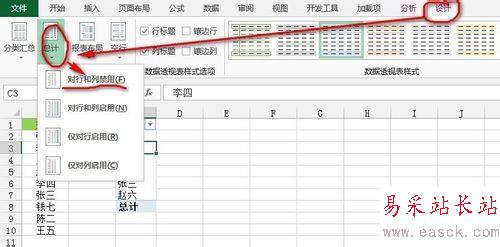
然后,我們對數據透視表的數據進行修飾,單擊“行標簽”所在的單元格,將單元格的文字改成“姓名”,然后單擊數據透視表內的任意單元格,單擊“數據透視表工具”--》“設計”選項卡--》“布局”功能區--》“總計”下的“對行和列禁用”按鈕就完成了,如下圖所示:
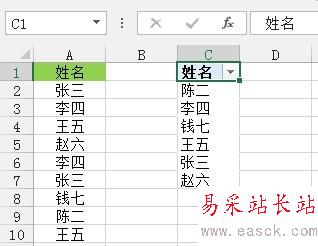
方法三:公式法
如圖,在C1單元格輸入如下公式,然后同時按Ctrl+Shift+Enter三個鍵結束,接著拖動輸入公式單元格右下角的填充柄,完成此次不重復數據的篩選。
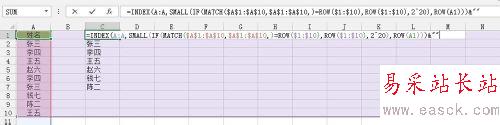
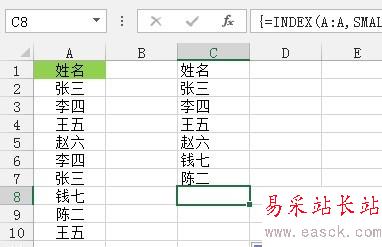
接著我們對公式進行逐步的講解,首先,MATCH($A$1:$A$10,$A$1:$A$10,)=ROW($1:$10)表示查找A1至A10單元格在引用區域$A$1:$A$10的位置是否等于當前單元格行號所在的位置,如果相等,則說明該數據在這個區域中唯一,然后通過IF(MATCH())組合函數返回這個字段的行號,否則返回2^20=1048576,接著用SMALL函數對獲取的行號進行升序排序,最后通過INDEX函數查找行號所在位置的值,&“”主要是為了容錯處理,試想,如果數據都取完了,就剩下1048576的位置了,然后INDEX(A:A,1048576)=0,加個&“”則返回空文本。
新聞熱點






疑難解答