本文實(shí)例講述了mysql 中 replace into 與 insert into on duplicate key update 的用法和不同點(diǎn)。,具體如下:
replace into和insert into on duplicate key update都是為了解決我們平時(shí)的一個(gè)問(wèn)題
就是如果數(shù)據(jù)庫(kù)中存在了該條記錄,就更新記錄中的數(shù)據(jù),沒(méi)有,則添加記錄。
我們創(chuàng)建一個(gè)測(cè)試表test
CREATE TABLE `test` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` varchar(32) DEFAULT '' COMMENT '姓名', `addr` varchar(256) DEFAULT '' COMMENT '地址', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
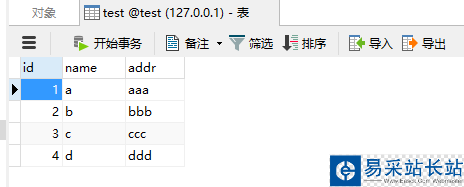
向該表中插入一些數(shù)據(jù)
INSERT INTO testVALUES (NULL, 'a', 'aaa'), (NULL, 'b', 'bbb'), (NULL, 'c', 'ccc'), (NULL, 'd', 'ddd');
影響行數(shù)4,結(jié)果如下:
我們運(yùn)行如下語(yǔ)句:
REPLACE INTO test VALUES(NULL, 'e', 'eee');
結(jié)果顯示,影響行數(shù)1條,記錄被插入成功了
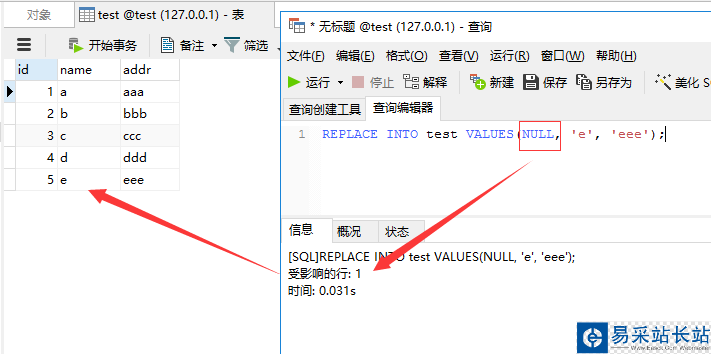
注意上面的語(yǔ)句,我們并沒(méi)有填寫主鍵ID。
然后我們?cè)賵?zhí)行下面的語(yǔ)句:
REPLACE INTO test VALUES(1, 'aa', 'aaaa');
結(jié)果顯示,影響行數(shù)2條,ID為1的記錄被更新成功了
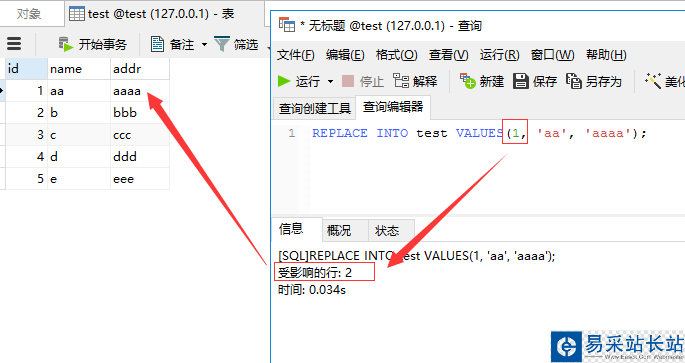
為什么會(huì)出現(xiàn)這種情況,原因就是replace into會(huì)首先嘗試先往表里面插入記錄,因?yàn)槲覀兊腎D是主鍵,不可重復(fù),顯然這條記錄是無(wú)法插入成功的,然后replace into會(huì)把這條已存在的記錄刪掉,然后再插入,所以會(huì)顯示影響行數(shù)是2。
我們?cè)龠\(yùn)行下面這條語(yǔ)句:
REPLACE INTO test(id,name) VALUES(1, 'aaa');
這里我們只指定id,name字段,我們來(lái)看看replace into后addr字段內(nèi)容是否還存在
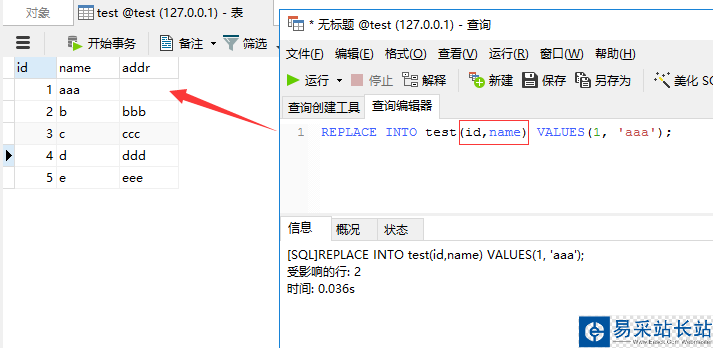
顯然addr字段內(nèi)容沒(méi)有了,跟我們上面的分析是一致的,reaplce into先刪除了id為1的記錄,然后再插入記錄,但我們并沒(méi)有指定addr的值,所以會(huì)如上圖所示那樣。
但是有些時(shí)候我們的需求是,如果記錄存在則更新指定字段的數(shù)據(jù),原有字段數(shù)據(jù)仍保留,而不是上面所示的,addr字段數(shù)據(jù)沒(méi)有了。
這里就需要用到insert into on duplicate key update
執(zhí)行如下語(yǔ)句:
INSERT INTO test (id, name)VALUES(2, 'bb') ON DUPLICATE KEY UPDATE name = VALUES(name);
VALUES(字段名)表示獲取當(dāng)前語(yǔ)句insert的列值,VALUES(name)表示的就是'bb'
結(jié)果顯示,影響行數(shù)2條

如上圖所示,addr字段的值被保留了。
新聞熱點(diǎn)






疑難解答
圖片精選













