原著:fahad gilani
翻譯:yy2better
原文出處:msdn magazine march 2004(c# in-depth)
下載此文章的代碼 scientificc.exe (127kb)
本文假定你熟悉 c#  摘要
摘要
c#語言在多種項目中應(yīng)用的相當(dāng)成功,它們包括 web、數(shù)據(jù)庫、gui及其他更多類型項目。有充分理由認(rèn)為,c# 代碼最前沿的應(yīng)用領(lǐng)域之一很可能是科學(xué)計算。但 c# 能達(dá)到 fortran 和 c++ 應(yīng)用于科學(xué)計算項目的水平嗎?
在本文中,通過研究由 .net 通用語言運(yùn)行時決定的 jit 編譯器、微軟中間語言和垃圾收集器如何影響性能,作者回答了這個問題。他還論述了 c# 數(shù)據(jù)類型,包括數(shù)組和矩陣,及其它在科學(xué)計算 應(yīng)用中起重要作用的語言特性。
c#語言已獲得工作在不同領(lǐng)域開發(fā)者的尊敬并在他們中間得到相當(dāng)?shù)钠占啊W罱鼉赡辏琧# 在交付健壯的產(chǎn)品中起著重要的作用,從桌面應(yīng)用程序到 web 服務(wù),從高階商務(wù)自動化到系統(tǒng)級應(yīng)用程序,從單用戶產(chǎn)品到網(wǎng)絡(luò)分布環(huán)境中的企業(yè)解決方案,都有 c# 的存在。假設(shè)此語言的強(qiáng)大特性,你可能會問 c# 和 microsoft®.net 框架是否能被 更加廣泛地用于除gui和基于web組件之外的程序中。它是否已準(zhǔn)備好被科學(xué)團(tuán)體用于開發(fā)高性能數(shù)字性編碼?
答案并不一目了然,因?yàn)槭紫刃枰卮鹨恍┢渌鼏栴}。例如,什么是科學(xué)性計算(scientific computing)?為什么它不同于傳統(tǒng)的計算?語言是否真的具備適于科學(xué)計算 編程的特性?
本文中,我會揭示 c# 的一些內(nèi)在特性,它們允許開發(fā)者以輕松、實(shí)用的方式使用注重性能(performance-critical)的代碼。你將看到 c# 如何在科學(xué) 社區(qū)中扮演著重要角色,如何為下一代數(shù)字計算敞開大門。你也將看到,盡管謠傳因內(nèi)存管理開銷過大而使受管代碼運(yùn)行緩慢,但是復(fù)雜性適度的代碼運(yùn)行得很快;它根本不會被垃圾收集器中斷,因?yàn)榇蠖鄶?shù)數(shù)字上的處理不會需要足夠多的內(nèi)存釋放而導(dǎo)致調(diào)用垃圾收集。我將探究 c# 在數(shù)字計算世界里是不是一個好的選擇。我還將考察一些基準(zhǔn)(benchmark),并將結(jié)果與非受管 c++ 代碼進(jìn)行比較以便了解在性能和效率方面 c# 處在什么位置。 計算科學(xué)
計算機(jī)的可用性已經(jīng)使科學(xué)家們更容易地證明理論、解答復(fù)雜方程式、模擬3d環(huán)境、預(yù)報天氣和執(zhí)行許多其它高強(qiáng)度運(yùn)算任務(wù)。多年來,數(shù)百種高級語言被研發(fā)出來以促進(jìn)計算機(jī)在這些領(lǐng)域的應(yīng)用(其中 有些是高度專業(yè)的并發(fā)設(shè)計概念框架,例如 ada和 occam;有些是曇花一現(xiàn)的計算機(jī)科學(xué)工具,例如 eiffel 或 algol)。然而,有少數(shù)成為卓越的科學(xué)性編程語言,例如 c、c++ 和 fortran——它們在當(dāng)今科學(xué)計算領(lǐng)域扮演 著主要角色已有相當(dāng)長的一段時間。
但是,如何確定哪種高級語言用于科學(xué)計算呢?一般來說,某種語言要想有資格成為產(chǎn)生科學(xué)計算代碼的平臺,它必須包括的標(biāo)準(zhǔn)之一是提供一套豐富的能被用于衡量性能的工具 ,并且必須允許開發(fā)者輕松有效地表達(dá)問題域。本質(zhì)上,科學(xué)計算語言應(yīng)該能生成可以被細(xì)微調(diào)整的有效的高性能代碼。 性能和語言
性能已經(jīng)成為區(qū)分用于科學(xué)計算編程語言的關(guān)鍵因素之一。編譯器和代碼生成技術(shù)常常被認(rèn)為是性能限制因素,但這種假定不完全正確。例如,使用最廣泛的 c++ 編譯器在代碼生成和優(yōu)化方面做得很好。 有一些微妙之處,它們與代碼的效率比起來,通常就不重要了。例如,c++中應(yīng)避免創(chuàng)建過多臨時對象,尤其它是一種非常容易創(chuàng)建未命名臨時變量但又不使用它們的語言。可以使用表達(dá)式模板達(dá)到此目的,表達(dá)式模板允許延遲數(shù)學(xué)表達(dá)式的實(shí)際運(yùn)算,直到它被賦值。結(jié)果可以避免在運(yùn)行時招致 巨大的抽象懲罰(abstraction penalty)。
這不是說語言特性是影響性能的唯一因素。當(dāng)進(jìn)行語言之間明確的評估以衡量性能和成本時,真正評估的是編譯器編寫者的技巧,而不是語言本身。如果能從語言、運(yùn)行時或平臺中獲取可接 受的性能,那么選擇可能緊緊關(guān)乎個人所好。
如果你已經(jīng)體驗(yàn)過 c# 并且正在考慮進(jìn)行真正的科學(xué)計算,那么沒必要采用其它語言;c# 綽綽有余。 msil和可移植性
與所有其它面向.net的語言一樣,c# 編譯成微軟中間語言(msil),它運(yùn)行于通用語言運(yùn)行時(clr)。clr 可松散地被描述為just-in-time(jit)優(yōu)化編譯器和垃圾收集器 的混合物。c# 公開和利用了clr中的很多功能,所以更細(xì)致地研究該運(yùn)行時的工作機(jī)制是很重要的。
科學(xué)家的關(guān)鍵需求之一是代碼可移植性。科學(xué)研究機(jī)構(gòu)和實(shí)驗(yàn)室擁有許多平臺和機(jī)器,包括基于 unix 工作站和pc。它們常常希望在不同機(jī)器上運(yùn)行代碼,以追求更好的結(jié)果或因?yàn)?某一特定的機(jī)器為他們提供一套數(shù)據(jù)處理和分析工具。然而,達(dá)到完全的硬件透明度已不是一個輕松的任務(wù)而且不總是完全可能。例如,多數(shù)大規(guī)模項目開發(fā)時使用了多種語言混合 的方法;因此,很難保證在一種架構(gòu)或平臺上可運(yùn)行的應(yīng)用程序也能在另一種上運(yùn)行。
clr 使應(yīng)用程序和庫可被多種語言編寫,這些語言都可編譯成 msil。然后msil可運(yùn)行在任何支持它的架構(gòu)上。現(xiàn)在,科學(xué)家就可用 fortran 編寫它們數(shù)學(xué)庫,在c++中調(diào)用它們,使用 c# 和 asp.net 在 internet 發(fā)布結(jié)果。
不像 java 虛擬機(jī)(jvm),clr是一個常規(guī)用途環(huán)境,它被設(shè)計用來面向多種不同的編程語言。此外,clr 提供了數(shù)據(jù)層,不僅僅是應(yīng)用層的互用性并允許在語言間共享資源。
目前,可以獲得大量能輸出 msil 的語言編譯器。這些語言包括(但不限于)ada、c、c++caml、cobol、eiffel、fortran、java、list、logo、mixal、pascal、perl、php、python、scheme 和 smalltalk。另外,system.reflection.emit 名字空間大大降低了開發(fā) 面向 clr 的編譯器的進(jìn)入門檻。
將 clr 移植到不同架構(gòu)是一項正在進(jìn)行的工作。然而,一份開源實(shí)現(xiàn)已由 mono/ximian 開發(fā)出來,并且可獲得 s390、sparc 和 powerpc 架構(gòu) 以及 strongarm 系統(tǒng)的實(shí)現(xiàn)。微軟也發(fā)布了一個運(yùn)行在 freebsd 系統(tǒng)上的開源版本,包括 mac os x。(更多信息請看 msdn 雜志 2002 july 上 jason wittington 的文章 "rotor: shared source cli provides source code for a freebsd implementation of .net")
所有這些進(jìn)展發(fā)生在過去的僅僅數(shù)年中。假以更多時間,很可能一個全功能的 clr 將可以適用于所有通用架構(gòu)。 jit 編譯器是否變得更好?
jit 編譯技術(shù)是一種非凡的技術(shù),它為廣泛的優(yōu)化敞開了大門。 盡管當(dāng)前實(shí)現(xiàn)的實(shí)際情況是:由于時間限制,能被完成的優(yōu)化在數(shù)量上是限制性的,從理論上講,它應(yīng)該比現(xiàn)有的任何靜態(tài)編譯器做得要好。當(dāng)然 ,這是因?yàn)樽⒅匦阅艿拇a的動態(tài)屬性或其上下文直到運(yùn)行時才被充分了解或被驗(yàn)證。jit 編譯器能通過生成更有效代碼來使用這些收集的信息,從理論上講,這些代碼每次運(yùn)行都會被再次優(yōu)化。通常,編譯器為每個方法只發(fā)出一次機(jī)器碼。一旦機(jī)器碼生成,它就以原始機(jī)器速度執(zhí)行。
在科學(xué)計算編程中,這可能是一個便利的工具。科學(xué)性代碼主要由數(shù)字和用數(shù)字表示的算法組成。要在合理的時間內(nèi)完成這些計算,某些硬件資源需要被細(xì)心利用。雖然一些靜態(tài)編譯器在優(yōu)化代碼方面做得很好,但是 jit 編譯器的動態(tài) 本性允許使用眾多技術(shù)優(yōu)化資源利用,譬如基于優(yōu)先級的注冊配置,懶代碼選擇,緩存調(diào)整和特定 cpu 優(yōu)化。這些技術(shù)也為更嚴(yán)格的優(yōu)化提供了廣袤的空間,譬如 強(qiáng)度縮量(strength reduction)和常量繁殖(constant propagation)、冗余 的存儲后加載(load-after-store)、公共子表達(dá)式排除、數(shù)組邊界檢查排除、方法內(nèi)聯(lián)等等。雖然 jit 編譯器有可能實(shí)現(xiàn)這些類型的優(yōu)化,但當(dāng)前.net jit編譯器沒有 先進(jìn)到這一步。
過去,程序員要確保運(yùn)行在某種機(jī)器上的代碼是為底層體系架構(gòu)進(jìn)行過手工優(yōu)化(例如軟件流水線,或手工利用緩存),此乃慣例。在另一臺不同硬件機(jī)器上運(yùn)行同樣的代碼需要修改原始代碼以對應(yīng)新硬件。隨著時間的流逝,處理器執(zhí)行代碼的方式 已經(jīng)有所改變,它們使用專門的內(nèi)置指令或技術(shù)。這些優(yōu)化現(xiàn)在能通過 jit 編譯器發(fā)掘出來,不需要修改現(xiàn)有代碼。結(jié)果,運(yùn)行在工作站上的代碼也可以在具有完全不同 體系架構(gòu)的家庭 pc 上運(yùn)行得一樣好。
.net框架1.1版本發(fā)布的 jit 編譯器相對于它的前輩 1.0 版本有相當(dāng)?shù)母倪M(jìn)。figure 1顯示 clr1.0 和 1.1 版本的執(zhí)行比較,它是通過在兩個平臺上運(yùn)行 scimark2.0 基準(zhǔn)套件得出的。測試機(jī)器配置是 奔騰四 2.4ghz,256兆內(nèi)存。 
figure 1 .net 1.1中 jit 的改進(jìn)
scimark 基準(zhǔn)由許多在科學(xué)計算應(yīng)用中建立的通用計算要素組成,在內(nèi)存訪問浮點(diǎn)運(yùn)算方面各自處理不同的行為模式。這些要素是:快速傅立葉轉(zhuǎn)換(fft)、連續(xù) 松弛迭代(sor:over-relaxation iterations)、用于復(fù)雜線性系統(tǒng)的解決方案的蒙特-卡羅積分、稀疏矩陣乘法和稠密矩陣分解(lu) 。
scimark 最初用 java 開發(fā)(http://math.nist.gov/scimark),后來被 chris re 和 wener vogels 移植到 c#(http://math.nist.gov/scimark)。注意這個實(shí)現(xiàn)沒有使用不安全代碼,這會使它運(yùn)行速度提高 5 至 10 個百分點(diǎn)。
figure 1 以每秒百萬浮點(diǎn)運(yùn)算數(shù)(mflops)顯示了.net框架兩個版本的綜合得分。這給你一個大致的概念:當(dāng)前版本(1.1) 運(yùn)行得如何 以及未來版本改進(jìn)得將有多好。
此圖顯示公共語言運(yùn)行時 1.1 版本勝過 1.0 版本一大截(具體在這里是 54.1 mflops )。版本 1.1 在整個實(shí)現(xiàn)中融進(jìn)了許多性能改進(jìn)技術(shù),包括一些已加入 jit 編譯器中的針對特定架構(gòu) 的優(yōu)化,譬如使用 ia-32 sse2 指令進(jìn)行浮點(diǎn)數(shù)到整數(shù)轉(zhuǎn)換。當(dāng)然,編譯器也對其它處理器生成對應(yīng)的優(yōu)化代碼。
我期待下一次發(fā)布的 jit 編譯器將表現(xiàn)更佳。jit 編譯器將產(chǎn)生比靜態(tài)編譯器更快的運(yùn)行代碼,這只是時間問題。 自動內(nèi)存管理
從實(shí)現(xiàn)角度看,自動內(nèi)存管理大概是 clr 給開發(fā)者最好的禮物。與 c/c++ malloc 或 new 調(diào)用中緩慢且昂貴的鏈表橫斷式釋放相比,crl 的內(nèi)存分配相對較快(堆指針僅僅被移動到下一個空閑槽)。而且,內(nèi)存在運(yùn)行時是自動管理的,例如自動釋放和整理未使用空間。程序師不再需要追蹤指針、過早釋放內(nèi)存塊或根本不釋放它們(雖然像 c# 和 visual c++® 這樣的語言仍賦予開發(fā)者那樣的選擇)。
幾乎可預(yù)見的是,許多開發(fā)者對考慮使用垃圾收集器的反應(yīng)。然而,對于使用內(nèi)存頻繁的應(yīng)用程序,垃圾收集器確實(shí)導(dǎo)致小小的運(yùn)行時成本,它們還處理所有跟蹤內(nèi)存泄漏 的凌亂細(xì)節(jié)以及清除搖擺指針。它們始終保持對堆資源的管理、使其緊湊并可以重復(fù)利用。
最近的研究和試驗(yàn)顯示,在計算密集型應(yīng)用中,對象的分配和釋放更加頻繁,垃圾收集器通過堆壓塑實(shí)際上可以提高性能。另外,內(nèi)存中以不同方式隨機(jī)展開的被頻繁引用的對象被緊湊地收集在一起以 便提供更佳的定位和緩沖利用。這大大加速了整個應(yīng)用程序的性能。同時,垃圾收集器的缺點(diǎn)之一是其不可預(yù)測的時間性,這導(dǎo)致很難使收集工作只在正確的時刻執(zhí)行。這個領(lǐng)域的研究正取得進(jìn)展,垃圾收集器這些年已有改進(jìn)。 屆時,更好的算法會出現(xiàn),從而提供更具確定性的行為。
早先我提及,數(shù)字處理代碼通常不調(diào)用垃圾收集。對一些適度簡單的應(yīng)用來說確實(shí)如此,在這些應(yīng)用程序里,主要涉及數(shù)字,也沒有太多相關(guān)的內(nèi)存分配。這其實(shí)取決于問題的本質(zhì) 以及你已經(jīng)設(shè)計出來的方案。如果它涉及許多生命期為中短期的對象,垃圾收集器將會被相當(dāng)頻繁地調(diào)用。如果只有少數(shù)長生命期對象,并且一直到應(yīng)用程序結(jié)束時才釋放,那么這些對象將被提升 為年長一代,并導(dǎo)致收集調(diào)用顯著減少(如果有的話)。
figure 2 展示了一個沒有調(diào)用垃圾收集器的執(zhí)行矩陣乘法的應(yīng)用程序。我選擇矩陣是因?yàn)樗鼈兪乾F(xiàn)實(shí)世界里許多科學(xué) 計算應(yīng)用程序的核心。矩陣提供了一種實(shí)用方式來解決許多應(yīng)用領(lǐng)域的問題,例如在計算機(jī)圖形算法、計算機(jī) x 線斷層攝影、遺傳學(xué)、密碼學(xué)、電力網(wǎng)和經(jīng)濟(jì)學(xué)領(lǐng)域。
figure 2 代碼定義了一個matrix類,它聲明一個二維數(shù)組用于存儲矩陣數(shù)據(jù)。main方法創(chuàng)建 該類的三個實(shí)例,每個維度都是200×200(每個對象約313kb大小)。這些矩陣每一個引用以傳值方式傳遞到 matmul 方法(引用本身以值方式傳送而不是實(shí)際的對象),然后 matmul 方法執(zhí)行矩陣 a 和 b 的乘法,并存儲結(jié)果到矩陣 c。
為了更加有趣,matmul 方法在一個循環(huán)中被調(diào)用 1000 次。換句話說,我控制著這些對象的重用以有效地執(zhí)行 1000 次“不同”矩陣的乘法運(yùn)算而沒有一次調(diào)用垃圾收集器。通過.net通用語言運(yùn)行時的內(nèi)存性能計數(shù)器, 你可以監(jiān)視收集的次數(shù)。
然而,對于較大型的計算,如果你請求比可用內(nèi)存更多的空間,垃圾收集最終不可避免。這種情形下,你可以二者擇一。例如孤立代碼中性能關(guān)系密切的代碼,將之改為非受管代碼,然后從c#受管代碼中調(diào)用它們。這里一個警告是 p/invoke 或.net interop 調(diào)用會招致小的運(yùn)行時開銷,所以你可能將其作為最后一種選擇,或者如果你確信運(yùn)算的粒度足以能抵消調(diào)用所需的開銷,就采用它。
垃圾收集功能不應(yīng)該阻礙生成高性能科學(xué)計算代碼。其目的是消除你用別的方式不得不面對的內(nèi)存管理問題,只要你明白它的工作原理以及使用它所需的成本,你就不需要擔(dān)心垃圾收集 的開銷。
現(xiàn)在讓我們離開 clr,轉(zhuǎn)到語言本身。正如我早先提及,c#有許多特性使它十分適合于科學(xué)計算。下面讓我們逐一討論這些特性。 面向?qū)ο?
c#是一種面向?qū)ο笳Z言。既然現(xiàn)實(shí)世界是由具有動態(tài)屬性的密切相關(guān)的對象組成,那么面向?qū)ο蟪绦蛟O(shè)計方法常常是科學(xué)計算編程問題的最佳解決方案。 此外,通過替代內(nèi)部代碼片段,結(jié)構(gòu)良好,面向?qū)ο蟮拇a可以更容易被修改以適應(yīng)科學(xué)計算模型的變化。
然而,不是所有科學(xué)計算問題都表現(xiàn)為類似對象的特性或關(guān)系,所以面向?qū)ο蠓椒ㄔ谔幚泶祟悊栴}時會導(dǎo)致不必要的復(fù)雜性。例如,figure 2 中 已有的矩陣乘法代碼沒有使用專門的類——在單個類中聲明三個多維數(shù)組的矩陣。
問題可能涉及對象間復(fù)雜的關(guān)系,而對象的編程則帶來進(jìn)一步的復(fù)雜性或不必要的開銷。以分子動力學(xué)(md)為例,分子動力學(xué)廣泛應(yīng)用于計算化學(xué)、物理學(xué)、生物學(xué)和材料科學(xué)。最早使用計算機(jī) 進(jìn)行科學(xué)計算者之一要追溯到1957年,alder 和 wainwright 模擬了 150 個氬原子的運(yùn)動。在md中,科學(xué)家感興趣的是通過兩個物體間的勢模擬原子間的相互作用,這種 方式類似于行星、太陽、衛(wèi)星和恒星之間受地心引力的影響而產(chǎn)生相互作用一樣。采用面向?qū)ο蠓椒ń蓚€原子間的相互作用可能不是一個壞想法。假設(shè)一個立方體內(nèi)包含n3個原子,n為一個很大的數(shù)字。 能量守恒等式所產(chǎn)生的算術(shù)計算強(qiáng)度是如此之大,以致于借助傳統(tǒng)的程序過程(非面向?qū)ο螅﹣韺?shí)現(xiàn)的話,必須進(jìn)行過程簡化和解決性能問題,也就是說,過程代碼會 變得更復(fù)雜且性能更差。它真正取決于數(shù)據(jù)存儲和所使用的算法。
你可以用 c# 來解決問題。使用語言所具備的強(qiáng)大的面向?qū)ο竽芰赡懿皇亲罴堰x擇,但它為傳統(tǒng)的科學(xué)計算程序員提供了良好的開端。單個類可以包含用于執(zhí)行計算和產(chǎn)生結(jié)果的 所有變量和方法。盡管如此,對于相對較大的問題,由于 oop 提供的模塊化和數(shù)據(jù)完整性,它對科學(xué)計算編程來說是個很有價值的工具,這使代碼擴(kuò)充和重用變得 更容易。 高精度浮點(diǎn)運(yùn)算
沒有哪個科學(xué)計算代碼能忽視精確度和準(zhǔn)確度。即使現(xiàn)今最強(qiáng)大的計算機(jī)也只能運(yùn)算有限位數(shù)精度,具備更高的精度將有助于獲取更準(zhǔn)確結(jié)果。這方面的重要性不能低估,由于計算機(jī)算術(shù)運(yùn)算錯誤而導(dǎo)致的災(zāi)難會讓你清楚地認(rèn)識這一點(diǎn),例如,1996 年著名的 ariane 5號非載人火箭爆炸(其慣性參照系統(tǒng)里一個64位浮點(diǎn)數(shù)被錯誤轉(zhuǎn)換為16位有符號整數(shù)……嘣)。當(dāng)然,你或許不會開發(fā)火箭軟件,但重要的是必須知道在許多科學(xué)計算應(yīng)用程序中高精度的重要性以及為什么如此重要,同時,用于二進(jìn)制浮點(diǎn)算法的 ieee 754 標(biāo)準(zhǔn) 與其說有所幫助,不如說實(shí)際的約束更多些。
c#允許浮點(diǎn)算術(shù)使用更高的硬件平臺支持的精度,譬如 intel 的 80 位雙精度格式。這種擴(kuò)展類型具有比雙精度類型更高精度,它被底層硬件執(zhí)行所有浮點(diǎn)算術(shù)時隱式使用,這樣提供了準(zhǔn)確 的或近似準(zhǔn)確的結(jié)果。下面這段話直接摘錄于 c# 規(guī)格說明書第 4.1章節(jié),以此作為 c# 支持高精度浮點(diǎn)運(yùn)算的例子:
……在形如 x*y/z 的表達(dá)式中,乘法產(chǎn)生超出雙精度取值范圍的結(jié)果,但是接著除法又使臨時結(jié)果回到雙精度取值范圍里,表達(dá)式的事實(shí)上的結(jié)果是在更高精度范圍內(nèi)被求值,所產(chǎn)生的是有窮結(jié)果而不是無窮大。
c#也支持十進(jìn)制類型——128位數(shù)據(jù)類型,適合于金融和貨幣計算。 值類型,或輕量級對象
c#中對象類型主要有兩種——引用類型(重量級對象)和值類型(輕量級對象)。
引用類型總是在堆中分配(除非使用 stackalloc 關(guān)鍵字),并給予一個額外的間接層;也即,它們需要通過對其存儲位置的引用來訪問。既然這些類型不能直接訪問, 某個引用類型的變量總是保存實(shí)際對象的引用(或 null ) 而不是對象本身。假設(shè)引用類型在堆中分配,運(yùn)行時必須確保每個分配請求被正確執(zhí)行。考慮下面代碼,它執(zhí)行一次成功的分配:
matrix m = new matrix(100, 100);其幕后執(zhí)行是:clr內(nèi)存管理器收到分配請求,它會計算存儲該對象包括頭部和類變量所需的內(nèi)存數(shù)量。然后內(nèi)存管理器檢查堆中可用空閑空間,以確認(rèn)是否有足夠空間供這次分配。如果有,對象 所需空間會被成功分配并且對其存儲地址的引用也會被返回。如果沒有足夠空間存儲對象,垃圾收集器將被啟動去釋放一些空間并進(jìn)行堆緊縮操作。
class point{ private double x, y; public point (double x, double y) { this.x = x; this.y = y; }} 這個類的一個實(shí)例占用24字節(jié),其中8字節(jié)用于對象頭,剩余16字節(jié)用于兩個雙精度變量x和y。與此同時,引用類型是包含在值類型對象中的(例如,結(jié)構(gòu)中包含數(shù)組) ,它不會導(dǎo)致整個對象在堆中分配。只有數(shù)組在堆中分配,對該數(shù)組的引用被置于在棧中存放的結(jié)構(gòu)中。 復(fù)數(shù)算術(shù) z = x + yi, where i2 = -1復(fù)數(shù)在科學(xué)計算應(yīng)用中廣泛使用,用于研究物理現(xiàn)象,譬如涉及障礙的電流、波長和液體流動,分析汽車減震器的桁條壓力、移動,發(fā)電機(jī)和電動機(jī)的設(shè)計,建模中大矩陣的的處理。它們形成這個宇宙中幾乎任何事的基本等式,所以將復(fù)數(shù)視作編程語言中 單獨(dú)一種數(shù)據(jù)類型對于許多科學(xué)計算應(yīng)用來說是至關(guān)重要的。
c3 = c1 * c2 + 5 * (c1-13)如果此表達(dá)式以方法調(diào)用形式編寫,你會得到類似下行代碼:
complex c3 = c1.multiply(c2).add((c1.minus(13)).multiply忘記其中任何一處的括號,你將陷入在屏幕上查找編譯錯誤。想象一下編寫一個比上面表達(dá)式更復(fù)雜的數(shù)字表達(dá)式將會怎樣。或者想象一段時間后重新回到你的代碼,并打算在一個嵌套 了無數(shù)個add和multiply方法名的表達(dá)式中將“add”方法名改為“multiply”。首先你必須理解代碼是做什么的,然后,如果幸運(yùn)的話,經(jīng)過多次不成功的修改嘗試后你終于得到正確結(jié)果。運(yùn)算符重載允許你以自然、合乎邏輯 的方式來表示數(shù)字表達(dá)式。
多維數(shù)組 
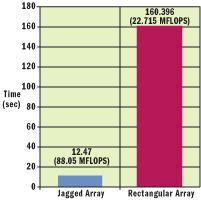
double[] myarray = new double[row_dim * column_dim];要索引這個數(shù)組的元素,使用下列偏移:
myarray[row * column_dim + column];這勿庸置疑比等價的不規(guī)則或矩形數(shù)組快。
不安全方法 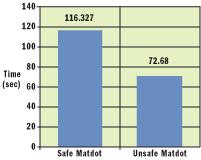 語言互用性 基準(zhǔn)測試(benchmarks)
語言互用性 基準(zhǔn)測試(benchmarks) 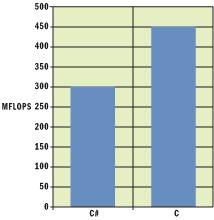
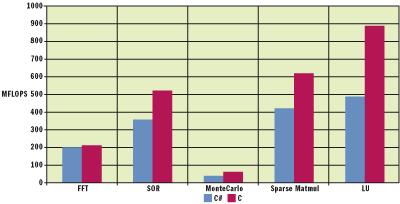 結(jié)束語
結(jié)束語 新聞熱點(diǎn)






疑難解答
圖片精選













