hibernate synchronizer
迄今為止,在我找到的插件中,hibernate synchronizer最令我感興趣,因為看起來它對以映射為中心的工作流提供了最好的支持,而我的developer's notebook一書中就采用了這種工作流。(hibernate可以用于多種用途,所以請查看可用的其他插件,如果您的環境需要其他方法,這些插件將更有幫助。)事實上,hibernate synchronizer插件讓您在修改映射文檔時,無需考慮更新java代碼,它會在您進行編輯的時候以一種非常類似于eclipse的方式自動更新java代碼。通過為每個被映射的對象創建一對類,它比hibernate的內置代碼生成工具更為先進。它“擁有”一個基類,當您修改映射時,它可以隨意重寫這個基類。它還提供一個擴展了這個基類的子類,可以在這個子類中加入業務邏輯和其他代碼,而無需擔心它會在您眼皮底下消失。
因為要適用于以hibernate映射文檔為中心的方法,hibernate synchronizer還包括一個用于eclipse的新編輯器組件,為此類文檔提供智能輔助和代碼自動完成功能。優秀的dtd驅動的xml編輯器(比如前面提到過的xmlbuddy)可以實現其中的一些功能,但是hibernate synchronizer利用對文檔語義的理解做得更好。它還提供了一個映射中的屬性和關系的圖形化視圖、創建新元素的“向導”界面,以及其他類似的優點。而且如前所述,在其默認配置中,編輯器會在用戶編輯映射文檔時自動重新生成數據訪問類。
hibernate synchronizer還有其他的功能。它在eclipse的new菜單中加入了一個區域,為創建hibernate配置和映射文件提供向導,并在包的資源管理器和其他適當的位置中添加了上下文菜單項,使用戶可以輕松訪問相關的hibernate操作。
好了,現在已經有了足夠多的抽象描述,是時候開始實踐了!畢竟,您很可能對此產生了興趣,要不您就不會閱讀本文。那么,如何安裝與使用hibernate synchronizer呢?
安裝啟動eclipse,選擇help -> software updates -> update manager,便可以打開update manager。install/update透視圖打開之后,在feature updates視圖中右擊(或者控件單擊(control-click),如果您使用的是單按鈕鼠標),選擇new -> site bookmark,如圖1所示。
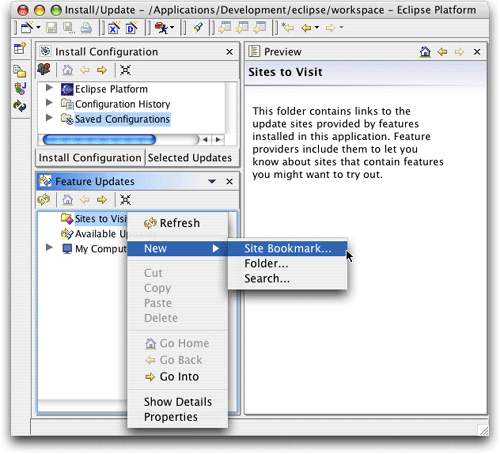
圖1. 向update manager添加hibernate synchronizer插件站點
在出現的對話框中,輸入所需插件版本的url。輸入的url取決于您的eclipse版本:
還需為新的書簽指定一個名稱,“hibernate synchronizer”就很好。圖2顯示的對話框包括了我的eclipse 2.1.2環境中的所有必需信息。
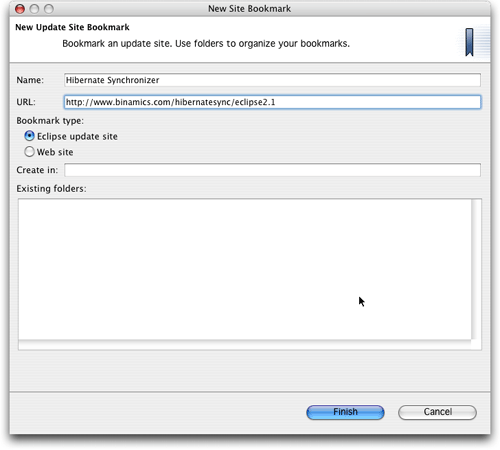
圖2. hibernate synchronizer插件更新站點的書簽
單擊finish之后,新的書簽將出現在feature updates視圖中,如圖3所示。
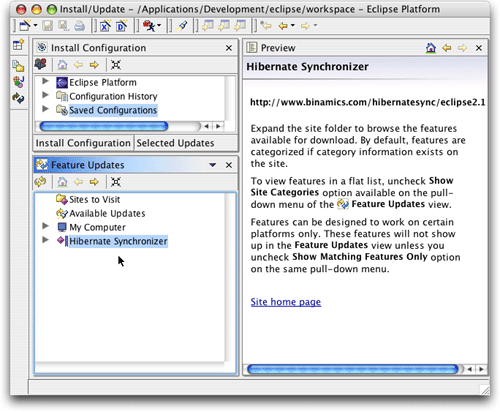
圖3. hibernate synchronizer站點現在可用了
為了實際安裝插件,單擊書簽左側的三角形展開符號,然后單擊其中的下一個三角形展開符號,重復這個過程,直到出現插件的圖標為止。單擊該圖標,preview視圖就會更新,從而顯示一個允許安裝插件的界面,如圖4所示。
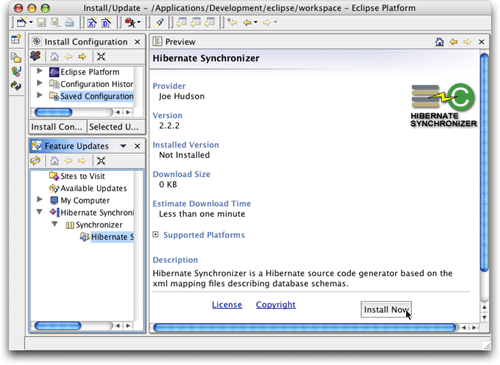
圖4. 準備安裝插件
單擊install now,實際安裝插件,讓eclipse引領您完成整個過程(圖5-10)。
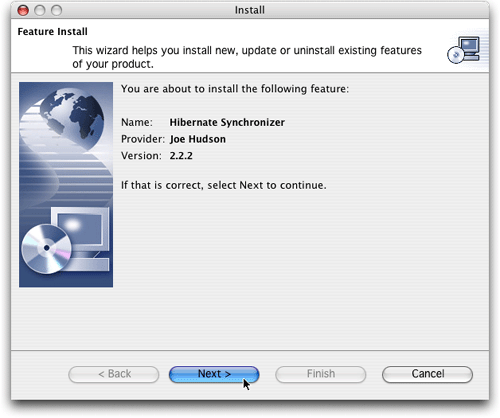
圖5.安裝hibernate synchronizer
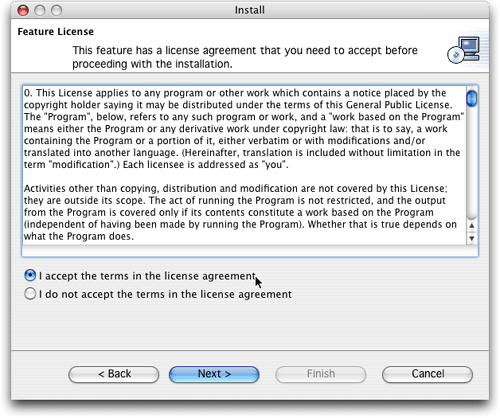
圖6. 插件許可證協議
可參見下面的權衡部分,其中有關于許可證協議的一些討論。在決定在自己的項目中使用hibernate synchronizer之前,您可能想仔細閱讀一下它。我認為這是很好的做法,但是令人困惑的是,它基于gpl,實際上并非是開源的。
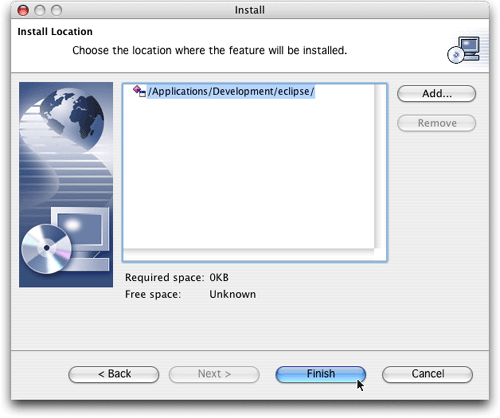
圖7. 選擇安裝插件的位置,使用默認的就可以
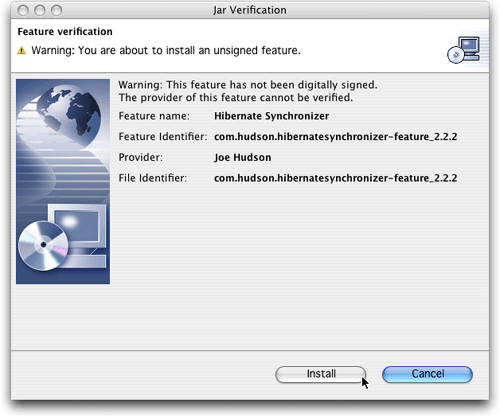
圖8.對沒有簽名的插件發出的標準警告
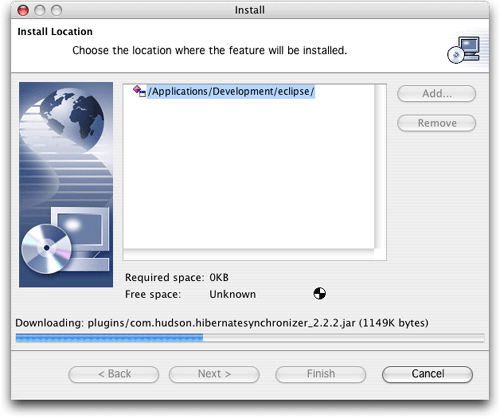
圖9.正在安裝
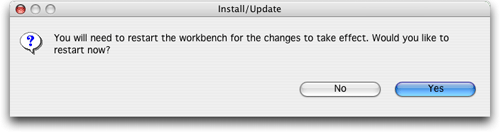
圖10.安裝完畢
現在插件已經安裝完畢,需要退出并重新運行eclipse,以便使其生效。出現的對話框似乎暗示eclipse將自動重啟,但是根據我的經驗,單擊yes只會退出環境,必須手動重啟。這可能是eclipse 2.1的mac os x實現的一個局限性;eclipse 3將成為首個承諾對os x提供一流支持的版本。不管怎么說,這是一個小問題。如果需要重啟eclipse,現在就重啟吧,因為應該開始配置插件了!
配置
eclipse重新啟動之后,可以關閉install/update透視圖。打開一個使用hibernate的java項目。如果您讀過developer's notebook一書中的例子,那么有幾個目錄可供選擇。我將選用第3章中的例子,因為這一章是可以在線閱讀的樣章。您還可以從該書的站點下載所有例子的源代碼。
如果您準備創建一個新的eclipse項目,以便使用示例源代碼目錄中的一個,只需選擇file -> new -> project。選擇創建一個java項目,然后單擊next,為其命名(我使用的是“hibernate ch3”,如圖11所示),取消對use default復選框的選擇,以便可以告訴eclipse現有項目目錄的位置,然后單擊browse按鈕,定位它在驅動器上的具體位置。現在可以單擊finish,創建該項目,但是我一般喜歡單擊next,然后再次檢查eclipse的選擇。(當然,如果有什么出錯,您始終可以返回并修改項目屬性,但是我發現,如果存在庫丟失之類的錯誤,馬上就會面對大量的錯誤和警告,這實在是一件麻煩的事情。)
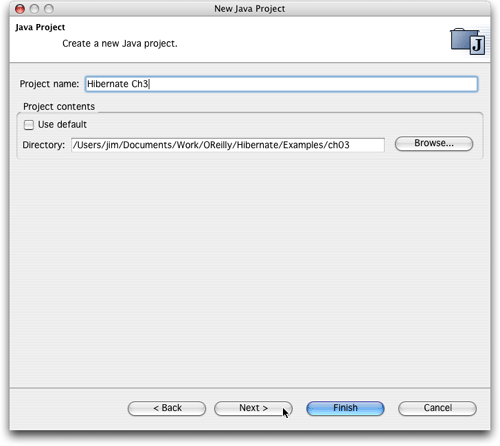
圖11. 創建一個使用hibernate的新項目
此處我的警告是多余的。eclipse清楚目錄的架構及用法,還找出了我曾下載和安裝過的所有第三方庫,以便讓hibernate和hsqldb數據庫引擎能夠運行。這種智能適應性是eclipse的重要特性之一。圖12顯示我們的新項目已經打開并準備好用于實驗了。它還顯示,eclipse不喜歡把窗口縮到足夠小以適應適當的屏幕快照。從現在起,我只能捕捉窗口的一部分。
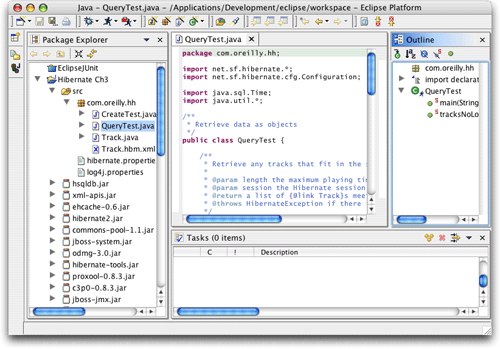
圖12. 第3章中的示例項目
接下來要創建一個hibernate synchronizer可以使用的hibernate配置文件。src目錄中已經存在一個hibernate.properties文件,它說明了書中例子的配置,但是hibernate synchronizer只能使用hibernate的基于xml的配置方法。所以,我們需要把hibernate.properties文件的內容復制到一個新的hibernate.cfg.xml文件中去。從好的方面來說,這使我們可以見識hibernate synchronizer的一項特性,即配置文件向導。選擇file -> new -> other,單擊新可用的hibernate類別,選中hibernate configuration file,然后單擊next。
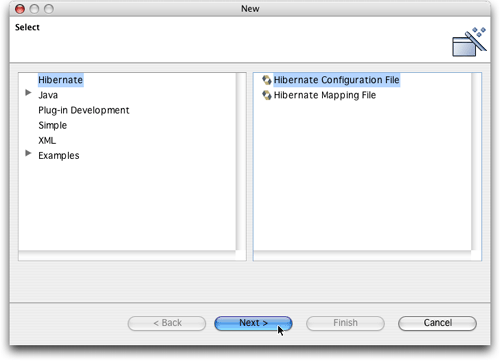
圖13. 啟動hibernate configuration file向導
當向導啟動后,它所提供的用于放置文件的目錄取決于當前在eclipse中選中的文件。出于一致性方面的考慮,一定要把它和properties版本一起放在頂級的src目錄中。填入向導所需的其余信息,匹配配置的properties版本,如圖14所示。注意,與使用ant控制hibernate的執行(這是developer's notebook一書中所使用的方法)不同,當調用hibernate時,我們無法控制當前的工作目錄,所以需要在url中使用一條到數據庫文件的完全限定路徑。我使用的值是(有點難看):jdbc:hsqldb:/users/jim/documents/work/oreilly/hibernate/examples/ch03/data/music。(如果有人能告訴我如何讓eclipse或hibernate synchironizer對一個項目使用特定的工作目錄,我肯定會很感興趣。我在eclipse方面還是一個新手,所以如果知道這種情況是可能的,只是我不知道如何去做,我肯定不會感到吃驚。)
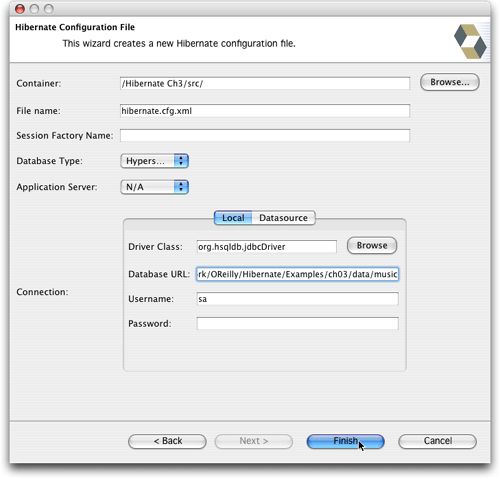
圖14. 填寫配置文件的詳細信息
填寫driver class時有一點奇怪:需要單擊browse按鈕,并開始輸入驅動程序的類名。如果輸入“jdbcd”,窗口將只會給出兩個選擇,很容易就可以找出正確的選擇,如圖15所示。
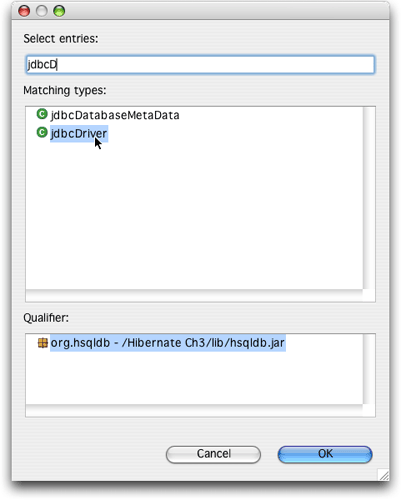
圖15. 指定hsqldb驅動程序類
按照圖14所示設置適用于您自己的安裝的值之后,就可以單擊finish來創建配置文件。hibernate synchronizer現在已經可以使用了。它打開了創建的文件,所以可以看到一個hibernate的xml配置文件的結構和詳細信息。
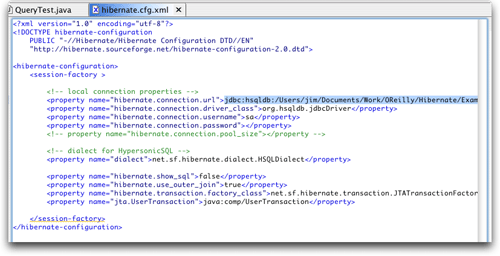
圖16. 生成的配置文件
一種快速測試該配置是否生效的方式是使用其他的向導界面。選擇file -> new -> other,單擊新可用的hibernate類別,選中hibernate mapping file,然后單擊next。當向導出現時,它應該填充了剛才輸入的所有設置信息,可以單擊refresh按鈕來確定它可以與數據庫通信,它還會顯示找到了一個track表。第一次這樣做的時候,由于某種原因,您可能必須確認包含hsqldb驅動程序的.jar文件的位置,但是這種情況只會發生一次。不管怎樣,確認了一切正常之后,單擊cancel,而不是實際創建映射,因為我們想使用手動創建的已有映射文件。
生成代碼
這很可能是您一直期待的部分。我們可以做些什么特別的呢?馬上就有一個可用于hibernate映射文檔的新上下文菜單項。
如果右擊(或控制單擊)任意一項,將會看到很多與hibernate相關的選項(圖17),其中包括一個同步選項。這是一種手動讓hibernate synchronizer生成與映射文檔相關的數據訪問對象的方式。
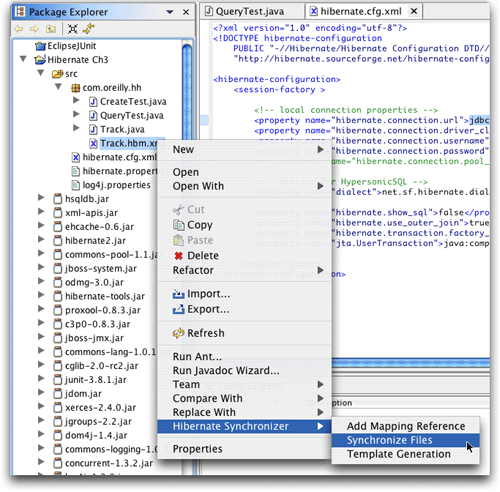
圖17.映射文檔的同步選項
add mapping reference選項也很有用:它在主hibernate配置文件中添加了一項,告知有關該映射文檔的信息,所以無需在源代碼中加入任何內容來要求配置相應的映射。現在我們來看看選擇synchronize files的結果。
到這里事情開始變得有趣了。出現了兩個新的子包,一個用于hibernate synchronizer“擁有的”“基”數據訪問對象,可以在任何時候進行改寫,而另一個用于為這些dao生成子類的業務對象,它不會被重寫,這為我們提供了一個向數據類添加業務邏輯的機會(如圖18所示)。
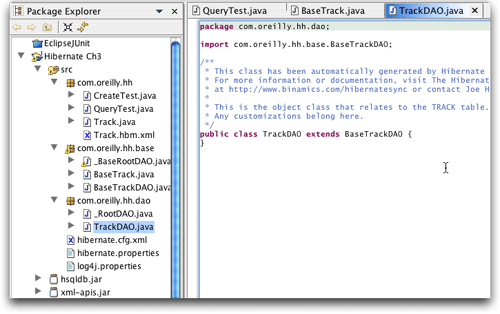
圖18. 經過同步的數據訪問對象,顯示了可編輯的子類
這樣生成的類比使用常規的hibernate代碼生成工具生成的類要多很多,這有一些優點以及一些潛在的缺點,在稍后的權衡部分中我們將討論這些。還要注意,可以在項目的屬性配置中選擇生成其中的哪些類,以及生成它們的包結構。我本來應該演示一下的,但是當前的插件版本有一個bug,它阻止了在mac os x上對這個配置界面進行訪問。補丁已經開發出來了,但尚未發布。
基于hibernate synchronizer頁面上的例子與下面的類,我試圖使用這些新的數據訪問對象插入一些數據到音樂數據庫中。這十分類似于使用標準hibernate代碼生成器的版本(在hibernate: a developer's notebook一書的39-40頁),甚至更為簡單,因為hibernate synchronizer生成的類針對每項數據庫操作都創建并提交了一個新事務,所以在像這樣簡單的場境中,您不需要編寫代碼來設置事務。(當然了,要讓一組操作作為單個事務運行,有很多種方法。)下面是新版本的代碼:
package com.oreilly.hh;import java.sql.time;import java.util.date;import net.sf.hibernate.hibernateexception;import com.oreilly.hh.dao.trackdao;import com.oreilly.hh.dao._rootdao;/** * try creating some data using the hibernate synchronizer approach. */public class createtest2 { public static void main(string[] args) throws hibernateexception { // load the configuration file _rootdao.initialize(); // create some sample data trackdao dao = new trackdao(); track track = new track("russian trance", "vol2/album610/track02.mp3", time.valueof("00:03:30"), new date(), (short)0); dao.save(track); track = new track("video killed the radio star", "vol2/album611/track12.mp3", time.valueof("00:03:49"), new date(), (short)0); dao.save(track); // we don't even need a track variable, of course: dao.save(new track("gravity's angel", "/vol2/album175/track03.mp3", time.valueof("00:06:06"), new date(), (short)0)); }}當我編寫這些代碼時,可以使用eclipse是一件十分愜意的事情。我已經忘了當我為書籍編寫例子時,我多么希望可以使用智能代碼完成功能,而且jdt在其他方面也同樣能幫上忙。
為了在eclipse中運行這個簡單的程序,我們需要設置一個新的run配置。選擇run -> run...,把createtest2.java作為當前的活動編輯器文件。單擊new,eclipse就會知道我們想要在當前項目中運行這個類,因為我們使用main()方法創建它。它指定的默認名稱是createtest2。界面應該如圖19所示。單擊run,試著創建一些數據。
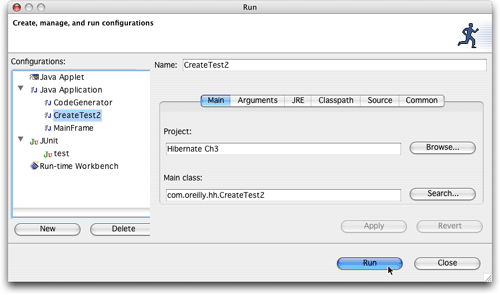
圖19.準備好在eclipse中運行我們的創建測試
如果您確實遵照了這些步驟,您就會發現執行時首次嘗試將會失敗:hibernate抱怨說配置文件沒有包含映射引用,而按要求至少要有一個。啊哈!所以,這就是圖16底部xmlbuddy出現黃色下劃線警告的原因。我們可以很容易地解決這個問題,具體方法是在package explorer視圖中的track.hbm.xml映射文檔上右擊,然后在新的hibernate synchronizer子菜單中選擇add mapping reference。這對xmlbuddy來說是正確的做法,可以讓運行繼續。遺憾的是,運行沒有繼續多久。下一個錯誤是無法在jndi中找到jta usertransaction初始上下文。顯然我并非惟一遇到這種問題的人,在一個論壇主題中相關的討論如火如荼,但是還沒有人找到解決方案。
因為知道我不需要使用jta,所以我想知道為什么hibernate要嘗試找到jta。我打開了hibernate配置文件(圖16),然后尋找hibernate synchronizer中的任何可疑之處。無疑有幾行是最有嫌疑的:
<property name="hibernate.transaction.factory_class"> net.sf.hibernate.transaction.jtatransactionfactory </property> <property name="jta.usertransaction"> java:comp/usertransaction </property>
我試著把上述內容注釋掉并再次運行,這第三次運行成功了。運行沒有出現錯誤,我的數據出現在數據庫中。哇!運行可以信賴的antdb目標(developer's notebook一書的第1章中對此有說明)便可以看到所有數據(確實很簡單),如圖20所示。如果您要這樣做,要確保從一個antschema開始創建數據庫模式,或者清空來自前面實驗中的任何測試數據。
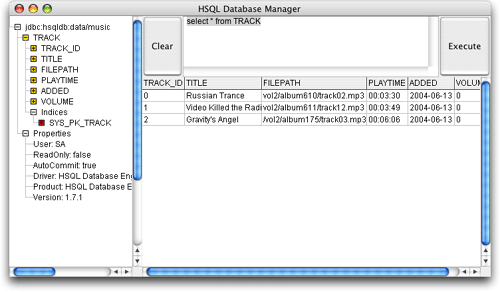
圖20.測試程序所創建的數據
注意,可以在eclipse中運行ant目標,具體方法是右擊(或控制單擊)package explorer中的build.xml文件,選擇run an,然后使用eclipse對話框選擇目標。酷吧?
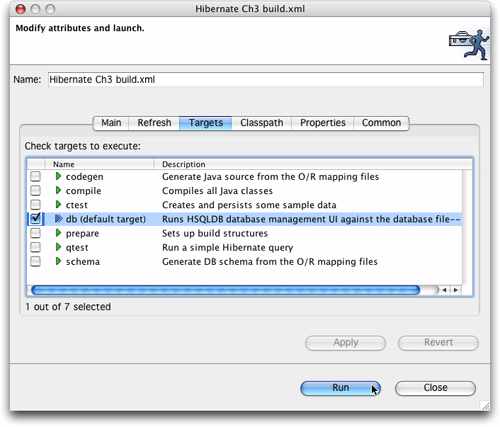
圖21.在eclipse中運行ant
使用查詢取回數據相當簡單,盡管這次的代碼很接近于常規的使用hibernate生成的普通數據訪問類所使用的代碼。即使hibernate synchronizer為處理指定查詢生成了大量幫助器方法,我還是認為它們中間沒有哪一個方法特別有用,因為它們都堅持運行查詢后返回結果列表,而不是提供可以直接使用的query對象。這使您無法使用query的方便的類型安全的參數設置方法。因為這一點,我決定一定要讓rootdao對象為我提供一個hibernate session,以便使用老式的方法。我認為我可以編輯hibernate synchronizer使用的任何模板來生成我想要的任何方法,如果我要使用它來開發一個項目,我幾乎肯定我會這么做。
實際上,進一步考慮的話,因為當獲得一個活動的session時,您只能處理query,dao所提供的方法已經達到了最佳效果。如果您想像我在這個例子中所做的那樣處理查詢,您必須總是自己進行會話管理。可以把會話管理嵌入到“您自己的”那一半dao所提供的業務邏輯中,這就可以同時利用兩方面的好處了。這正是hibernate synchronizer提供的拆分類模型如此有用的另一個原因。我將在下面對此進行深入探討。
不管怎樣,下面是我第一次想出的代碼,基本上等同于書中48-49頁上給出的代碼:
package com.oreilly.hh;import java.sql.time;import java.util.listiterator;import net.sf.hibernate.hibernateexception;import net.sf.hibernate.query;import net.sf.hibernate.session;import com.oreilly.hh.dao.trackdao;import com.oreilly.hh.dao._rootdao;/** * use hibernate synchronizer's daos to run a query */public class querytest3 { public static void main(string[] args) throws hibernateexception { // load the configuration file and get a session _rootdao.initialize(); session session = _rootdao.createsession(); try { // print the tracks that will fit in five minutes query query = session.getnamedquery( trackdao.query_com_oreilly_hh_tracks_no_longer_than); query.settime("length", time.valueof("00:05:00")); for (listiterator iter = query.list().listiterator() ; iter.hasnext() ; ) { track atrack = (track)iter.next(); system.out.println("track: /"" + atrack.gettitle() + "/", " + atrack.getplaytime()); } } finally { // no matter what, close the session session.close(); } }}trackdao提供的一個優秀特性是靜態常量,通過它,我們可以請求指定查詢,消除任何由于字符串輸入錯誤而引起運行時錯誤的可能性。我喜歡這一點!為這個測試類設置和執行run配置,將會生成預期的輸出,如圖22所示。
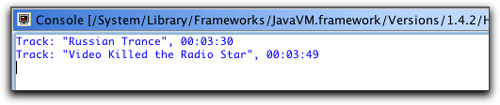
圖22. eclipse控制臺視圖中的查詢結果
我前面提到過,運行這個類之后,我意識到,借助于hibernate synchronizer所提供的模型,可以用一種更好的方法來實現它。因為指定查詢是與該數據訪問對象相關的映射文件的一項特性,所以如果我們將查詢放入trackdao對象中(這才是它真正屬于的地方),那么這個對象看起來應該是下面這個樣子:
package com.oreilly.hh.dao;import java.sql.time;import java.util.list;import net.sf.hibernate.hibernateexception;import net.sf.hibernate.query;import net.sf.hibernate.session;import com.oreilly.hh.base.basetrackdao;/** * this class has been automatically generated by hibernate synchronizer. * for more information or documentation, visit the hibernate synchronizer page * at http://www.binamics.com/hibernatesync or contact joe hudson at [email protected] * * this is the object class that relates to the track table. * any customizations belong here. */public class trackdao extends basetrackdao { // return the tracks that fit within a particular length of time public static list gettracksnolongerthan(time time) throws hibernateexception { session session = _rootdao.createsession(); try { // print the tracks that will fit in five minutes query query = session.getnamedquery( query_com_oreilly_hh_tracks_no_longer_than); query.settime("length", time); return query.list(); } finally { // no matter what, close the session session.close(); } }}這樣做更好更清晰,還進一步簡化了querytest3中的main()方法:
public static void main(string[] args) throws hibernateexception { // load the configuration file and get a session _rootdao.initialize(); // print the tracks that fit in five minutes list tracks = trackdao.gettracksnolongerthan(time.valueof("00:05:00")); for (listiterator iter = tracks.listiterator() ; iter.hasnext() ; ) { track atrack = (track)iter.next(); system.out.println("track: /"" + atrack.gettitle() + "/", " + atrack.getplaytime()); } }顯然,這是一種在使用hibernate synchronizer時處理指定查詢的方法。做一次快速測試就可以確認它生成同樣的輸出,而且它的代碼也要好很多。
您是否想使用hibernate synchronizer來生成它自己的數據訪問對象類型暫且放下,我們還有最后一項重要特性要探討。
編輯映射
hibernate synchronizer的一個主要吸引力就在于它為映射文檔提供的專業化的編輯器。可以配置這個編輯器,以便只要保存文件就自動重新生成相關數據對象,但是這只是一個錦上添花的功能;即使不打算使用該插件的代碼生成器,您也可能希望使用這個編輯器。它為您提供映射文檔元素的智能完成功能,以及一個圖形化的大綱視圖,可以在這個視圖中操縱這些元素。
但是,如果從developer's notebook一書中的下載源代碼開始,就至少得有一項技巧才可以讓編輯器工作。在下載的文件中,映射文檔的擴展名為“.hbm.xml”,而只有以“.hbm”結尾的文件才能調用編輯器。理論上,可以在eclipse中配置擴展名映射,以便使具有這兩種擴展名的文件都能使用插件的映射文檔編輯器,但是我無法使其生效,而且我注意到支持論壇上有人面臨著與我相同的問題。所以,至少目前最好的做法就是重命名文件。(如果您堅持使用基于ant的標準代碼生成,請確保更新build.xml中的codegen目標以使用新的擴展名。)
在我把track.hbm.xml重命名為track.hbm之后,它在package explorer中的圖標就更新為hibernate徽標,而默認的編輯器則變為插件的編輯器,如圖23所示。由于某種原因,其他的hibernate synchronizer選項(如圖17所示)對于其中任意一種擴展名都是可用的,但是編輯器只對較短的版本可用。
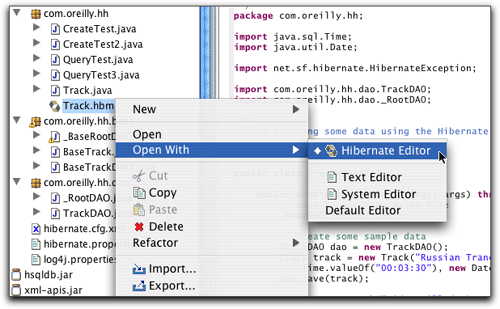
圖23. hibernate映射文檔(擴展名為“.hbm”)的上下文菜單
編輯器為映射文檔中添加的所有元素都提供上下文相關的自動完成支持。圖24顯示了一些例子,但是屏幕截圖無法真正捕捉到該特性的深度和有效性。我強烈建議您安裝插件并使用它。您很快就會看到它在處理映射文檔方面是多么有用。
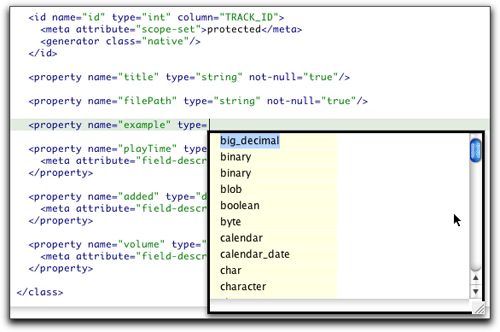

圖24和25.映射文檔編輯器中的完成輔助功能
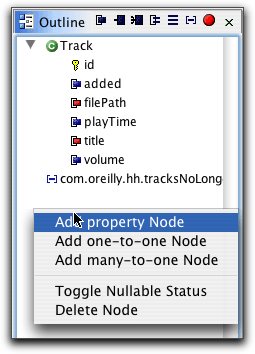
如圖26所示,大綱視圖提供了一個關于類層次結構、被映射的元素、指定查詢以及映射文檔中的各種元素的圖形化視圖,還提供一個菜單,其中有一些向導可以幫助創建新的屬性。
| |
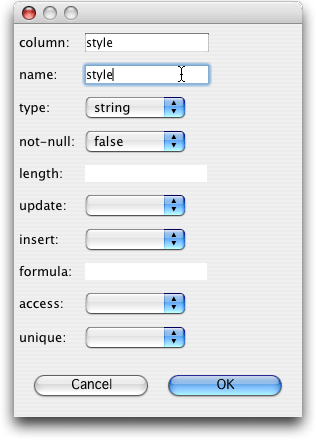
圖26和27. 映射編輯器的大綱視圖和“add property”向導
編輯器中的上下文菜單還提供一個format source code選項,可以使用它來整理和重新構造文檔。這個編輯器中已經有了很多靈巧和有用的特性,看它們如何發展也是一件有趣的事情。惟一使我感到不滿的是(并不是什么大問題),當完成xml屬性時,這個編輯器用來幫助管理引號的方法與jdt在java代碼中使用的方法完全不同。在它們之間來回切換會把人弄迷糊。(您需要一些時間適應jdt的工作方式,但是一旦您開始信任它,它就會變得魔力無窮。)
生成數據庫模式
盡管我的第一印象是所有內容都來自映射文檔,但是hibernate synchronizer目前不支持從映射文檔創建或更新數據庫模式。支持論壇上已經提出了相關的請求,所以如果將來看到這些特性,我肯定不會吃驚,因為提供這類支持并不很困難。目前來說,如果要從映射文檔開發數據庫,就必須使用像hibernate: a developer's notebook書中這種ant驅動之類的方法。此外,下面描述的hibernator插件支持在eclipse中進行模式更新。我可能要研究一下是否可以同時安裝這兩種插件。
我希望本文能夠讓您清楚地了解該插件所提供的功能。無論如何,我沒有涵蓋它的所有功能,所以如果您有興趣,可以去下載它然后自己進行探索。
權衡
毫無疑問,可以使用hibernate synchronizer來完成一些靈巧的工作。是否要在我自己的hibernate項目中使用它呢?這樣做有優點也有缺點,很可能直到實際采用hibernate來代替我們正在使用的自己開發的(且過分簡單的)輕量級o/r工具時,我才會做出決定。這是一次意義相當重大的改動,而我們把這次改動推遲到了由于其他原因進行架構變換的時候。下面是對我的決定起著重要作用的一些因素。
正如我們在安裝小節中所談到的那樣,在許可證方面還存在著一點問題。插件的論壇中有此方面的討論。當前的許可證基于對gnu gpl的定制修改,這次修改刪除了所有源代碼共享方面的條款,但是試圖保留“copyleft”保護的其他方面。關于這樣做的合法性仍然存在一些問題,而作者正在尋求另一種解決辦法。很清楚,目的是要保護插件,而不是阻止其他任何項目使用該插件生成代碼,但是有必要仔細閱讀當前的許可證,看一看其目的是否已經達到,或者您是否仍然冒著很大的風險。
同一討論表明,作者原來是以開源的形式發布插件的,但是又臨時收回了這一決定,因為他覺得它還不夠完美以用作一個優秀的范例。接著,他與一些莽撞的人通過一些非常不愉快的郵件,這使他不愿再共享源代碼。當然,他有權決定是否與我們共享源代碼。該插件對于整個世界來說是一份大禮,而作者并不欠我們什么。但是我希望他能與其他用戶進行足夠的正面交流,這樣就能堅定他原來共享源代碼的想法。我真的認為能夠看到我使用的工具的源代碼是一件很有價值的事情,不僅因為這是一個很好的學習機會,還因為這意味著,如果需要的話我可以立刻修復一些小問題。作者在解決用戶的問題方面始終很熱心,響應也很快,但是一個人無法維持一個社區,因為我們都有繁忙、筋疲力盡和心煩意亂的時候。
hibernate synchronizer使用它自己的模板和機制來生成數據訪問類,這既有優點也有缺點。優點是可以獲得比hibernate的“標準”代碼生成工具更多的功能。可以使用數據對象的一個自動生成的子類,并在該數據對象中嵌入業務邏輯,而無需擔心重新生成訪問代碼時這些業務邏輯會被改寫,這也是一個不錯的特性。插件生成的使很多簡單的場景更簡單的類還提供了其他的優點。
另一方面,這還意味著,當hibernate平臺增加一些新的特性或者做了改動之后,hibernate synchronizer生成的代碼就有些滯后于hibernate了。在對hibernate不常使用的模式的支持方面,插件代碼也存在bug:它的用戶群很小,一個人就可以讓它保持更新。您可以在討論論壇上找到這種現象的證據。
和很多事情一樣,潛在的優點是否超過風險要由您來決定。即使不使用代碼生成器,您也會發現映射編輯器非常有用。如果您只想使用編輯器的自動完成和輔助功能,可以關掉自動同步選項。
如果您使用過該插件,并且發現它很有用,我建議您聯系其作者,表達您的謝意,并考慮捐出一些資金來幫助支持它的未來發展。
其他插件
迄今為止,我還找到了另外兩個也提供eclipse中的hibernate支持的插件。(如果您還知道有其他的插件,或者將來遇到了這樣的插件,我很愿意知道它們。)或許將來我還會撰寫有關這些插件的文章。
hiberclipse
hiberclipse插件看起來也是一種非常有用的工具。它似乎適用于數據庫驅動的工作流,在這個工作流中,已經有了一個數據庫模式,而您想構建一個hibernate映射文件和java類來使用該模式。這是一種很常見的場景,如果您發現自己面臨著這樣的難題,我強烈推薦您使用這個插件。它提供了一項非常酷的特性:在eclipse中為所使用的數據庫提供圖形化的“關系視圖”。(我應該指出,如果您想從一個現有的數據庫模式開始,hibernate synchronizer也會有所幫助的。它的new mapping file wizard可以連接到您的數據庫,并基于所發現的內容構建映射文件。)
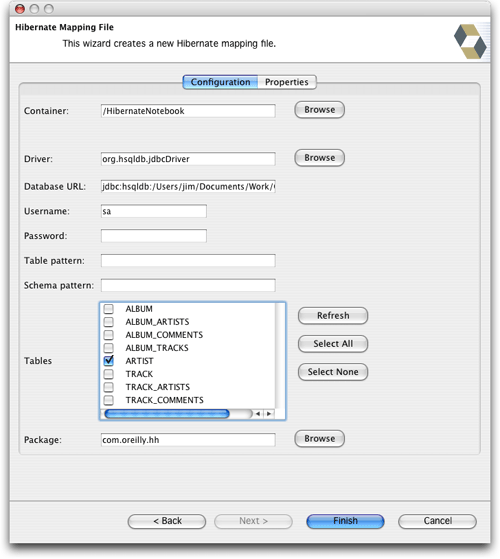
圖28. hibernate synchronizer的映射向導
hibernator
最后一個,hibernator似乎傾向于另一個方向,即,從java代碼開始生成簡單的hibernate映射文檔,然后讓您從映射文檔構建(或更新)數據庫模式。它還提供在eclipse中運行數據庫查詢的能力。在這3種插件中,它所處的開發階段似乎最早,但是已經值得關注了,特別是因為它的開發者是hibernate開發團隊的成員。
新聞熱點






疑難解答