數據綁定
所有這三個對象都可以作為數據綁定控件的數據源。而dataset 和 datatable 可作為更廣范圍控件的數據源。這是因為dataset 和 datatable 實現了(生成ilist接口)ilistsource接口,而sqldatareader 實現了ienumerable接口。許多能進行數據綁定的winform控件需要實現了ilist接口的數據源。
這種不同是因為為每種對象類型設計的場景類型不同。dataset (它包含 datatable)是一個豐富的、非鏈接結構,它適合于web和桌面(winform)應用程序。另一方面,數據閱讀器已經為web應用程序進行了優化,這種應用程序需要優化的、只能向前的數據訪問。
檢查將要綁定到的特定控件類型的數據源需求。
在應用程序層間傳遞數據
dataset提供了可作為xml被任意操縱數據的關系圖,并允許數據的非鏈接緩存拷貝在應用程序層與組件間傳遞。然而,sqldatareader提供了更優化的性能,因為它避免了與創建dataset相關的性能及內存開銷。記住,dataset對象的創建將導致多個子對象--包括datatable, datarow 和datacolumn--及作為這些子對象容器的集合對象的創建。
使用dataset
使用sqldataadapter填充的dataset對象,當:
你需要非鏈接的駐留內存的緩存數據,以便你能將它傳遞到其它組件或應用程序中的其它層。
你需要內存中的數據關系圖以執行xml或非xml操作。
你正在使用的數據來自多個數據源,如多個數據庫、表或文件。
你希望更新獲得的一些或所有行,并希望利用sqldataadapter的批更新功能。
你要對控件綁定數據,而此控件需要支持ilist接口的數據源。
更多信息
如果使用sqldataadapter生成dataset 或 datatable,需注意:
不必明確打開或關閉數據庫鏈接。sqldataadapter fill方法打開數據庫鏈接,并在此方法返回前關閉該鏈接。如果鏈接原來已經打開,那么此方法仍使鏈接處于打開狀態。
如果出于其它目的需要鏈接,那么考慮在調用fill方法前打開鏈接。這樣你就可以避免不必要的打開/關閉操作,提高性能。
盡管能重復使用同一sqlcommand對象多執行同樣的命令,但不要重復使用此對象執行不同的命令。
關于如何利用sqldataadapter對象填充dataset 或 datatable對象的代碼示例,見附錄中的如何利用sqldataadapter 對象獲得多行。
使用sqldatareader
些劣情況,可以使用通過調用 sqlcommand 對象的executereader方法得到的sqldatareader對象:
正在處理大量數據時--太多了而不能在單個緩沖區內維護。
希望減少應用程序在內存中的印跡。
希望避免與dataset對象創建相關的開銷。
希望對某控件執行數據綁定操作,而此控件支持實現了ienumerable接口的數據源。
希望流水線化數據訪問,并對其優化。
正在讀取包含二進制大對象(blob)列的行。你可以使用sqldatareader對象以可管理的大塊為單位從數據庫中將blob數據拉出來,而不是一次性地將所有數據提取出來。關于處理blob數據的更多細節,見本文處理blobs 一節。
更多信息
如果使用sqldatareader對象,請注意:
在數據閱讀器活動期間,底層的數據庫鏈接保持打開,并不能用于其它任何目的。盡可能早地對sqldatareader對象調用close方法。
每個鏈接只能有一個數據閱讀器。
通過向executereader方法傳遞commandbehavior.closeconnection枚舉值,可以在使用完數據閱讀器后,明確地關閉鏈接;或者,將鏈接生命周期綁定到sqldatareader對象。這預示著當sqldatareader對象關閉時,鏈接也將關閉。
在利用閱讀器訪問數據時,如果你知道列的底層數據類型,那么就應使用類型化存取器方法(如getint32 和 getstring),這是因為在讀取列數據時,這些方法減少了讀取列數據所需的類型轉換量。
為避免將不必要的數據從服務器發送到客戶端,如果你要關閉閱讀器并拋棄所有保留的結果,那么在對閱讀器調用close方法前調用命令對象的cancel方法。cancel方法確保了服務器的結果被拋棄,而不會被發送到客戶端。相反,對數據閱讀器調用close方法會使閱讀器不必要地提取出保留的結果,以清空數據流。
如果要得到從存儲過程返回的輸出值或返回值,并且你在利用sqlcommand對象的executereader方法,那么在得到輸出或返回值前,必須對閱讀器調用close方法。
關于演示如何利用sqldatareader對象的代碼示例,附錄中的如何利用sqldatareader對象獲取多行數據。
使用xmlreader
下列情況下,使用通過調用sqlcommand對象的executexmlreader方法得到的xmlreader對象:
希望將得到的數據作為xml 處理,但不希望引發因創建dataset對象而造成的額外性能開銷,并且不需要數據的非鏈接緩存。
希望利用sql server for xml 語法的功能,這種語法允許以靈活的方式從數據庫中得到xml片段(即,不帶根元素的xml文檔)。例如,這種方法使你能夠精確指定元素名,是使用元素還是使用以屬性為核心的圖解,圖解是否隨xml數據一起被返回,等等。
更多信息
如果使用xmlreader,請注意:
在從xmlreader對象中讀取數據時,鏈接必須保持打開。sqlcommand對象的 executexmlreader方法目前不支持commandbehavior.closeconnection枚舉值,因此在使用完閱讀器后必須明確關閉鏈接。
對于如何使用xmlreader對象的代碼示例,見附錄中的如何利用 xmlreader獲取多行數據。
獲取單行數據
在這種場景中,將從數據源中獲取包含一組指定列的單行數據。例如,你得到一個客戶id,并希望查找與客戶相關的細節;或得到一個產品id,并希望得到產品信息。
方法比較
如果要對從數據源中得到的一行數據執行綁定操作,可以用sqldataadapter對象填充dataset 或datatable對象,其方式與在先前討論過的獲取多行數據及重復場景中描述的方式相同。然而,除非特別需要dataset 或datatable對象的功能,否則應當避免創建這些對象。
如果需要獲取單行數據,那么請使用下面的一種方法:
使用存儲過程輸出參數.
使用sqldatareader對象.
這兩種方法都避免了在服務器端創建結果集,在客戶端創建dataset對象的不必要額外開銷。每種方法的相對性能要依賴于強度等級及數據庫鏈接池化是否被使能。當數據庫鏈接池化使能時,性能測試表明存儲過程方法在高強度環境下(同時存在200多鏈接)其性能比sqldatareader方法高近30%。
使用存儲過程輸出參數
如下情況中使用存儲過程輸出參數:
要從鏈接池化使能的多層web應用程序中獲得一行數據。
更多信息
關于演示如何使用存儲過程輸出參數的代碼示例,見附錄中的使用存儲過程輸出參數獲取一行數據。
使用sqldatareader對象
下列情況,需使用sqldatareader對象:
除了數據值,還需要元數據時。可以利用數據閱讀器的getschematable方法獲取列元數據。
未使用鏈接池化時。在鏈接池化無效時,sqldatareader對象在所有強度環境下都是好方式;性能測試表明,在200瀏覽器鏈接時,此方法比存儲過程方法在性能上要高約20%。
更多信息
如果知道查詢結果只需返回一行,那么在調用sqlcommand對象的executereader 方法時,使用commandbehavior.singlerow枚舉值。一些供應器,如ole db .net數據供應器,用此技巧來優化性能。例如,供應器使用irow接口(如果此接口存在)而不是代價更高的irowset接口。這個參數對sql server .net數據供應器沒有影響。
在使用sqldatareader對象時,總是應當通過sqldatareader對象的類型化存取器方法,如getstring 和getdecimal,獲得輸出參數。這樣做就避免了不必要的類型轉換。
關于如何使用sqldatareader對象獲取單行數據的代碼示例,見附錄中的如何使用 sqldatareader對象獲取單行數據。
獲取單項數據
在本場景中,要獲取單項數據。例如,提供了產品id后,希望查詢單一的產品名;或,給出了客戶名后,希望查詢客戶的信用等級。在這種場景中,為得到單項數據,通常不希望引發創建dataset 對象或甚至是 datatable對象的額外開銷。
也許只希望檢查數據庫中是否存在特定的行。例如,當新用戶在網站注冊時,需要檢查所選用戶名是否已經存在。這是單項數據查詢中很特殊的例子,但在此例子中,返回一個簡單的布爾返回值就足夠了。
方法比較
當從數據源獲取單項數據時,考慮下面的方法:
同存儲過程一起使用sqlcommand對象的executescalar方法。
使用存儲過程輸出或返回參數。
使用sqldatareader對象。
executescalar方法直接返回數據項,因為它是為只返回單個值的查詢設計的,與存儲過程輸出參數和sqldatareader方法相比,它需要更少的代碼。
從性能方面來說,應當使用存儲過程輸出或返回參數,因為測試結果表明,存儲過程方法在從低強度到高強度環境中(從同時不到100瀏覽器鏈接到200瀏覽器鏈接)提供了一致的性能。
更多信息
如果通過executequery方法所執行的查詢返回多列和/或行,那么此方法只返回第一行的第一列。
關于演示如何使用executescalar方法的代碼片段,見附錄中的如何使用 executescalar獲取單項數據。
關于演示如何利用存儲過程輸出或返回參數獲取單項數據的代碼示例,見附錄中的如何利用存儲過程輸出或返回參數獲取單項數據
關于演示如何使用sqldatareader對象獲取單項數據的代碼示例,見附錄中的如何使用 sqldatareader對象獲取單項數據。
通過防火墻建立鏈接
需要經常配置互聯網應用程序以使它能夠通過防火墻鏈接到sql server。例如,許多web應用程序及防火墻的主要結構組件是周邊網絡(也被稱為dmz或非軍事化區),它們用于隔離高端web服務器與內部網絡。
通過防火墻鏈接到sql server時,需要對防火墻,客戶和服務器進行明確配置。sql server提供了客戶網絡應用程序和服務器網絡應用程序以幫助進行配置。
選擇網絡庫
當通過防火墻建立鏈接時,使用sql server tcp/ip網絡庫來簡化配置,這是sql server2000安裝的默認選項。如果使用先前版本的sql server,那么分別利用客戶端網絡應用程序和服務器端網絡應用程序檢查tcp/ip是否在客戶和服務器端已經被配置為默認的網絡庫。
除了配置優點,使用tcp/ip庫還意味著:
受益于大宗數據的改進性能和增加的擴展性。
避免與指定管道相關的附加安全信息。
必須在客戶和服務器計算機上配置tcp/ip,因為大多數防火墻限制了流量通過的端口,所以必須仔細考慮sql server所使用的端口號。
配置服務器
sql server的默認實例監聽1433端口。然而,sql server 2000的指定實例在它們首次開啟時,動態地分配端口號。網絡管理員有希望在防火墻打開一定范圍的端口;因此,當隨防火墻使用sql server的指定實例時,利用服務網絡應用程序對實例進行配置,使它監聽特定的端口。然后管理員對防火墻進行配置,以使防火墻允許流量到達特定的ip地址及服務器實例所監聽的端口。
注意,客戶端網絡庫所使用的源端口號在1024-5000間動態分配。這是tcp/ip客戶端應用程序的標準作法,但這意味著防火墻必須允許途經此范圍的任何端口流量能夠通過。關于sql server所使用的端口的更多信息,在微軟產品支持服務網站上,參見inf: p 通過防火墻對sql server進行通訊所需的tcp端口 。。
動態查找指定實例
如果改變了sql server所監聽的默認端口,那么就要對客戶端進行配置,以使它鏈接到此端口。更多細節,見本文中的配置客戶端 一節。
如果改變了sql server 2000默認實例的端口號,那么不修改客戶端將導致鏈接錯誤。如果存在多個sql server 實例,最新版本的mdac數據訪問堆棧(2.6)將進行動態查找,并利用用戶數據報協議(udp)協商(通過udp端口1434)對指定實例進行定位。盡管這種方法在開發環境下也許有效,但在現在環境中卻不大可能正常工作,因為典型發問下防火墻阻止udp協商流量的通過。
為了避開這種情況,總是將客戶端配置為鏈接到已配置好的目的端口號。
配置客戶端
應當對客戶端進行配置以利用tcp/ip網絡庫鏈接到sql server,并且也應當確保客戶端庫使用了正確的目的端口號。
使用tcp/ip 網絡庫
利用sql server客戶端網絡庫,可以對客戶端進行配置。在某些安裝版本中,可能沒有將這個應用程序安裝到客戶端(如web服務器)。在這種情況下,可以按如下方式之一解決:
利用通過鏈接字符串提供的“network library=dbmssocn”名稱-值對指定網絡庫。字符串dbmssocn用于標識tcp/ip(套接字)庫。
注意 在使用sql server .net數據供應器時,網絡庫的默認設置是使用“dbmssocn”。
在客戶端機器上修改注冊表,把tcp/ip設置為默認庫。關于配置sql server網絡庫的更多信息,參見howto: 不使用客戶端網絡應用程序而修改sql server默認網絡庫(q250550)。
指定端口
如果sql server的實例被配置為監聽默認的1433以外的其它端口,那么通過以下操作,就能指定鏈接到的端口號:
使用客戶端網絡應用程序
利用提供給鏈接字符串的“server”或“data source”名稱-值對來指定端口號。要按下面的格式使用字符串:
"data source=servername,portnumber"
注意 servername可以是ip地址,或域名系統(dns)名,為了優化性能,可以使用ip 地址以避免dns 查詢。
分布式事務處理
如果開發了使用com+分布式事務處理和微軟分布式事務處理協調器(dtc)服務的服務組件,那么就需要對防火墻進行配置,以允許dtc流在不同dtc實例間及dtc與資源管理器(例如sql server)間流動。
有關為dtc開放端口的更多信息,見info:為通過防火墻工作,配置微軟分布式事務處理協調器 (dtc)。
處理blobs
目前,很多應用程序除了處理許多傳統的字符串和數字型數據外,還要處理象圖形或聲音--甚至復雜的數據格式,如視頻格式的數據。圖形、聲音與視頻的數據格式類型不一。然而從存儲角度來說,它們都可被視為二進制數據塊,通常將其稱為blobs(二進制大對象)。
sql server提供了binary, varbinary, 和image數據格式來存儲blobs。不考慮名稱,blob數據也可被稱為基于文件的數據。例如,你可能要存儲與特定行相關的二進制長注釋字段。sql server為此目的提供了ntext 和text數據類型。
通常,對于小于8kb的二進制數據,使用varbinary數據類型。對于超過此大小的二進制數據,使用image 。表2 匯集了每個數據類型的主要特性。
表2 數據類型特性
數據類型 大小 描述
binary 范圍從1-8kb。存儲大小是指定大小加4字節。 固定長度的二進制數據
varbinary 范圍從1-8kb。存儲大小是所提供數據的實際大小加4字節。 可變長度的二進制數據
image 從0-2gb大小的可變長度二進制數據 大容量可變長度二進制數據
text 從0-2gb大小的可變長度數據 字符型數據
ntext 從0-2gb大小的可變長度數據 寬字節字符數據
何處存儲blob數據
sql server 7.0及其以后版本已經提高了存儲在數據庫中的blob數據的使用性能。這種情況的一個原因是數據庫頁面大小已經增加到了8kb。結果,小于8kb的文本或圖象數據不必再存儲在頁面單獨的二進制樹結構中,而是能被存儲在單行中。這意味著讀取和寫入text, ntext, 或 image數據能象讀取或寫入字符或二進制字符串那樣快。超出8kb后,將在行中建立一個指針,數據本身存儲在獨立數據頁面的二進制樹結構中,這不可避免會對性能產生沖擊。
關于迫使text, ntext, 和 image數據存儲在單行中的更多信息,見sql server在線圖書中的使用text和image數據主題。
一個經常使用的處理blob數據的可選方法是,將blob數據存儲在文件系統中,并在數據庫列中存儲一個指針(通常是一個統一資源定位器--url鏈接)以引用正確的文件。對于sql server 7.0以前的版本,將blob數據存儲在數據庫外的文件系統中,可以提高性能。
然而,sql server 2000改進了blob支持,以及ado.net對讀取和寫入blob數據的支持,使在數據庫中存儲blob數據成為一種可行的方法。
在數據庫中存儲blob 數據的優點
將blob數據存儲在數據庫中,帶來了很多優點:
易于保持blob數據與行中其它項數據的同步。
blob數據由數據庫所支持,擁有單一的存儲流,易于管理。
通過sql server 2000所支持的xml可以訪問blob數據,這將在xml流中返回64位編碼描述的數據。
對包含了固定或可變長度的字符(包括寬字符)數據的列可以執行sql server全文本搜索(fts)操作。也可以對包含在image字段中的已格式化的基于文本的數據--word 或 excel文檔--執行fts操作。
將blob數據寫入到數據庫中
下面的代碼演示了如何利用ado.net將從某個文件獲得的二進制數據寫入sql server image字段中。
public void storepicture( string filename )
{
// read the file into a byte array
filestream fs = new filestream( filename, filemode.open, fileaccess.read );
byte[] imagedata = new byte[fs.length];
fs.read( imagedata, 0, (int)fs.length );
fs.close();
sqlconnection conn = new sqlconnection("");
sqlcommand cmd = new sqlcommand("storepicture", conn);
cmd.commandtype = commandtype.storedprocedure;
cmd.parameters.add("@filename", filename );
cmd.parameters["@filename"].direction = parameterdirection.input;
cmd.parameters.add("@blobdata", sqldbtype.image);
cmd.parameters["@blobdata"].direction = parameterdirection.input;
// store the byte array within the image field
cmd.parameters["@blobdata"].value = imagedata;
try
{
conn.open();
cmd.executenonquery();
}
catch
{
throw;
}
finally
{
conn.close();
}
}
從數據庫中讀取blob數據
在通過executereader方法創建sqldatareader對象以讀取包含blob數據的行時,需使用commandbehavior.sequentialaccess枚舉值。如果沒有此枚舉值,閱讀器一次只從服務器中向客戶端發送一行數據。如果行包含了bolb數據,這預示著要占用大量內存。通過利用枚舉值,就獲得了更好的控制權,因為blob數據只在被引用時才被發出(例如,利用getbytes方法,可以控制讀取的字節數)。這在下面的代碼片段中進行了演示。
// assume previously established command and connection
// the command selects the image column from the table
conn.open();
sqldatareader reader = cmd.executereader(commandbehavior.sequentialaccess);
reader.read();
// get size of image data - pass null as the byte array parameter
long bytesize = reader.getbytes(0, 0, null, 0, 0);
// allocate byte array to hold image data
byte[] imagedata = new byte[bytesize];
long bytesread = 0;
int curpos = 0;
while (bytesread < bytesize)
{
// chunksize is an arbitrary application defined value
bytesread += reader.getbytes(0, curpos, imagedata, curpos, chunksize);
curpos += chunksize;
}
// byte array 'imagedata' now contains blob from database
注意使用commandbehavior.sequentialaccess需要以嚴格的順序訪問列數據。例如,如果blob數據存在于第3列,并且還需要從第1,2列中讀取數據,那么在讀取第3列前必須先讀取第1,2列。
事務處理
實際上所有用于更新數據源的面向商業的應用程序都需要事務處理支持。通過提供四個基本擔保,即眾所周知的首字縮寫acid:可分性,一致性,分離性,和耐久性,事務處理將用于確保包含在一個或多個數據源中的系統的完整性。
例如,考慮一個基于web的零售應用程序,它用于處理購買訂單。每個訂單需要3個完全不同操作,這些操作涉及到3個數據庫更新:
庫存水準必須減少所訂購的數量。
所購買的量必須記入客戶的信用等級。
新訂單必須增加到數據庫中。
這三個不同的操作作為一個單元并自動執行是至關重要的。三個操作必須全部成功,或都不成功--任何一個操作出現誤差都將破壞數據完整性。事務處理提供了這種完整性及其它保證。
要進一步了解事務處理過程的基本原則,見http://msdn.microsoft.com/library/en-us/cpguide/html/cpcontransactionprocessingfundamentals.asp。
可以采用很多方法將事務管理合并到數據訪問代碼中。每種方法適合下面兩種基本編程模型之一。
手工事務處理。可以直接在組件代碼或存儲過程中分別編寫利用ado.net 或 transact-sql事務處理支持特性的代碼。
自動化(com+)事務處理。可以向.net類中增加聲明在運行時指定對象事務處理需要的屬性。這種模型使你能方便地配置多個組件以使它們在同一事務處理內運行。
盡管自動化事務處理模型極大地簡化了分布式事務處理過程,但兩種模型都用于執行本地事務處理(即對單個資源管理器如sql server 2000執行的事務處理)或分布式事務處理(即,對位于遠程計算機上的多個資源管理執行的事務處理)。
你也許會試圖利用自動化(com+)事務處理來從易于編程的模型中獲益。在有多個組件執行數據庫更新的系統中,這種優點更明顯。然而,在很多情況下,應當避免這種事務處理模型所帶來的額外開銷和性能損失。
本節將指導你根據特定的應用程序環境選擇最合適的模型。
選擇事務處理模型
在選擇事務處理模型前,首先應當考慮是否真正需要事務處理。事務處理是服務器應用程序使用的最昂貴的資源,在不必要使用的地方,它們降低了擴展性。考慮下面用于管理事務處理使用的準則:
只在需要跨一組操作獲取鎖并需要加強acid規則時才執行事務處理。
盡可能短地保持事務處理,以最小化維持數據庫鎖的時間。
永遠不要將客戶放到事務處理生命周期的控制之中。
不要為單個sql語句使用事務處理。sql server自動把每個語句作為單個事務處理執行。
自動化事務處理與手工事務處理的對比
盡管編程模型已經對自動化事務處理進行了簡化,特別是在多個組件執行數據庫更新時,但本地事務處理總是相當快,因為它們不需要與微軟dtc交互。即使你對單個本地資源管理器(如sql server)使用自動化事務處理,也是這種情況(盡管性能損失減少了),因為手式本地事務處理避免了所有不必要的與dtc的進程間通信。
對于下面的情況,需使用手工事務處理:
對單個數據庫執行事務處理。
對于下列情況,則宜使用自動事務處理:
需要將單個事務處理擴展到多個遠程數據庫時。
需要單個事務處理擁有多個資源管理器(如數據庫和windows 2000消息隊列(被稱為msmq)資源管理器)時。
注意 避免混用事務處理模型。最好只使用其中一個。
在性能足夠好的應用程序環境中,(甚至對于單個數據庫)選擇自動化事務處理以簡化編程模型,這種做法是合理的。自動化事務處理使多個組件能很容易地執行現一事務處理中的多個操作。
使用手工事務處理
對于手工事務處理,可以直接在組件代碼或存儲過程中分別編寫使用ado.net 或 transact-sql事務處理支持特性的代碼。多數情況下,應選擇在存儲過程中控制事務處理,因為這種方法提供了更高的封裝性,并且在性能方面,此方法與利用ado.net 代碼執行事務處理兼容。
利用ado.net執行手工事務處理
ado.net支持事務處理對象,利用此對象可以開始新事務處理過程,并明確控制事務處理是否執行還是回滾。事務處理對象與單個數據庫鏈接相關,可以通過鏈接對象的begintransaction方法獲得。調用此方法并不是暗示,接下來的命令是在事務處理上下文中發出的。必須通過設置命令的transaction屬性,明確地將每個命令與事務處理關聯起來。可以將多個命令對象與事務處理對象關聯,因此在單個事務處理中就針對單個數據庫把多個操作進行分組。
關于使用ado.net事務處理代碼的示例,見附錄中如何編碼ado.net手工事務處理。
更多信息
ado.net手工事務處理的默認分離級別是讀聯鎖,這意味著在讀取數據時,數據庫控制共享鎖,但在事務處理結束前,數據可以被修改。這種情況潛在地會產生不可重復的讀取或虛數據。通過將事務處理對象的isolationlevel屬性設置為isolationlevel枚舉類型所定義的一個枚舉值,就可改變分離級別。
必須仔細為事務處理選擇合適的分離級別。其折衷是數據一致性與性能的比例。最高的分離等級(被序列化了)提供了絕對的數據一致性,但是以系統整體吞吐量為代價。較低的分離等級會使應用程序更易于擴展,但同時增加了因數據不一致而導致出錯的可能性。對多數時間讀取數據、極少寫入數據的系統來說,較低的分離等級是合適的。
關于選擇恰當事務處理級別極有價值的信息,見微軟出版社名為inside sql server 2000的書,作者kalen delaney。
利用存儲過程執行手工事務處理
也可以在存儲過程中使用transact-sql語句直接控制手工事務處理。例如,可以利用包含了transact-sql事務處理語句(如begin transaction、end transaction及rollback transaction)的存儲過程執行事務處理。
更多信息
如果需要,可以在存儲過程中使用set transaction isolation level語句控制事務處理的分離等級。讀聯鎖是sql server的默認設置。關于sql server分離級別的更多信息,見sql server在線書目“訪問和修改關系數據”一節中的分離級別部分。
關于演示如何利用transact-sql事務處理語句執行事務更新的代碼示例,見附錄中的如何利用transact-sql執行事務處理。
使用自動化事務
自動化事務簡化了編程模型,因為它們不需要明確地開始新事務處理過程,或明確執行或取消事務。然而,自動化事務的最大優點是它們能與dtc結合起來,這就使單個事務可以擴展到多個分布式數據源中。在大型分布式應用程序中,這個優點是很重要的。盡管通過手工對dtc直接編程來控制分布式事務是可能的,但自動化事務處理極大的簡化了工作量,并且它是為基于組件的系統而設計的。例如,可以方便地以說明方式配置多個組件以執行包含了單個事務處理的任務。
自動化事務依賴于com+提供的分布式事務處理支持特性。結果,只有服務組件(即從servicedcomponent類中派生的組件)能夠使用自動化事務。
要為自動化事務處理配置類,操作如下:
從位于enterpriseservices名稱空間的servicedcomponent類中派生新類。
通過transaction屬性定義類的事務處理需求。來自transactionoption的枚舉值決定了如何在com+類中配置類。可與此屬性一同設置的其它屬性包括事務處理分離等級和超時上限。
為了避免必須明確選出事務處理結果,可以用autocomplete屬性對方法進行注釋。如果這些方法釋放異常,事務將自動取消。注意,如果需要,仍可以直接挑選事務處理結果。更多詳情,見本文稍后確定事務處理結果的節。
更多信息
關于com+自動化事務的更多信息,可在平臺sdk文檔中搜索“通過com+的自動化事務”獲取。
關于.ne t事務處理類的示例,見附錄中的如何編碼.net事務處理。
配置事務處理分離級別
用于com+1.0版--即運行在windows 2000中的com+--的事務處理分離級別被序列化了。這樣做提供了最高的分離等級,卻是以性能為代價的。系統的整體吞吐量被降低了。因為所涉及到的資源管理器(典型地是數據庫)在事務處理期間必須保持讀和寫鎖。在此期間,其它所有事務處理都被阻斷了,這種情況將對應用程序的擴展能力產生極大沖擊。
隨微軟windows .net發行的com+ 1.5版允許有com+目錄中按組件配置事務處理分離等級。與事務中根組件相關的設置決定了事務處理的分離等級。另外,同一事務流中的內部子組件擁有的事務處理等級必須不能高于要組件所定義的等級。如果不是這樣,當子組件實例化時,將導致錯誤。
對.net管理類,transaction屬性支持所有的公有isolation屬性。你可以用此屬性陳述式地指定一特殊分離等級,如下面的代碼所示:
[transaction(transactionoption.supported, isolation=transactionisolationlevel.readcommitted)]
public class account : servicedcomponent
{
. . .
}
更多信息
關于配置事務處理分離等級及其它windows .net com+增強特性的更多信息,見msdn雜志2001年8月期的“windows xp:利用com+ 1.5的增強特性使你的組件更強壯”一文。
確定事務處理結果
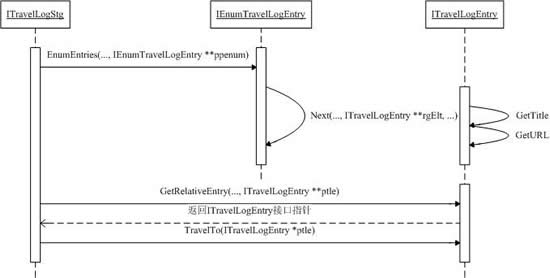
在單個事務流的所有事務處理組件上下文中,自動化事務處理結果由事務取消標志和一致性標志的狀態決定。當事務流中的根組件成為非活動狀態(并且控制權返回調用者)時,確定事務處理結果。這種情況在圖5中得到了演示,此圖顯示的是一個典型的銀行基金傳送事務。
圖5 事務流上下文
當根對象(在本例中是對象)變為非活動狀態,并且客戶的方法調用返回時,確定事務處理結果。在任何上下文中的任何一致性標志被設為假,或如果事務處理取消標志設為真,那么底層的物理dtc事務將被取消。
可以以下面兩種方式之一從.net對象中控制事務處理結果:
可以用autocomplete屬性對方法進行注釋,并讓.net自動存放將決定事務處理結果投票。如果方法釋放異常,利用此屬性,一致性標志自動地被設為假(此值最終使事務取消)。如果方法返回而沒有釋放異常,那么一致性標志將設為真,此值指出組件樂于執行事務。這并沒有得到保證,因為它依賴于同一事務流中其它對象的投票。
可以調用contextutil類的靜態方法setcomplete或 setabort,這些方法分別將一致性標志設為真或假。
嚴重性大于10的sql server錯誤將導致管理數據供應器釋放sqlexception類型的異常。如果方法緩存并處理異常,就要確保或者通過手工取消了事務,或者方法被標記了[autocomplete],以保證異常能傳遞回調用者。
autocomplete方法
對于標記了屬性的方法,執行下面操作:
將sqlexception傳遞加調用堆棧。
將sqlexception封裝在外部例外中,并傳遞回調用者。也可以將異常封裝在對調用者更有意義的異常類型中。
異常如果不能傳遞,將導致對象不會提出取消事務,從而忽視數據庫錯誤。這意味著共享同一事務流的其它對象的成功操作將被提交。
下面的代碼緩存了sqlexception,然后將它直接傳遞回調用者。事務處理最終將被取消,因為對象的一致性標志在對象變為非活動狀態時自動被設為假。
[autocomplete]
void somemethod()
{
try
{
// open the connection, and perform database operation
. . .
}
catch (sqlexception sqlex )
{
logexception( sqlex ); // log the exception details
throw; // rethrow the exception, causing the consistent
// flag to be set to false.
}
finally
{
// close the database connection
. . .
}
}
non-autocomlete方法
對于沒有autocomplete的屬性的方法,必須:
在catch塊內調用contextutil.setabort以終止事務處理。這就將相容標志設置為假。
如果沒有發生異常事件,調用contextutil.setcomplete,以提交事務,這就將相容標志設置為真(缺省狀態)。
代碼說明了這種方法。
void someothermethod()
{
try
{
// open the connection, and perform database operation
. . .
contextutil.setcomplete(); // manually vote to commit the transaction
}
catch (sqlexception sqlex)
{
logexception( sqlex ); // log the exception details
contextutil.setabort(); // manually vote to abort the transaction
// exception is handled at this point and is not propagated to the caller
}
finally
{
// close the database connection
. . .
}
}
注意 如果有多個catch塊,在方法開始的時候調用contextvtil.setabort,以及在try塊的末尾調用contextutil.setcomplete都會變得容易。用這種方法,就不需要在每個catch塊中重復調用contextutil.setabort。通過這種方法確定的相容標志的設置只在方法返回時有效。
對于異常事件(或循環異常),必須把它傳遞到調用堆棧中,因為這使得調用代碼認為事務處理失敗。它允許調用代碼做出優化選擇。比如,在銀行資金轉賬中,如果債務操作失敗,則轉帳分支可以決定不執行債務操作。
如果把相容標志設置為假并且在返回時沒有出現異常事件,則調用代碼就沒有辦法知道事務處理是否一定失敗。雖然可以返回boolean值或設置boolean輸出參數,但還是應該前后一致,通過顯示異常事件以表明有錯誤發生。這樣代碼就有一種標準的錯誤處理方法,因此更簡明、更具有相容性。
數據分頁
在分布式應用程序中利用數據進行分頁是一項普遍的要求。比如,用戶可能得到書的列表而該列表又不能夠一次完全顯示,用戶就需要在數據上執行一些熟悉的操作,比如瀏覽下一頁或上一頁的數據,或者跳到列表的第一頁或最后一頁。
這部分內容將討論實現這種功能的選項,以及每種選項在性能和縮放性上的效果。
選項比較
數據分頁的選項有:
利用sqldataadapter的fill方法,將來自查詢處的結果填充到dataset中。
通過com的可相互操作性使用ado,并利用服務器光標。
利用存儲的過程手工實現數據分頁。
對數據進行分頁的最優選項依賴于下列因素:
擴展性要求
性能要求
網絡帶寬
數據庫服務器的存儲器和功率
中級服務器的存儲器和功率
由分頁查詢所返回的行數
數據總頁數的大小
性能測試表明利用存儲過程的手工方法在很大的應力水平范圍上都提供了最佳性能。然而,由于手工方法在服務器上執行工作,如果大部分站點功能都依賴數據分頁功能,那么服務器性能就會成一個關鍵要素。為確保這種方法能適合特殊環境,應該測試各種特殊要求的選項。
下面將討論各種不同的選項。
使用sqldataadapter
如前面所討論的,sqldataadapter是用來把來自數據庫的數據填充到dataset中,過載的fill方法中的任一個都需要兩個整數索引值(如下列代碼所示):
public int fill(
dataset dataset,
int startrecord,
int maxrecords,
string srctable
);
startrecord值標示從零開始的記錄起始索引值。maxrecord值表示從startrecord開始的記錄數,并將拷貝到新的dataset中。
sqldataadapter在內部利用sqldatareader執行查詢并返回結果。sqldataadapter讀取結果并創建基于來自saldatareader的數據的dataset。sqldataadapter通過startrecord和maxrecords把所有結果都拷貝到新生成的dataset中,并丟棄不需要的數據。這意味著許多不必要的數據將潛在的通過網絡進入數據訪問客戶--這是這種方法的主要缺陷。
比如,如果有1000個記錄,而需要的是第900到950個記錄,那么前面的899個記錄將仍然穿越網絡然后被丟棄。對于小數量的記錄,這種開銷可能是比較小的,但如果針對大量數據的分頁,則這種開銷就會非常巨大。
使用ado
實現分頁的另一個選項是利用基于com的ado進行分頁。這種方法的目標是獲得訪問服務器光標。服務器光標通過ado recordset對象顯示。可以把recordset光標的位置設置到aduseserver中。如果你的ole db供應器支持這種設置(如sqloledb那樣),就可以使用服務器光標。這樣就可以利用光標直接導航到起始記錄,而不需要將所有數據傳過網絡進入訪問數據的用戶代碼中。
這種方法有下面兩個缺點:
在大多數情況下,可能需要將返回到recordset對象中的記錄翻譯成dataset中的內容,以便在客戶管理的代碼中使用。雖然oledbdataadapter確實在獲取ado recordset對象并把它翻譯成dataset時過載了fill方法,但是并沒有利用特殊記錄進行開始與結束操作的功能。唯一現實的選項是把開始記錄移動到recordset對象中,循環每個記錄,然后手工拷貝數據到手工生成的新dataset中。這種操作,尤其是利用com interop調用,其優點可能不僅僅是不需要在網絡上傳輸多余的數據,尤其對于小的dataset更明顯。
從服務器輸出所需數據時,將保持連接和服務器光標開放。在數據庫服務器上,光標的開放與維護需要昂貴的資源。雖然該選項提高了性能,但是由于為延長的時間兩消耗服務器資源,從而也有可能降低可擴展性。
提供手工實現
在本部分中討論的數據分頁的最后一個選項是利用存儲過程手工實現應用程序的分頁功能。對于包含唯一關鍵字的表格,實現存儲過程相對容易一些。而對于沒有唯一關鍵字的表格(也不應該有許多關鍵字),該過程會相對復雜一些。
帶有唯一關鍵字的表格的分頁
如果表格包含一個唯一關鍵字,就可以利用where條款中的關鍵字創建從某個特殊行起始的結果設置。這種方法,與用來限制結果設置大小的set rowcount狀態是相匹配的,提供了一種有效的分頁原理。這一方法將在下面存儲的代碼中說明:
create procedure getproductspaged
@lastproductid int,
@pagesize int
as
set rowcount @pagesize
select *
from products
where [standard search criteria]
and productid > @lastproductid
order by [criteria that leaves productid monotonically increasing]
go
這個存儲過程的調用程序僅僅維護lastproductid的值,并通過所選的連續調用之間的頁的大小增加或減小該值。
不帶有唯一關鍵字的表格的分頁
如果需要分頁的表格沒有唯一關鍵字,可以考慮添加一個--比如利用標識欄。這樣就可以實現上面討論的分頁方案了。
只要能夠通過結合結果記錄中的兩個或更多區域來產生唯一性,就仍然有可能實現無唯一關鍵字表格的有效分頁方案。
比如,考察下列表格: col1 col2 col3 other columns…
a 1 w …
a 1 x .
a 1 y .
a 1 z .
a 2 w .
a 2 x .
b 1 w …
b 1 x .
對于該表,結合col 、col2 和col3就可能產生一種唯一性。這樣,就可以利用下面存儲過程中的方法實現分布原理:
create procedure retrievedatapaged
@lastkey char(40),
@pagesize int
as
set rowcount @pagesize
select
col1, col2, col3, col4, col1+col2+col3 as keyfield
from sampletable
where [standard search criteria]
and col1+col2+col3 > @lastkey
order by col1 asc, col2 asc, col3 asc
go
客戶保持存儲過程返回的keyfield欄的最后值,然后又插入回到存儲過程中以控制表的分頁。
雖然手工實現增加了數據庫服務器上的應變,但它避免了在網絡上傳輸不必要的數據。性能測試表明在整個應變水平中這種方法都工作良好。然而,根據站點工作所涉及的數據分頁功能的多少,在服務器上進行手工分頁可能影響應用程序的可擴展性。應該在所在環境中運行性能測試,為應用程序找到最合適的方法。
附錄
如何為一個.net類啟用對象結構
要利用enterprise (com+)services為對象結構啟用.net管理的類,需要執行下列步驟:
從位于system. enterprise services名字空間中的serviced component中導出所需類。
using system.enterpriseservices;
public class dataaccesscomponent : servicedcomponent
為該類添加construction enabled屬性,并合理地指定缺省結構字符串,該缺省值保存在com+目錄中,管理員可以利用組件服務微軟管理控制臺(mnc)的snap-in來維護該缺省值。
[constructionenabled(default="default dsn")]
public class dataaccesscomponent : servicedcomponent
提供虛擬construct方法的替換實現方案。該方法在對象語言構造程序之后調用。在com目錄中保存的結構字符串是該方法的唯一字符串。
public override void construct( string constructstring )
{
// construct method is called next after constructor.
// the configured dsn is supplied as the single argument
}
通過assembly key文件或assembly key name屬性為該匯編提供一個強名字。任何用com+服務注冊的匯編必須有一個強名字。關于帶有強名字匯編的更多信息,參考:http://msdn.microsoft.com/library/en-us/cpguide/html/cpconworkingwithstrongly- namedassemblies.asp。
[assembly: assemblykeyfile("dataservices.snk")]
為支持動態注冊,可以利用匯編層上的屬性applicationname和application action分別指定用于保持匯編元素和應用程序動作類型的com+應用程序的名字。關于匯編注冊的更多信息,參考: http://msdn.microsoft.com/library/en-us/cpguide/html/cpconregisteringserviced components.asp。
// the applicationname attribute specifies the name of the
// com+ application which will hold assembly components
[assembly : applicationname("dataservices")]
// the applicationactivation.activationoption attribute specifies
// where assembly components are loaded on activation
// library : components run in the creator's process
// server : components run in a system process, dllhost.exe
[assembly: applicationactivation(activationoption.library)]
下列代碼段是一個叫做dataaccesscomponent的服務組件,它利用com+結構字符串來獲得數據庫連接字符串。
using system;
using system.enterpriseservices;
// the applicationname attribute specifies the name of the
// com+ application which will hold assembly components
[assembly : applicationname("dataservices")]
// the applicationactivation.activationoption attribute specifies
// where assembly components are loaded on activation
// library : components run in the creator's process
// server : components run in a system process, dllhost.exe
[assembly: applicationactivation(activationoption.library)]
// sign the assembly. the snk key file is created using the
// sn.exe utility
[assembly: assemblykeyfile("dataservices.snk")]
[constructionenabled(default="default dsn")]
public class dataaccesscomponent : servicedcomponent
{
private string connectionstring;
public dataaccesscomponent()
{
// constructor is called on instance creation
}
public override void construct( string constructstring )
{
// construct method is called next after constructor.
// the configured dsn is supplied as the single argument
this.connectionstring = constructstring;
}
}
如何利用sqldataadapter來檢索多個行
下面的代碼說明如何利用sqldataadapter對象發出一個生成data set或datatable的命令。它從sql server northwind數據庫中檢索一系列產品目錄。
using system.data;
using system.data.sqlclient;
public datatable retrieverowswithdatatable()
{
using ( sqlconnection conn = new sqlconnection(connectionstring) )
{
sqlcommand cmd = new sqlcommand("datretrieveproducts", conn);
cmd.commandtype = commandtype.storedprocedure;
sqldataadapter da = new sqldataadapter( cmd );
datatable dt = new datatable("products");
da.fill(dt);
return dt;
}
}
按下列步驟利用sqladapter生成dataset或datatable:
創建sqlcommand對象啟用存儲過程,并把它與sqlconnection對象(顯示的)或連接字符串(未顯示)相聯系。
創建一個新的sqldataadapter對象,并把它sqlcommand對象相聯系。
創建datatable(或者dataset)對象。利用構造程序自變量命名datatable.
調用sqldata adapter對象的fill方法,把檢索的行轉移到dataset或datatable中。
如何利用sqldatareader檢索多個行
下列代碼說明了如何利用sqldatareader方法檢索多行:
using system.io;
using system.data;
using system.data.sqlclient;
public sqldatareader retrieverowswithdatareader()
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
sqlcommand cmd = new sqlcommand("datretrieveproducts", conn );
cmd.commandtype = commandtype.storedprocedure;
try
{
conn.open();
// generate the reader. commandbehavior.closeconnection causes the
// the connection to be closed when the reader object is closed
return( cmd.executereader( commandbehavior.closeconnection ) );
}
catch
{
conn.close();
throw;
}
}
// display the product list using the console
private void displayproducts()
{
sqldatareader reader = retrieverowswithdatareader();
while (reader.read())
{
console.writeline("{0} {1} {2}",
reader.getint32(0).tostring(),
reader.getstring(1) );
}
reader.close(); // also closes the connection due to the
// commandbehavior enum used when generating the reader
}
按下列步驟利用sqldatareader檢索多行:
創建用于執行存儲的過程的sqlcommand對象,并把它與sqlconnection對象相聯系。
打開鏈接。
通過調用sqlcommand對象的excute reader方法生成sqldatareader對象。
從流中讀取數據,調用sqldatareader對象的read方法來檢索行,并利用分類的存取程序方法(如getiut 32和get string方法)檢索列的值。
完成讀取后,調用close方法。
如何利用xmlreader檢索多個行
可以利用sqlcommand對象生成xmlreader對象,它提供對xml數據的基于流的前向訪問。該命令(通常是一個存儲的過程)必須生成一個基于xml的結果設置,它對于sql server2000通常是由帶有有效條款for xml的select狀態組成。下列代碼段說明了這種方法:
public void retrieveanddisplayrowswithxmlreader()
{
sqlconnection conn = new sqlconnection(connectionstring);
sqlcommand cmd = new sqlcommand("datretrieveproductsxml", conn );
cmd.commandtype = commandtype.storedprocedure;
try
{
conn.open();
xmltextreader xreader = (xmltextreader)cmd.executexmlreader();
while ( xreader.read() )
{
if ( xreader.name == "products" )
{
string stroutput = xreader.getattribute("productid");
stroutput += " ";
stroutput += xreader.getattribute("productname");
console.writeline( stroutput );
}
}
xreader.close();
}
catch
{
throw;
}
finally
{
conn.close();
}
}
上述代碼使用了下列存儲過程:
create procedure datretrieveproductsxml
as
select * from products
for xml auto
go
按下列步驟檢索xml數據:
創建sqlcommand對象啟用生成xml結果設置的過程。(比如,利用select狀態中的for xml條款)。把sqlcommand對象與一個鏈接相聯系。
調用sqlcommand對象的executexmlreader方法,并把結果分配給前向對象xmltextreader。當不需要任何返回數據的基于xml的驗證時,這是應該使用的最快類型的xmlreader對象。
利用xmltextreader對象的read方法讀取數據。
如何利用存儲過程輸出參數檢索單個行
可以調用一個存儲過程,它通過一種稱做輸出參數的方式可以在單個行中返回檢索數據項。下列代碼段利用存儲的過程檢索產品的名稱和單價,該產品包含在northwind數據庫中。
void getproductdetails( int productid,
out string productname, out decimal unitprice )
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
// set up the command object used to execute the stored proc
sqlcommand cmd = new sqlcommand( "datgetproductdetailsspoutput", conn );
cmd.commandtype = commandtype.storedprocedure;
// establish stored proc parameters.
// @productid int input
// @productname nvarchar(40) output
// @unitprice money output
// must explicitly set the direction of output parameters
sqlparameter paramprodid =
cmd.parameters.add( "@productid", productid );
paramprodid.direction = parameterdirection.input;
sqlparameter paramprodname =
cmd.parameters.add( "@productname", sqldbtype.varchar, 40 );
paramprodname.direction = parameterdirection.output;
sqlparameter paramunitprice =
cmd.parameters.add( "@unitprice", sqldbtype.money );
paramunitprice.direction = parameterdirection.output;
try
{
conn.open();
// use executenonquery to run the command.
// although no rows are returned any mapped output parameters
// (and potentially return values) are populated
cmd.executenonquery( );
// return output parameters from stored proc
productname = paramprodname.value.tostring();
unitprice = (decimal)paramunitprice.value;
}
catch
{
throw;
}
finally
{
conn.close();
}
}
按下列步驟利用存儲的過程輸出參數檢索單個行:
創建一個sqlcommand對象,并把它與sqlconnection對象相聯系。
通過調用sqlcommand’s parameters集合的add方法設置存儲過程參數。缺省情況下,參數假定為輸出參數,所以必須明確設置任何輸出參數的方向。
注意 明確設置所有參數的方向是一次很好的練習,包括輸入參數。
打開連接。
調用sqlcommand對象的executenonquery方法。它在輸出參數(并潛在地帶有一個返回值)中。
利用value屬性從合適的sqlparameter對象中檢索輸出參數。
關閉連接。
上述代碼段啟用了下列存儲過程。
create procedure datgetproductdetailsspoutput
@productid int,
@productname nvarchar(40) output,
@unitprice money output
as
select @productname = productname,
@unitprice = unitprice
from products
where productid = @productid
go
如何利用sqldatareader檢索單個行
可以利用sqldatareader對象檢索單個行,以及來自返回數據流的所需欄的值。這由下列代碼說明:
void getproductdetailsusingreader( int productid,
out string productname, out decimal unitprice )
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
// set up the command object used to execute the stored proc
sqlcommand cmd = new sqlcommand( "datgetproductdetailsreader", conn );
cmd.commandtype = commandtype.storedprocedure;
// establish stored proc parameters.
// @productid int input
sqlparameter paramprodid = cmd.parameters.add( "@productid", productid );
paramprodid.direction = parameterdirection.input;
try
{
conn.open();
sqldatareader reader = cmd.executereader();
reader.read(); // advance to the one and only row
// return output parameters from returned data stream
productname = reader.getstring(0);
unitprice = reader.getdecimal(1);
reader.close();
}
catch
{
throw;
}
finally
{
conn.close();
}
}
按下列步驟返回帶有sqldatareader對象:
建立sqlcommand對象。
打開連接。
調用sqldreader對象的executereader對象。
利用sqldatareader對象的分類的存取程序方法檢索輸出參數--在這里是getstring和getdecimal.
上述代碼段啟用了下列存儲過程:
create procedure datgetproductdetailsreader
@productid int
as
select productname, unitprice from products
where productid = @productid
go
如何利用executescalar單個項
executescalar方法是設計成用于返回單個值的訪問。在返回多列或多行的訪問事件中,executescalar只返回第一行的第一例。
下列代碼說明如何查詢某個產品id的產品名稱:
void getproductnameexecutescalar( int productid, out string productname )
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
sqlcommand cmd = new sqlcommand("lookupproductnamescalar", conn );
cmd.commandtype = commandtype.storedprocedure;
cmd.parameters.add("@productid", productid );
try
{
conn.open();
productname = (string)cmd.executescalar();
}
catch
{
throw;
}
finally
{
conn.close();
}
}
按下列步驟利用execute scalar檢索單個項:
建立調用存儲過程的sqlcommand對象。
打開鏈接。
調用executescalar方法,注意該方法返回對象類型。它包含檢索的第一列的值,并且必須設計成合適的類型。
關閉鏈接。
上述代碼啟用了下列存儲過程:
create procedure lookupproductnamescalar
@productid int
as
select top 1 productname
from products
where productid = @productid
go
如何利用存儲過程輸出或返回的參數檢索單個項
利用存儲過程輸出或返回的參數可以查詢單個值,下列代碼說明了輸出參數的使用:
void getproductnameusingspoutput( int productid, out string productname )
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
sqlcommand cmd = new sqlcommand("lookupproductnamespoutput", conn );
cmd.commandtype = commandtype.storedprocedure;
sqlparameter paramprodid = cmd.parameters.add("@productid", productid );
paramprodid.direction = parameterdirection.input;
sqlparameter parampn =
cmd.parameters.add("@productname", sqldbtype.varchar, 40 );
parampn.direction = parameterdirection.output;
try
{
conn.open();
cmd.executenonquery();
productname = parampn.value.tostring();
}
catch
{
throw;
}
finally
{
conn.close();
}
}
按下列步驟利用存儲過程的輸出參數檢索單個值:
創建調用存儲過程的sqlcommand對象。
通過把sqlparmeters添加到sqlcommand’s parameters集合中設置任何輸入參數和單個輸出參數。
打開鏈接。
調用sqlcommand對象的execute nonquery方法。
關閉鏈接。
利用輸出sqlparameter的value屬性檢索輸出值。
上述代碼使用了下列存儲過程:
create procedure lookupproductnamespoutput
@productid int,
@productname nvarchar(40) output
as
select @productname = productname
from products
where productid = @productid
go
下列代碼說明如何利用返回值確定是否存在特殊行。從編碼的角度看,這與使用存儲過程輸出參數相類似,除了需要明確設置到parameterdirection.returnvalue的sqlparameter方向。
bool checkproduct( int productid )
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
sqlcommand cmd = new sqlcommand("checkproductsp", conn );
cmd.commandtype = commandtype.storedprocedure;
cmd.parameters.add("@productid", productid );
sqlparameter paramret =
cmd.parameters.add("@productexists", sqldbtype.int );
paramret.direction = parameterdirection.returnvalue;
try
{
conn.open();
cmd.executenonquery();
}
catch
{
throw;
}
finally
{
conn.close();
}
return (int)paramret.value == 1;
}
按下列步驟,可以利用存儲過程返回值檢查是否存在特殊行:
建立調用存儲過程的sqlcommand對象。
設置包含需要訪問的行的主要關鍵字的輸入參數。
設置單個返回值參數。把sqlparameter對象添加到sqlcommand’s parameter集合中,并設置它到parameterdireetion.returnvalue的方面。
打開鏈接。
調用sqlcommand對象的executenonquery的方法.
關閉鏈接。
利用返回值sqlparameter的value屬性檢索返回值。
上述代碼使用了下列存儲過程:
create procedure checkproductsp
@productid int
as
if exists( select productid
from products
where productid = @productid )
return 1
else
return 0
go
如何利用sqldatareader檢索單個項。
通過調用命令對象的executereader方法,可以利用sqldatareader對象獲得單個輸出值。這需要稍微多一些的代碼,因為sqldatareader read方法必須調用,然后所需值通過讀者存取程序方法得到檢索。sqldatareader對象的使用在下列代碼中說明:
bool checkproductwithreader( int productid )
{
sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=northwind");
sqlcommand cmd = new sqlcommand("checkproductexistswithcount", conn );
cmd.commandtype = commandtype.storedprocedure;
cmd.parameters.add("@productid", productid );
cmd.parameters["@productid"].direction = parameterdirection.input;
try
{
conn.open();
sqldatareader reader = cmd.executereader(
commandbehavior.singleresult );
reader.read();
bool brecordexists = reader.getint32(0) > 0;
reader.close();
return brecordexists;
}
catch
{
throw;
}
finally
{
conn.close();
}
}
上述代碼使用了下列存儲過程:
create procedure checkproductexistswithcount
@productid int
as
select count(*) from products
where productid = @productid
go
如何編碼ado.net手工事務
下列代碼說明如何利用sql server. net數據供應器提供的事務支持來保護事務的支金轉帳操作。該操作在位于同一數據庫中的兩個帳戶之間轉移支金。
public void transfermoney( string toaccount, string fromaccount, decimal amount )
{
using ( sqlconnection conn = new sqlconnection(
"server=(local);integrated security=sspi;database=simplebank" ) )
{
sqlcommand cmdcredit = new sqlcommand("credit", conn );
cmdcredit.commandtype = commandtype.storedprocedure;
cmdcredit.parameters.add( new sqlparameter("@accountno", toaccount) );
cmdcredit.parameters.add( new sqlparameter("@amount", amount ));
sqlcommand cmddebit = new sqlcommand("debit", conn );
cmddebit.commandtype = commandtype.storedprocedure;
cmddebit.parameters.add( new sqlparameter("@accountno", fromaccount) );
cmddebit.parameters.add( new sqlparameter("@amount", amount ));
conn.open();
// start a new transaction
using ( sqltransaction trans = conn.begintransaction() )
{
// associate the two command objects with the same transaction
cmdcredit.transaction = trans;
cmddebit.transaction = trans;
try
{
cmdcredit.executenonquery();
cmddebit.executenonquery();
// both commands (credit and debit) were successful
trans.commit();
}
catch( exception ex )
{
// transaction failed
trans.rollback();
// log exception details . . .
throw ex;
}
}
}
}
如何利用transact-sql執行事務
下列存儲過程說明了如何在transact-sql過程內執行事務的支金轉移操作。
create procedure moneytransfer
@fromaccount char(20),
@toaccount char(20),
@amount money
as
begin transaction
-- perform debit operation
update accounts
set balance = balance - @amount
where accountnumber = @fromaccount
if @@rowcount = 0
begin
raiserror('invalid from account number', 11, 1)
goto abort
end
declare @balance money
select @balance = balance from accounts
where accountnumber = @fromaccount
if @balance < 0
begin
raiserror('insufficient funds', 11, 1)
goto abort
end
-- perform credit operation
update accounts
set balance = balance + @amount
where accountnumber = @toaccount
if @@rowcount = 0
begin
raiserror('invalid to account number', 11, 1)
goto abort
end
commit transaction
return 0
abort:
rollback transaction
go
該存儲過程使用begin transaction, commit transaction,和rollback transaction狀態手工控制事務。
如何編碼事務性的.net類
下述例子是三種服務性的net類,它們配置或用于自動事務。每個類都帶有transaction屬性,它的值將決定是否啟動新事務流或者對象是否共享即時調用程序的數據流。這些元素一起工作來執行銀行支金轉移。transfer類配置有requiresnew事務屬性,而debit和credit類配置有required屬性。這樣,在運行的時候三個對象共享同一個事務。
using system;
using system.enterpriseservices;
[transaction(transactionoption.requiresnew)]
public class transfer : servicedcomponent
{
[autocomplete]
public void transfer( string toaccount,
string fromaccount, decimal amount )
{
try
{
// perform the debit operation
debit debit = new debit();
debit.debitaccount( fromaccount, amount );
// perform the credit operation
credit credit = new credit();
credit.creditaccount( toaccount, amount );
}
catch( sqlexception sqlex )
{
// handle and log exception details
// wrap and propagate the exception
throw new transferexception( "transfer failure", sqlex );
}
}
}
[transaction(transactionoption.required)]
public class credit : servicedcomponent
{
[autocomplete]
public void creditaccount( string account, decimal amount )
{
sqlconnection conn = new sqlconnection(
"server=(local); integrated security=sspi"; database="simplebank");
sqlcommand cmd = new sqlcommand("credit", conn );
cmd.commandtype = commandtype.storedprocedure;
cmd.parameters.add( new sqlparameter("@accountno", account) );
cmd.parameters.add( new sqlparameter("@amount", amount ));
try
{
conn.open();
cmd.executenonquery();
}
catch (sqlexception sqlex)
{
// log exception details here
throw; // propagate exception
}
}
}
[transaction(transactionoption.required)]
public class debit : servicedcomponent
{
public void debitaccount( string account, decimal amount )
{
sqlconnection conn = new sqlconnection(
"server=(local); integrated security=sspi"; database="simplebank");
sqlcommand cmd = new sqlcommand("debit", conn );
cmd.commandtype = commandtype.storedprocedure;
cmd.parameters.add( new sqlparameter("@accountno", account) );
cmd.parameters.add( new sqlparameter("@amount", amount ));
try
{
conn.open();
cmd.executenonquery();
}
catch (sqlexception sqlex)
{
// log exception details here
throw; // propagate exception back to caller
}
}
}
合作者
非常感謝下列撰稿者和審校者:
bill vaughn, mike pizzo, doug rothaus, kevin white, blaine dokter, david schleifer, graeme malcolm(內容專家), bernard chen(西班牙人), matt drucke(協調)和steve kirk.
讀者有什么樣的問題、評論和建議?關于本文的反饋信息,請發e-mail至devfdbck®microsoft.com。
你希望學習并利用.net的強大功能嗎?與微軟技術中心的技術專家一起工作,學習開發最佳方案。詳細信息請訪問: http://www.micrsoft.com/business/services/mtc.asp。