Python中可以使用compile()方法把源程序編譯成代碼對象或AST(Abstract Syntax Tree)模塊對象。使用compile()方法生成的代碼對象可以使用exec()函數或eval()函數執行。
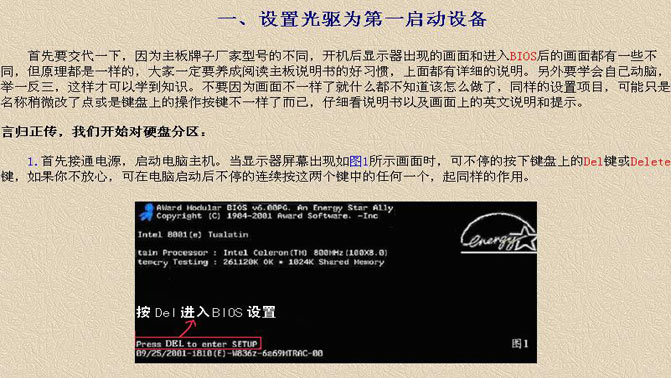
官方文檔給出的語法格式如下:
compile(source, filename, mode, flags = 0, dont_inherit = False, optimize = -1)
source:必要參數,生成代碼對象的源,其可以是一個字符串、字節字符串或AST對象。
filename:必要參數,該參數給出可以讀取源代碼的文件,如果不是從文件中讀取源代碼,則可以給一個可識別值,通常是一個字符串。
mode:必要參數,該參數用于指定代碼編譯的模式,主要有以下三種:
① exec:如果源代碼包含多條Python語句時,選用此模式;
②eval:如果源代碼僅包含一個表達式時,選用此模式;
③single:如果源代碼包含一個交互語句時,選用此模式;
flags和dont_inherit是兩個可選參數,控制編譯器的選項是否在將來的Python版本中進行使用。flags默認為0,dont_inherit默認為False。如果這兩個值都未指定或都為0,則代碼使用compile()函數相同的標志影響代碼。如果指定了flags參數,而未指定dont_inherit參數(或為0),那么由編譯器指定的選項和由flags參數指定的將來語句將被用于將來進行編譯。如果dont_inherit參數是非0的整數,那么flags參數就是代碼中的將來特征和編譯器選項,這些標記值將被忽略。
optimize:用于指定編譯器的優化水平。默認值為-1,指使用Python解釋器的優化級別(移除斷言語句以及任何以__debug__值為條件的語句)。0表示不進行優化(__debug__值為True);1移除代碼中的斷言語句,同時模塊中的__debug__值為false。2在1的基礎上,同時移除文檔字符串。
該函數返回一個代碼對象,可供exec或eval執行。
下面是把一個字符串代碼變異成代碼對象的例子。
#定義源代碼串,多行代碼使用/n換行
str1 = "x=3/ny=5/nprint('x+y=',x+y)"
#編譯成代碼對象
code_obj = compile(str1,'sum.py','exec')
#code_obj的類型
print(type(code_obj))
#執行代碼對象
exec(code_obj)
輸出結果:
<class 'code'>
x+y= 8
從這個例子中,我們首先定義了一個源碼字符串str1,并且讓其作為compile()函數的第一個參數,第二個參數是一個必需的參數,所以我們這里使用sum.py作為其參數,其實這個參數必須有,但是什么樣的字符串無所謂。因為有多行代碼,我們這里使用exec編譯模式。編譯完后,使用exec調用代碼對象,并輸出其結果。同時,在這個例子中,我們注意到compile()函數生成的對象類型為<class 'code'>類型的。
下面這個例子是從文件中讀取源代碼的例子。
我們首先定義一個Python源程序文件:temp.py,在該文件中輸入以下內容:
str1 = "I Love China"
str2 = "I Love Harbin."
print(str1 + "," + str2)
然后與temp.py文件同目錄下建立一個新的文件cmp.py,代碼如下:
#以只讀格式打開文件
f = open('temp.py','r')
#讀取文件的內容到變量str_code中
str_code = f.read()
#關閉文件
f.close()
#編譯代碼
code_obj = compile(str_code, 'temp.py', 'exec')
#執行代碼對象
exec(code_obj)
輸出結果如下:
I Love China,I Love Harbin.
這里雖然是從文件中讀取的源代碼,但第2個參數仍然隨意寫一個字符串。
下面再舉一個eval模式的例子。
dic ={"lang1":"R","lang2":"Python"}
code_obj1 = compile('dic["lang1"]','value','eval')
res1 = eval(code_obj1)
print(res1)
code_obj2 = compile("print(dic)","","eval")
res2 = eval(code_obj2)
輸出結果如下:
R
{'lang1': 'R', 'lang2': 'Python'}
下面再舉一個source為字節字符串的例子。
s = "str1='我愛中國.'/nstr2='我愛北京'/nprint(str1+str2)"
bytes_s = bytes(s,'utf-8')
code_obj = compile(bytes_s,"","exec")
exec(code_obj)
輸出結果如下:
我愛中國.我愛北京
上面代碼中,bytes()函數的作用是把字符串轉換為字節字符串,關于bytes()函數的使用,請見本站:Python bytes()函數。
新聞熱點






疑難解答