本文和大家重點討論一下Perl split函數(shù)的用法,Perl中的一個非常有用的函數(shù)是Perl split函數(shù)-把字符串進行分割并把分割后的結(jié)果放入數(shù)組中。這個Perl split函數(shù)使用規(guī)則表達式(RE),如果未特定則工作在$_變量上。
Perl split函數(shù)
Perl中的一個非常有用的函數(shù)是Perl split函數(shù)-把字符串進行分割并把分割后的結(jié)果放入數(shù)組中。這個Perl split函數(shù)使用規(guī)則表達式(RE),如果未特定則工作在$_變量上。
Perl split函數(shù)可以這樣使用:
◆如果我們已經(jīng)把信息存放在$_變量中,那么可以這樣:
如果各個域被任何數(shù)量的冒號分隔,可以用RE代碼進行分割:
其結(jié)果是:@personal=("Capes","Geoff","Shotputter","BigAvenue");
但是下面的代碼:
的結(jié)果是:@personal=("Capes","Geoff","","Shotputter","","","BigAvenue");
◆這個Perl split函數(shù)中單詞可以被分割成字符,句子可以被分割成單詞,段落可以被分割成句子:
在第一句中,空字符串在每個字符間匹配,所以@chars數(shù)組是一個字符的數(shù)組。>>
//之間的部分表示split用到的正則表達式(或者說分隔法則)
/s是一種通配符,代表空格
+代表重復一次或者一次以上。
所以,/s+代表一個或者一個以上的空格。
split(//s+/,$line)表示把字符串$line,按空格為界分開。
比如說,$line="你好朋友歡迎光臨我的網(wǎng)站VeVB.COm";
split(//s+/,$line)后得到:
你好朋友歡迎訪問我的網(wǎng)站VeVB.COm
一般用法: @somearray = split(/:+/, $string ); #括號可以不要。 若不指定$string, 則對默認變量$_操作, 兩斜線間為分割符,可以用正則表達式,強悍異常。
在perl手冊里,有一個用法不多見。即: split /PATTERN/, EXPR, LIMIT; 關(guān)鍵就是這個LIMIT參數(shù),可以節(jié)省不少事情。 如果使用了LIMIT,且是正數(shù),表示分割成不多于LIMIT指定的數(shù)目的域。If LIMIT is unspecified or zero, trailing null fields are stripped (which potential users of pop would do well to remember). If LIMIT is negative, it is treated as if an arbitrarily large LIMIT had been specified. Note that splitting an EXPR that evaluates to the empty string always returns the empty list, regardless of the LIMIT specified.
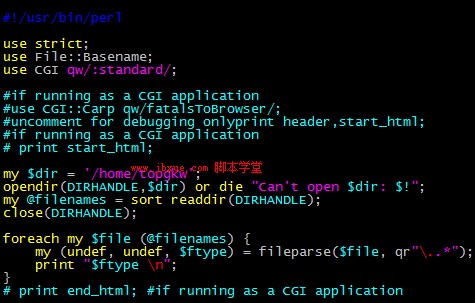
通過制定LIMIT,可以在很長(分割產(chǎn)生幾萬個元素or域)的行分割操作中,只返回關(guān)鍵的前幾列的域值,減少了內(nèi)存使用及時間消耗。比如一般的基因型數(shù)據(jù),第一列通常是材料命名,需要通過材料名的判斷取舍,這時候就可以這樣用。 my ($firstfield) = split //t/, $someline, 1; 如果需要前面幾列的值,這樣的方式對大文件效率很好: my (undef, $var1, undef, undef, undef, $var2)=split //t/, $someline, 6;
有網(wǎng)友對這種方式做了測試,顯示較好。引用如下:
>>>
一個文件,每行都有18項,各項之間用/t分割,使用時用到了第6項,折騰了幾種用法
看來后3種才是王道,如果需要使用多項也可以進行進行適當?shù)淖儎印2贿^兩項如果跨度比較大,3,4應該是不錯選擇,5就只能用中間數(shù)組。
自己動手測試下吧。
新聞熱點




疑難解答