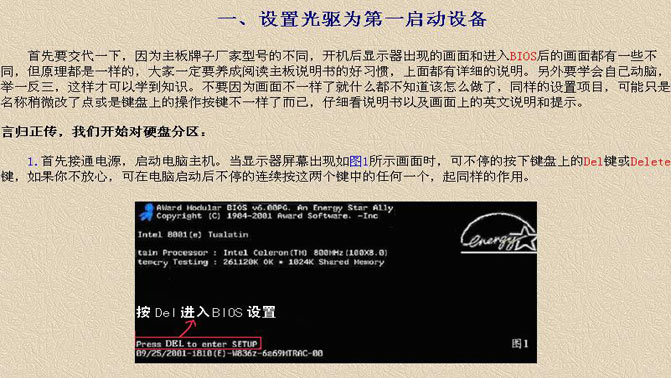
在Heap中,我們依靠PostgreSQL支撐大多數后端繁重的任務,我們存儲每個事件為一個hstore blob,我們為每個跟蹤的用戶維護一個已完成事件的PostgreSQL數組,并將這些事件按時間排序。 Hstore能夠讓我們以靈活的方式附加屬性到事件中,而且事件數組賦予了我們強大的性能,特別是對于漏斗查詢,在這些查詢中我們計算不同轉化渠道步驟間的輸出。
在這篇文章中,我們看看那些意外接受大量輸入的PostgreSQL函數,然后以高效,慣用的方式重寫它。
你的第一反應可能是將PostgreSQL中的數組看做像C語言中對等的類似物。你之前可能用過變換陣列位置或切片來操縱數據。不過要小心,在PostgreSQL中不要有這樣的想法,特別是數組類型是變長的時,比如JSON、文本或是hstore。如果你通過位置來訪問PostgreSQL數組,你會進入一個意想不到的性能暴跌的境地。
這種情況幾星期前在Heap出現了。我們在Heap為每個跟蹤用戶維護一個事件數組,在這個數組中我們用一個hstore datum代表每個事件。我們有一個導入管道來追加新事件到對應的數組。為了使這一導入管道是冪等的,我們給每個事件設定一個event_id,我們通過一個功能函數重復運行我們的事件數組。如果我們要更新附加到事件的屬性的話,我們只需使用相同的event_id轉儲一個新的事件到管道中。
所以,我們需要一個功能函數來處理hstores數組,并且,如果兩個事件具有相同的event_id時應該使用數組中最近出現的那個。剛開始嘗試這個函數是這樣寫的:
-- This is slow, and you don't want to use it!---- Filter an array of events such that there is only one event with each event_id.-- When more than one event with the same event_id is present, take the latest one.CREATE OR REPLACE FUNCTION dedupe_events_1(events HSTORE[]) RETURNS HSTORE[] AS $$ SELECT array_agg(event) FROM ( -- Filter for rank = 1, i.e. select the latest event for any collisions on event_id. SELECT event FROM ( -- Rank elements with the same event_id by position in the array, descending.
這個查詢在擁有2.4GHz的i7CPU及16GB Ram的macbook pro上測得,運行腳本為:https://gist.github.com/drob/9180760。
在這邊究竟發生了什么呢? 關鍵在于PostgreSQL存貯了一個系列的hstores作為數組的值, 而不是指向值的指針. 一個包含了三個hstores的數組看起來像
{“event_id=>1,data=>foo”, “event_id=>2,data=>bar”, “event_id=>3,data=>baz”}相反的是
{[pointer], [pointer], [pointer]}
對于那些長度不一的變量, 舉個例子. hstores, json blobs, varchars,或者是 text fields, PostgreSQL 必須去找到每一個變量的長度. 對于evaluateevents[2], PostgreSQL 解析從左側讀取的事件直到讀取到第二次讀取的數據. 然后就是 forevents[3], 她再一次的從第一個索引處開始掃描,直到讀到第三次的數據! 所以, evaluatingevents[sub]是 O(sub), 并且 evaluatingevents[sub]對于在數組中的每一個索引都是 O(N2), N是數組的長度.
PostgreSQL能得到更加恰當的解析結果, 它可以在這樣的情況下分析該數組一次. 真正的答案是可變長度的元素與指針來實現,以數組的值, 以至于,我們總能夠處理 evaluateevents[i]在不變的時間內.
即便如此,我們也不應該讓PostgreSQL來處理,因為這不是一個地道的查詢。除了generate_subscripts我們可以用unnest,它解析數組并返回一組條目。這樣一來,我們就不需要在數組中顯式加入索引了。
-- Filter an array of events such that there is only one event with each event_id.-- When more than one event with the same event_id, is present, take the latest one.CREATE OR REPLACE FUNCTION dedupe_events_2(events HSTORE[]) RETURNS HSTORE[] AS $$ SELECT array_agg(event) FROM ( -- Filter for rank = 1, i.e. select the latest event for any collisions on event_id. SELECT event FROM ( -- Rank elements with the same event_id by position in the array, descending. SELECT event, row_number AS index, rank() OVER (PARTITION BY (event -> 'event_id')::BIGINT ORDER BY row_number DESC) FROM ( -- Use unnest instead of generate_subscripts to turn an array into a set. SELECT event, row_number() OVER (ORDER BY event -> 'time') FROM unnest(events) AS event ) unnested_data ) deduped_events WHERE rank = 1 ORDER BY index ASC ) to_agg;$$ LANGUAGE SQL IMMUTABLE;
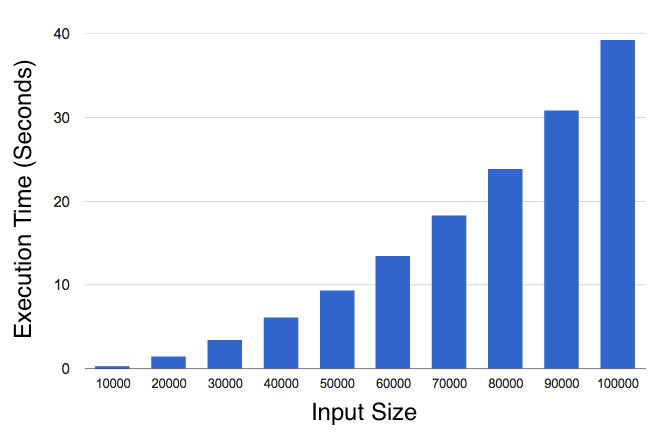
結果是有效的,它花費的時間跟輸入數組的大小呈線性關系。對于100K個元素的輸入它需要大約半秒,而之前的實現需要40秒。
這實現了我們的需求:
教訓:如果你需要訪問PostgreSQL數組的特定位置,考慮使用unnest代替。
SELECT events[sub] AS event, sub, rank() OVER (PARTITION BY (events[sub] -> 'event_id')::BIGINT ORDER BY sub DESC) FROM generate_subscripts(events, 1) AS sub ) deduped_events WHERE rank = 1 ORDER BY sub ASC ) to_agg;$$ LANGUAGE SQL IMMUTABLE;
這樣奏效,但大輸入是性能下降了。這是二次的,在輸入數組有100K各元素時它需要大約40秒!

這個查詢在擁有2.4GHz的i7CPU及16GB Ram的macbook pro上測得,運行腳本為:https://gist.github.com/drob/9180760。
在這邊究竟發生了什么呢? 關鍵在于PostgreSQL存貯了一個系列的hstores作為數組的值, 而不是指向值的指針. 一個包含了三個hstores的數組看起來像
{“event_id=>1,data=>foo”, “event_id=>2,data=>bar”, “event_id=>3,data=>baz”}相反的是
{[pointer], [pointer], [pointer]}
對于那些長度不一的變量, 舉個例子. hstores, json blobs, varchars,或者是 text fields, PostgreSQL 必須去找到每一個變量的長度. 對于evaluateevents[2], PostgreSQL 解析從左側讀取的事件直到讀取到第二次讀取的數據. 然后就是 forevents[3], 她再一次的從第一個索引處開始掃描,直到讀到第三次的數據! 所以, evaluatingevents[sub]是 O(sub), 并且 evaluatingevents[sub]對于在數組中的每一個索引都是 O(N2), N是數組的長度.
PostgreSQL能得到更加恰當的解析結果, 它可以在這樣的情況下分析該數組一次. 真正的答案是可變長度的元素與指針來實現,以數組的值, 以至于,我們總能夠處理 evaluateevents[i]在不變的時間內.
即便如此,我們也不應該讓PostgreSQL來處理,因為這不是一個地道的查詢。除了generate_subscripts我們可以用unnest,它解析數組并返回一組條目。這樣一來,我們就不需要在數組中顯式加入索引了。
-- Filter an array of events such that there is only one event with each event_id.-- When more than one event with the same event_id, is present, take the latest one.CREATE OR REPLACE FUNCTION dedupe_events_2(events HSTORE[]) RETURNS HSTORE[] AS $$ SELECT array_agg(event) FROM ( -- Filter for rank = 1, i.e. select the latest event for any collisions on event_id. SELECT event FROM ( -- Rank elements with the same event_id by position in the array, descending. SELECT event, row_number AS index, rank() OVER (PARTITION BY (event -> 'event_id')::BIGINT ORDER BY row_number DESC) FROM ( -- Use unnest instead of generate_subscripts to turn an array into a set. SELECT event, row_number() OVER (ORDER BY event -> 'time') FROM unnest(events) AS event ) unnested_data ) deduped_events WHERE rank = 1 ORDER BY index ASC ) to_agg;$$ LANGUAGE SQL IMMUTABLE;
結果是有效的,它花費的時間跟輸入數組的大小呈線性關系。對于100K個元素的輸入它需要大約半秒,而之前的實現需要40秒。
這實現了我們的需求:
教訓:如果你需要訪問PostgreSQL數組的特定位置,考慮使用unnest代替。
新聞熱點




疑難解答