語言是人們進行溝通和交流的表達符號,每種語言都有專屬于自己的符號,表達方式和規則。 就編程語言來說,它也是由特定的符號,特定的表達方式和規則組成。語言的作用是溝通,不管是自然語言,還是編程語言,它們的區別在于自然語言是人與人之間溝通的工具, 而編程語言是人與機器之間的溝通渠道。
就PHP語言來說,它也是一組符合一定規則的約定的指令。 在編程人員將自己的想法以PHP語言實現后,通過PHP的虛擬機(確切的來說應該是PHP的語言引擎Zend)將這些PHP指令轉變成C語言 (可以理解為更底層的一種指令集)指令,而C語言又會轉變成匯編語言, 最后匯編語言將根據處理器的規則轉變成機器碼執行。這是一個更高層次抽象的不斷具體化,不斷細化的過程。
從一種語言到另一種語言的轉化稱之為編譯,這兩種語言分別可以稱之為源語言和目標語言。 這種編譯過程通過發生在目標語言比源語言更低級(或者說更底層)。 語言轉化的編譯過程是由編譯器來完成, 編碼器通常被分為一系列的過程:詞法分析、語法分析、語義分析、中間代碼生成、代碼優化、目標代碼生成等。 前面幾個階段(詞法分析、語法分析和語義分析)的作用是分析源程序,我們可以稱之為編譯器的前端。 后面的幾個階段(中間代碼生成、代碼優化和目標代碼生成)的作用是構造目標程序,我們可以稱之為編譯器的后端。 一種語言被稱為編譯類語言,一般是由于在程序執行之前有一個翻譯的過程, 其中關鍵點是有一個形式上完全不同的等價程序生成。 而PHP之所以被稱為解釋類語言,就是因為并沒有這樣的一個程序生成, 它生成的是中間代碼Opcode,這只是PHP的一種內部數據結構。
二、 PHP代碼的執行的過程比如我們寫一個簡單的程序
<?php echo "Hello World!"; $a = 1 + 1; echo $a;?>這個簡單的程序他執行過程是怎樣的呢?其實,執行過程也正如我們前面所說分為4個步驟。(這里只是指PHP語言引擎Zend執行過程,不包含Web服務器的執行過程。)
1.Scanning(Lexing) ,將PHP代碼轉換為語言片段(Tokens)2.Parsing, 將Tokens轉換成簡單而有意義的表達式3.Compilation, 將表達式編譯成Opocdes4.Execution, 順次執行Opcodes,每次一條,從而實現PHP腳本的功能。
注2:現在有的Cache比如APC,可以使得PHP緩存住Opcodes,這樣,每次有請求來臨的時候,就不需要重復執行前面3步,從而能大幅的提高PHP的執行速度。
1. Scanning(Lexing),將PHP代碼轉換為語言片段(Tokens)那什么是Lexing? 學過編譯原理的同學都應該對編譯原理中的詞法分析步驟有所了解,Lex就是一個詞法分析的依據表。
對于PHP在開始使用的是Flex,之后改為re2c, html' target='_blank'>MySQL的詞法分析使用的Flex,除此之外還有作為UNIX系統標準詞法分析器的Lex等。 這些工具都會讀進一個代表詞法分析器規則的輸入字符串流,然后輸出以C語言實做的詞法分析器源代碼。 這里我們只介紹PHP的現版詞法分析器,re2c。 在源碼目錄下的Zend/zend_language_scanner.l 文件是re2c的規則文件, 如果需要修改該規則文件需要安裝re2c才能重新編譯,生成新的規則文件。Zend/zend_language_scanner.c會根據Zend/zend_language_scanner.l,來輸入的 PHP代碼進行詞法分析,從而得到一個一個的“詞”。
從PHP4.2開始提供了一個函數叫token_get_all,這個函數就可以將一段PHP代碼 Scanning成Tokens;
我們用下面的代碼使用token_get_all函數處理我們開頭提到的PHP代碼。
<?phpecho "<pre>";$phpcode = <<<PHPCODE<?php echo "Hello World!"; $a = 1 + 1; echo $a;?>PHPCODE;// $tokens = token_get_all($phpcontent);// print_r($tokens);$tokens = token_get_all($phpcode); foreach ($tokens as $key => $token) { $tokens[$key][0] = token_name($token[0]);}print_r($tokens);?>
注:為了便于理解和查看,我使用token_name函數將解析器代號修改成了符號名稱說明。
如果有的童鞋想要看原始的,可以將上面代碼中的第10,11行代碼注釋去掉。
解釋器代號列表詳見:http://www.php.net/manual/zh/tokens.php
得到的結果如下:
Array( [0] => Array ( [0] => T_OPEN_TAG [1] => 1 ) [1] => Array ( [0] => T_WHITESPACE [1] => [2] => 2 ) [2] => Array ( [0] => T_ECHO [1] => echo [2] => 2 ) [3] => Array ( [0] => T_WHITESPACE [1] => [2] => 2 ) [4] => Array ( [0] => T_CONSTANT_ENCAPSED_STRING [1] => "Hello World!" [2] => 2 ) [5] => [6] => Array ( [0] => T_WHITESPACE [1] => [2] => 2 ) [7] => [8] => Array ( [0] => T_WHITESPACE [1] => [2] => 3 ) [9] => Array ( [0] => T_LNUMBER [1] => 1 [2] => 3 ) [10] => Array ( [0] => T_WHITESPACE [1] => [2] => 3 ) [11] => [12] => Array ( [0] => T_WHITESPACE [1] => [2] => 3 ) [13] => Array ( [0] => T_LNUMBER [1] => 1 [2] => 3 ) [14] => [15] => Array ( [0] => T_WHITESPACE [1] => [2] => 3 ) [16] => Array ( [0] => T_ECHO [1] => echo [2] => 4 ) [17] => Array ( [0] => T_WHITESPACE [1] => [2] => 4 ) [18] => [19] => Array ( [0] => T_WHITESPACE [1] => [2] => 4 ) [20] => Array ( [0] => T_CLOSE_TAG [1] => ?> [2] => 5 ))
分析這個返回結果我們可以發現,源碼中的字符串,字符,空格都會原樣返回。
每個源代碼中的字符,都會出現在相應的順序處。
而其他的,比如標簽,操作符,語句,都會被轉換成一個包含三部分的
1、Token ID解釋器代號 (也就是在Zend內部的改Token的對應碼,比如,T_ECHO,T_STRING)
2、源碼中的原來的內容
3、該詞在源碼中是第幾行。
2. Parsing, 將Tokens轉換成簡單而有意義的表達式接下來,就是Parsing階段了,Parsing首先會丟棄Tokens Array中的多于的空格,
然后將剩余的Tokens轉換成一個一個的簡單的表達式
1.echo a constant string2.add two numbers together3.store the result of the prior expression to a variable4.echo a variable
Bison是一種通用目的的分析器生成器。它將LALR(1)上下文無關文法的描述轉化成分析該文法的C程序。 使用它可以生成解釋器,編譯器,協議實現等多種程序。 Bison向上兼容Yacc,所有書寫正確的Yacc語法都應該可以不加修改地在Bison下工作。 它不但與Yacc兼容還具有許多Yacc不具備的特性。
Bison分析器文件是定義了名為yyparse并且實現了某個語法的函數的C代碼。 這個函數并不是一個可以完成所有的語法分析任務的C程序。 除此這外我們還必須提供額外的一些函數: 如詞法分析器、分析器報告錯誤時調用的錯誤報告函數等等。 我們知道一個完整的C程序必須以名為main的函數開頭,如果我們要生成一個可執行文件,并且要運行語法解析器, 那么我們就需要有main函數,并且在某個地方直接或間接調用yyparse,否則語法分析器永遠都不會運行。
在PHP源碼中,詞法分析器的最終是調用re2c規則定義的lex_scan函數,而提供給Bison的函數則為zendlex。 而yyparse被zendparse代替。在PHP實現內部,opcode由如下的結構體表如下:
struct _zend_op {opcode_handler_t handler; // 執行該opcode時調用的處理函數znode result;znode op1;znode op2;ulong extended_value;uint lineno;zend_uchar opcode; // opcode代碼};和CPU的指令類似,有一個標示指令的opcode字段,以及這個opcode所操作的操作數。
PHP不像匯編那么底層, 在腳本實際執行的時候可能還需要其他更多的信息,extended_value字段就保存了這類信息。
其中的result域則是保存該指令執行完成后的結果。
PHP腳本編譯為opcode保存在op_array中,其內部存儲的結構如下:
struct _zend_op_array { /* Common elements */ zend_uchar type; char *function_name; // 如果是用戶定義的函數則,這里將保存函數的名字 zend_class_entry *scope; zend_uint fn_flags; union _zend_function *prototype; zend_uint num_args; zend_uint required_num_args; zend_arg_info *arg_info; zend_bool pass_rest_by_reference; unsigned char return_reference; /* END of common elements */ zend_bool done_pass_two; zend_uint *refcount; zend_op *opcodes; // opcode數組 zend_uint last,size; zend_compiled_variable *vars; int last_var,size_var; // ...}ZEND_API void execute(zend_op_array *op_array TSRMLS_DC){ // ... 循環執行op_array中的opcode或者執行其他op_array中的opcode}前面提到每條opcode都有一個opcode_handler_t的函數指針字段,用于執行該opcode。
PHP有三種方式來進行opcode的處理:CALL,SWITCH和GOTO。
PHP默認使用CALL的方式,也就是函數調用的方式, 由于opcode執行是每個PHP程序頻繁需要進行的操作,
可以使用SWITCH或者GOTO的方式來分發, 通常GOTO的效率相對會高一些,
不過效率是否提高依賴于不同的CPU。
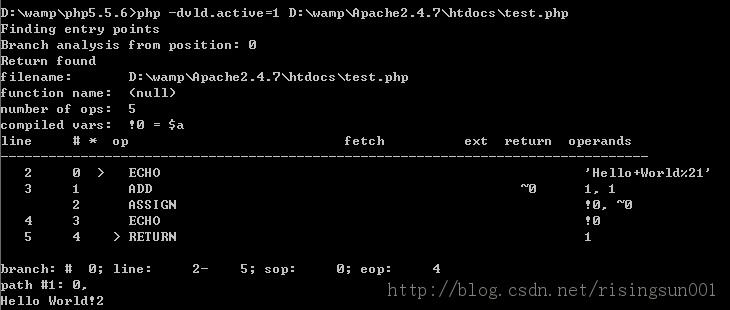
在我們上面的例子中,我們的PHP代碼會被Parsing成:* ZEND_ECHO 'Hello World%21'* ZEND_ADD ~0 1 1* ZEND_ASSIGN !0 ~0* ZEND_ECHO !0* ZEND_RETURN 1你可能會問了,我們的$a去那里了?這個要介紹操作數了,每個操作數都是由以下倆個部分組成:
a)op_type : 為IS_CONST, IS_TMP_VAR, IS_VAR, IS_UNUSED, or IS_CV b)u,一個聯合體,根據op_type的不同,分別用不同的類型保存了這個操作數的值(const)或者左值(var)
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。
新聞熱點





疑難解答