為什么使用“小偷程序”?
遠程抓取文章資訊或商品信息是很多企業(yè)要求程序員實現(xiàn)的功能,也就是俗說的小偷程序。其最主要的優(yōu)點是:解決了公司網(wǎng)編繁重的工作,大大提高了效率。只需要一運行就能快速的抓取別人網(wǎng)站的信息。
“小偷程序”在哪里運行?
“小偷程序” 應(yīng)該在 Windows 下的 DOS(參考文章:http://www.it165.net/pro/html/201201/1460.html) 或 Linux 下通過 PHP 命令運行為最佳,因為,網(wǎng)頁運行會超時。
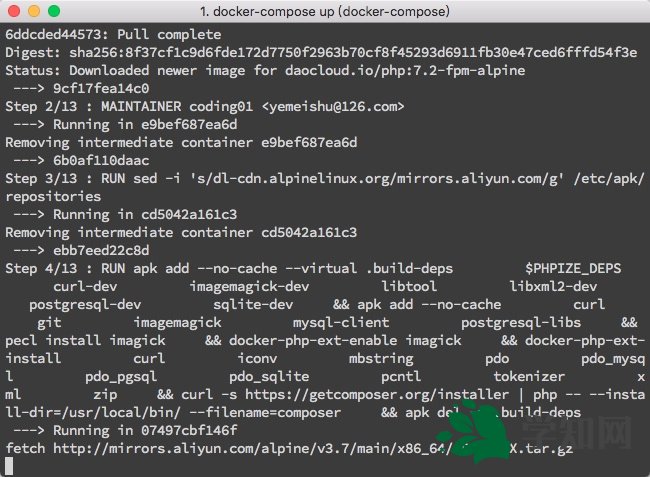
比如圖(Windows 下 DOS 為例):
.com/uploads/allimg/190506/115P94313-0.gif)
“小偷程序”的實現(xiàn)
這里主要通過一個實例來講解,我們來抓取下“華強電子網(wǎng)”的資訊信息,請先看觀察這個鏈接 http://www.it165.net/info-c10.html,當(dāng)您打開這個頁面的時候發(fā)現(xiàn)這個頁面會發(fā)現(xiàn)一些現(xiàn)象:
1、資訊列表有 500 頁(2012-01-03);
2、每頁的 url 鏈接都有規(guī)律,比如:第1頁為http://www.it165.net/info-c10-1.html;第2頁為http://www.it165.net/info-c10-2.html;……第500頁為http://www.it165.net/info-c10-500.html;
3、由第二點就可以知道,“華強電子網(wǎng)” 的資訊是偽靜態(tài)或者是生成的靜態(tài)頁面
其實,基本上大部分的網(wǎng)站都有這樣的規(guī)律,比如:中關(guān)村在線、慧聰網(wǎng)、新浪、淘寶……。
這樣,我們可以通過這樣的思路來實現(xiàn)頁面內(nèi)容的抓取:
1、先獲取文章列表頁內(nèi)容;
2、根據(jù)文章列表頁內(nèi)容循環(huán)獲取文章的 url 地址;
3、根據(jù)文章的 url 地址獲取文章的詳細內(nèi)容
這里,我們主要抓取資訊頁里面的:標(biāo)題(title)、發(fā)布如期(date)、作者(author)、來源(source)、內(nèi)容(content)
“華強電子網(wǎng)”資訊抓取
首先,先建數(shù)據(jù)表結(jié)構(gòu),如下所示:
CREATE TABLE `article`.`article` (`id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY ,`title` VARCHAR( 255 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,`date` VARCHAR( 50 ) NOT NULL ,`author` VARCHAR( 100 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,`source` VARCHAR( 100 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,`content` TEXT NOT NULL) ENGINE = MYISAM CHARACTER SET utf8 COLLATE utf8_general_ci;抓取程序:
<?php/*** 抓取“華強電子網(wǎng)”資訊程序* author Lee.* Last modify $Date: 2012-1-3 15:39:35 $*/header('Content-Type:text/html;Charset=utf-8');$mysqli = new mysqli('localhost', 'root', '1715544', 'article'); # 數(shù)據(jù)庫連接,請手動修改您自己的數(shù)據(jù)庫信息$mysqli->set_charset('UTF8'); # 設(shè)置數(shù)據(jù)庫編碼function data($url) { global $mysqli; $result = file_get_contents($url); # $result 獲取 url 鏈接內(nèi)容(注意:這里是文章列表鏈接) $pattern = '/<li><span class="box_r">.+<//span><a href="([^"]+)" title=".+" >.+<//a><//li>/Usi'; # 取得文章 url 的匹配正則 preg_match_all($pattern, $result, $arr); # 把文章列表 url 分配給數(shù)組$arr(二維數(shù)組) foreach ($arr[1] as $val) { $val = 'http://www.hqew.com' . $val; # 真實文章 url 地址 $re = file_get_contents($val); # $re 為文章 url 的內(nèi)容 $pa = '/<div id="article">/s+<h1>(.+)<//h1>/s+<p id="article/_extinfo">/s+發(fā)布:/s+(.+)/s+/|/s+作者:/s+(.+)/s+/|/s+來源:/s+(.*?)/s+<span style="display:none" >.+<div id="article_body">/s*(.+)/s+<//div>/s+<//div><!--article end-->/Usi'; # 取得文章內(nèi)容的正則 preg_match_all($pa, $re, $array); # 把取到的內(nèi)容分配到數(shù)組 $array $content = trim($array[5][0]); $con = array( 'title'=>mysqlString($array[1][0]), 'date'=>mysqlString($array[2][0]), 'author'=>mysqlString(stripAuthorTag($array[3][0])), 'source'=>mysqlString($array[4][0]), 'content'=>mysqlString(stripContentTag($content)) ); $sql = "INSERT INTO article(title,date,author,source,content) VALUES ('{$con['title']}','{$con['date']}','{$con['author']}','{$con['source']}','{$con['content']}')"; $row = $mysqli->query($sql); # 添加到數(shù)據(jù)庫 if ($row) { echo 'add success!'; } else { echo 'add failed!'; } }}/** * stripOfficeTag($v) 對文章內(nèi)容進行過濾,比如:去掉文章中的鏈接,過濾掉沒有的 HTML 標(biāo)簽…… * @param string $v * @return string */function stripContentTag($v){ $v = str_replace('<p> </p>', '', $v); $v = str_replace('<p />', '', $v); $v = preg_replace('/<a href=".+" target="/_blank"><strong>(.+)<//strong><//a>/Usi', '/1', $v); $v = preg_replace('%(<span/s*[^>]*>(.*)</span>)%Usi', '/2', $v); $v = preg_replace('%(/s+class="Mso[^"]+")%si', '', $v); $v = preg_replace('%( style="[^"]*mso[^>]*)%si', '', $v); $v = preg_replace('/<b><//b>/', '', $v); return $v;}/** * stripTitleTag($title) 對文章標(biāo)題進行過濾 * @param string $v * @return string */function stripAuthorTag($v) { $v = preg_replace('/<a href=".+" target="/_blank">(.+)<//a>/Usi', '/1', $v); return $v;}/** * mysqlString($str) 過濾數(shù)據(jù) * @param string $str * @return string */function mysqlString($str) { return addslashes(trim($str));}/** * init($min, $max) 入口程序方法,從 $min 頁開始取,到 $max 頁結(jié)束 * @param int $min 從 1 開始 * @param int $max * @return string 返回 URL 地址 */function init($min=1, $max) { for ($i=$min; $i<=$max; $i++) { data("http://www.hqew.com/info-c10-{$i}.html"); }}init(1, 500); #程序入口?>通過上面的程序,就可以實現(xiàn)抓取華強電子網(wǎng)的資訊信息。
入口方法 init($min, $max) 如果想抓取 1-500 頁面內(nèi)容,那么 init(1, 500) 即可!這樣,用不了多長時間,華強電子網(wǎng)的資訊就會全部抓取到數(shù)據(jù)庫里面了。^_^
執(zhí)行界面:
.com/uploads/allimg/190506/115P93L6-1.gif)
.com/uploads/allimg/190506/115P963Y-2.gif) PHP編程
PHP編程 鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。
新聞熱點





疑難解答
圖片精選