函數是這樣定義的:
int ord ( string$string)返回字符串 string 第一個字符的 ASCII 碼值。
該函數是chr()的互補函數。
試一下:
echo ord('我');
這里只能返回230, 我是以u8保存的文件并輸出的, 它得到的只有230, 而230轉換成hex是e6,實際上utf-8中我的編碼是e68891, 它只拿到了第一個字節
echo chr(0xe6).chr(0x88).chr(0x91);
這個例子可以在utf-8的情況下輸出”我“這個漢字
如果大家想了解字符編碼的問題可以點這里字符編碼
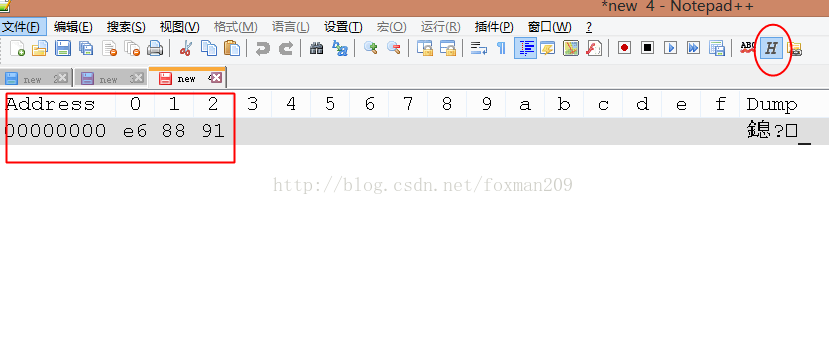
如果大家想查看一個漢字的gbk,utf-8,unicode各種編碼方式推薦大家用Notepad++下的HEX-editor點擊這里下載:
http://pan.baidu.com/s/1hquyJwo
長這樣子
提高逼格:
身為一個程序猿,除了是苦逼的代名詞外,還是神秘的象征,偶爾裝XX還是不錯的。既然說到編碼,
那我們就說說屬于你的字吧,在utf-8編碼的世界里,可不是每個人都能找到屬于自己的那款哦,
‘我’的編碼是三字節,分別為e6、88、91,如果把你的生日放進去能編出啥字呢,想想是不是還有點小激動,
例如你是1988-9-4出生,那對應的屬于自己的三字節為e9、88、94,anyway這個規則你也可以自己定義,
爆個料,按照此方法,我的字是‘釉’,好字啊,you you 切克鬧。
按照此法為啥不是每個人都有呢,那自己讀下utf-8的二進制存儲規則就炸ky"http://www.it165.net/qq/" target="_blank" html' target='_blank'>class="keylink">qq1wMHLo6w8L3A+CjxwPrn+uf6jrLu5yse149XiwO/X1rf7seDC6zwvcD4KPHA+s7bBy9K7ttHDu9PDtcSjrMbkyrW+zcrHz6PN+7TzvNK3os/WseDC67XEwNbIpDxzdHJvbmc+PGltZyBhbHQ9"大笑" src="https://cdn14.x6kj.com/uploads/allimg/190510/142434B04-1.gif">
自己動手:
很久以前是沒有mb_substr函數的,因此帶漢字的字符串截斷操作處理起來很麻煩,不過現在可以直接用它。
既然我們對字符編碼和ord函數有了很好的了解,自己就寫個針對utf-8編碼的字符串截斷的函數吧。
代碼很戳,有待優化,但理解起來簡單,貼過去可以運行,基本場景也考慮到了,還算欣慰;
<?php $a = "jf我們de沒"; /** * @brief * * @param $str 待截取的字符串 * @param $start 字符串開始位置 * @param $num 截取到多長的字符串 * * @return */ function utf8_substr($str, $start, $num){ $res = ''; //存儲截取到的字符串 $cnt = 0; //計數器,用來判斷字符串是否走到$start位置 $t = 0; //計數器,用來判斷字符串已經截取了$num的數量 for($i = 0; $i < strlen($str); $i++){ if(ord($str[$i]) > 127){ //非ascii碼時 if($cnt >= $start){ //如果計數器走到了$start的位置 $res .=$str[$i].$str[++$i].$str[++$i]; //utf-8是三字節編碼,$i指針連走三下,把字符存起來 $t ++; //計數器++,表示我存了幾個字符串了到$num的數量就退出了 }else{ $i++; //如果沒走到$start的位置,那就只走$i指針,字符不用處理 $i++; } $cnt ++; }else{ if($cnt >= $start){ //acsii碼正常處理就好 $res .=$str[$i]; $t++; } $cnt ++; } if($num == $t) break; //ok,我要截取的數量已經夠了,我不貪婪,我退出了 } return $res; } var_dump(utf8_substr($a, 3, 10)); //結果應該是你想要的?>
PHP編程 鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。
新聞熱點





疑難解答