首頁| 新聞| 娛樂| 游戲| 科普| 文學| 編程| 系統| 數據庫| 建站| 學院| 產品| 網管| 維修| 辦公| 熱點
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。
MBR怎么轉換為GPT?硬盤MBR格式
威剛發布新一代Ultimate SU900
MBR怎么轉換為GPT?硬盤MBR格式轉換成GPT格
校園甜美的背影,洋溢著青春爛漫的回憶
芭蕾舞蹈表演,真實美到極致
春天的魅力:綠楊煙外曉寒輕
春節臨近,各地春節彩燈高高掛
肉食主義者的最愛美食烤肉圖片
夏日甜心草莓美食圖片
人逢知己千杯少,喝酒搞笑圖集
搞笑試卷,學生惡搞答題
新聞熱點
疑難解答
圖片精選
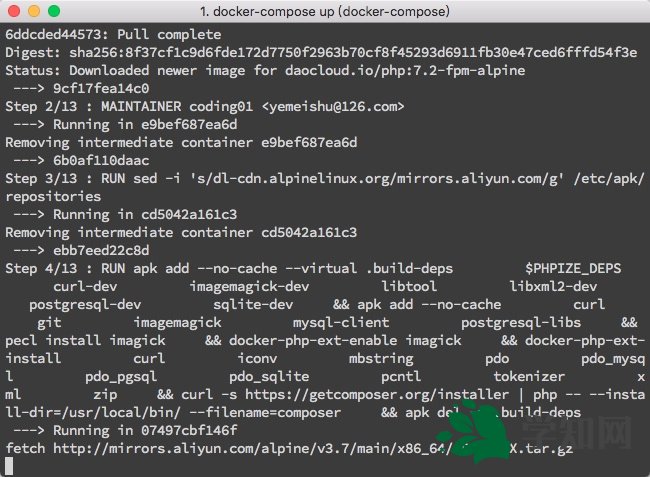
自己搭建一個 Laravel 的 Docker的
yii2權限控制rbac之rule詳細講解
php如何實現上篇和下篇的功能(代碼)
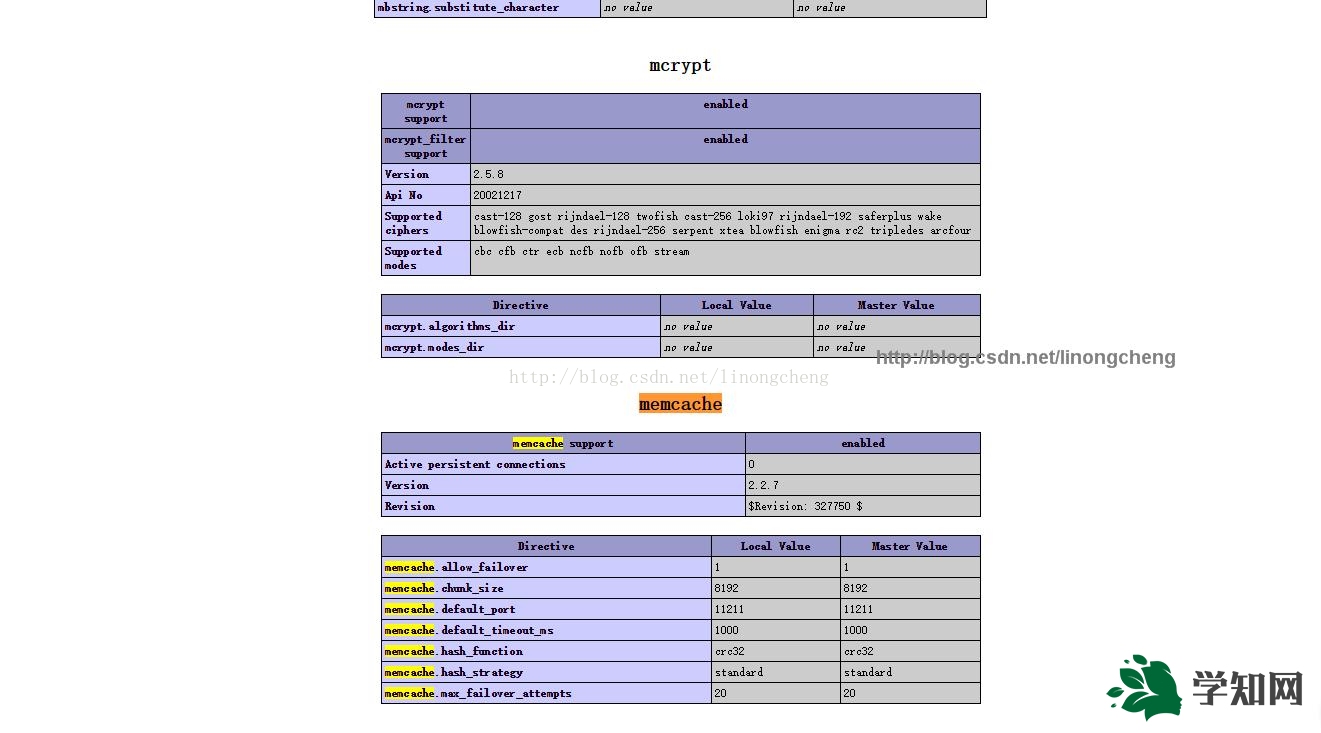
PHP下擴展memcache模塊
網友關注