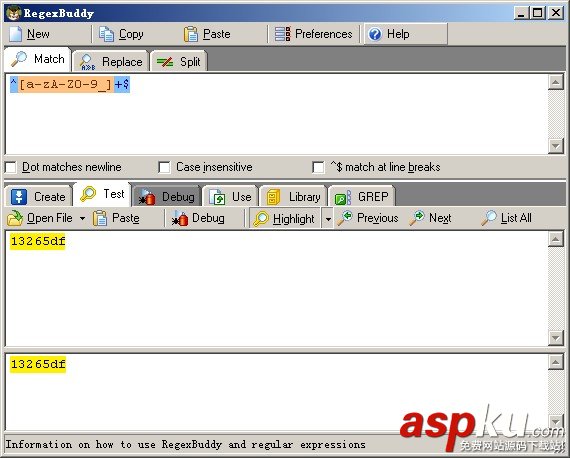
PHP代碼如下
復制代碼代碼如下:
$words = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSRUVWXYZ!@#$%^&*()_+-=[]//,./{}|<>?'/"你好啊我們";
$otherStr=preg_replace("/[chr(128)-chr(256)]+/is"," ",$words);
echo 'otherStr:',$otherStr;
為什么打印的結果會是:
otherStr: ! #$% & {}| ‘”你好啊我們
麻煩問下其中正則表達式 /[chr(128)-chr(256)]+/is 代表什么意思?
如果/[chr(128)-chr(256)]+/is 指的是ascii碼在128到256的字符,為什么a-zA-Z這樣的字符也被替換掉了,他們的ascii碼是小于127的。
最令人郁悶的是為什么ascii碼同在0-127區間”#”,”$”,”%”,”&”, “!”,” {“,”}”,”|”,” ‘”,”確沒有被替換掉????
更令人感覺神奇的是 如果把正則表達式修改為”/[chr(128)-chr(256)]+/s”的話,輸出的結果就變成了: otherStr: defg ijklmnopq stuvwxyz ! #$% & {}| ‘”你好啊我們
只是把正則表達式中的符號‘i'給去掉,結果缺失這樣的。 完全的令我理解不了。
不知各位 有何見解????
另附ascii 碼 對照表
(這個ASCII碼表的圖我就不貼了)
回帖中,有個網友說沒解析chr(128)這些,并給出了新的解決方法。首先說下此網友回答的是正確的,先不評論他是否“知其然,且知其所以然”,這位網友沒有給出錯誤的原因。
CFC4N來回答一下這位網友:
PHP的正則的preg_match函數用的是PCRE正則引擎,這位網友的代碼中,PCRE引擎處理的正則表達式為【/[chr(128)-chr(256)]+/is】,后面的is是什么呢?
在PHP的正則里,邊界字符后面的叫模式修飾符。它會告訴引擎如何解析,處理正則。其中i修飾符表示不區分大小寫。s表示“點號通配模式”,用來讓正則里的元字符點號【.】可以匹配換行符,這個修飾符僅對點號【.】起作用。在這位網友的問題中,修飾符s并不起作用的。
查找原因:
我們在來分析一下這個網友寫的正則表達式【[chr(128)-chr(256)]+】,正則表達式的PCRE引擎是如何解釋這個正則的呢?首先,我們要知道,在正則表達式中,中括號【[]】表示字符組,字符組中除了連接符【-】只外,都不是元字符,也就是說,都是普通字符,當然,如果連字符出現在第一個,或者不是標識兩個字符之間范圍的,都是普通的字符橫杠“-”罷了。這里的chr(128)只是標識ASCII碼為128(確切的說,ASCII碼只是0-127個,128到其他的,應該不叫ASCII碼了。),但是在正則里,他仍然代表【c、h、r、(、1、2、8、)】(頓號不是,只是區分易讀的)這八個字符罷了。這個正則里的連接字符,是哪些范圍呢?很明顯,這里的連接字符的范圍是【)-c】,“)”ASCII碼為0×29,也就是十進制的41;“c”的ASCII碼為0×63,也就是十進制的99,那么,他這個連接字符的范圍就是ASCII 41(chr(41))到ASCII 99(chr(99))之間的字符。也就是說,這位網友的正則的范圍是【[hr)-c(]】,就是chr(41)到chr(99)外加hr這兩個字母和前面的“(”。
網友第一次測試的時候,有修飾符i,意思就是說,不區分大小寫,那么在chr(41)到chr(99)之間的字符,以及這些字符如果有大小寫,則包括他們的大小寫都符合匹配。都會被替換成空。其第二次測試的時候,去掉了修飾符i,進行了不區分大小寫的匹配,由于其范圍只到c,但突然,再除了小寫字母的“h”、“r”,所以,測試結果會多出“defgijklmnopqstuvwxyz”。所以,他的結果出現了這些差別。

網友的表達式等同于如下圖所示

解決辦法:
錯誤的原因找出來了,那么,解決的辦法呢?
我們先來看看這位網友的需求,他的需求是將unicode(ASCII只是0-127位的,128之后的,應該叫UNICODE碼)的chr(128)到chr(255)之間的字符匹配,替換為空罷了。正則表達式里,對十六進制的字符匹配的表示方式有兩種,【/u】和【/x{}】,前者只能表示【/u】后面4位的十六進制數值,而后者【/x{}】則可以表示任意多的十六進制位數(寫在大括號中)。
那么,這個正則表達式該如何寫????
網友的目的是chr(128)到chr(255),那么就是【[/u0080-/u00FF]】或者【[/x{0080}-/x{00FF}]】。
其目的是匹配下圖中的紅框內字符

提醒一下,PHP里正則匹配unicode字符時,需要使用u修飾符。
根據網友需求,更改正則之后的PHP代碼如下:
復制代碼代碼如下:
$words = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSRUVWXYZ!@#$%^&*()_+-=[]//,./{}|<>?'/"你好啊我們";
$otherStr=preg_replace("//[/x{0080}-/x{00FF}]+/iu"," ",$words);
echo 'otherStr:',$otherStr;
其運行結果是仍然輸出那段字符串,為什么呢?因為哪些字符串都不在chr(128)到chr(255)的范圍之內。
(測試時,注意文件編碼為UTF-8)
以上為鄙人愚見,歡迎批評指正。