超文本傳輸協(xié)議http構(gòu)成了萬維網(wǎng)的基礎(chǔ),它利用URI(統(tǒng)一資源標(biāo)識符)來識別Internet上的數(shù)據(jù),而指定文檔地址的URI被稱為URL(既統(tǒng)一資源定位符),常見的URL指向文件、目錄或者執(zhí)行復(fù)雜任務(wù)的對象(如數(shù)據(jù)庫查找,internet搜索),而爬蟲實質(zhì)上正是通過對這些url進行訪問、操作,從而獲取我們想要的內(nèi)容。對于沒有商業(yè)需求的我們而言,想要編寫爬蟲的話,使用urllib,urllib2與cookielib三個模塊便可以完成很多需求了。
首先要說明的是,urllib2并非是urllib的升級版,雖然同樣作為處理url的相關(guān)模塊,個人推薦盡量使用urllib2的接口,但我們并不能用urllib2完全代替urllib,處理URL資源有時會需要urllib中的一些函數(shù)(如urllib.urllencode)來處理數(shù)據(jù)。但二者處理url的大致思想都是通過底層封裝好的接口讓我們能夠?qū)rl像對本地文件一樣進行讀取等操作。
下面就是一個獲取百度頁面內(nèi)容的代碼:
import urllib2 connect= urllib2.Request('http://www.baidu.com') url1 = urllib2.urlopen(connect) print url.read() 短短4行在運行之后,就會顯示出百度頁面的源代碼。它的機理是什么呢?
當(dāng)我們使用urllib2.Request的命令時,我們就向百度搜索的url(“www.baidu.com”)發(fā)出了一次HTTP請求,并將該請求映射到connect變量中,當(dāng)我們使用urllib2.urlopen操作connect后,就會將connect的值返回到url1中,然后我們就可以像操作本地文件一樣對url1進行操作,比如這里我們就使用了read()函數(shù)來讀取該url的源代碼。
這樣,我們就可以寫一只屬于自己的簡單爬蟲了~下面是我寫的抓取天涯連載的爬蟲:
import urllib2 url1="http://bbs.tianya.cn/post-16-835537-" url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB" for i in range(1,481): a=urllib2.Request(url1+str(i)+url3) b=urllib2.urlopen(a) path=str("D:/noval/天眼傳人"+str(i)+".html") c=open(path,"w+") code=b.read() c.write(code) c.close print "當(dāng)前下載頁數(shù):",i 事實上,上面的代碼使用urlopen就可以達到相同的效果了:
import urllib2 url1="http://bbs.tianya.cn/post-16-835537-" url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB" for i in range(1,481): #a=urllib2.Request(url1+str(i)+url3) b=urllib2.urlopen((url1+str(i)+url3) path=str("D:/noval/天眼傳人"+str(i)+".html") c=open(path,"w+") code=b.read() c.write(code) c.close print "當(dāng)前下載頁數(shù):",i 為什么我們還需要先對url進行request處理呢?這里需要引入opener的概念,當(dāng)我們使用urllib處理url的時候,實際上是通過urllib2.OpenerDirector實例進行工作,他會自己調(diào)用資源進行各種操作如通過協(xié)議、打開url、處理cookie等。而urlopen方法使用的是默認的opener來處理問題,也就是說,相當(dāng)?shù)暮唵未直﹡對于我們post數(shù)據(jù)、設(shè)置header、設(shè)置代理等需求完全滿足不了。
因此,當(dāng)面對稍微高點的需求時,我們就需要通過urllib2.build_opener()來創(chuàng)建屬于自己的opener,這部分內(nèi)容我會在下篇博客中詳細寫~
而對于一些沒有特別要求的網(wǎng)站,僅僅使用urllib的2個模塊其實就可以獲取到我們想要的信息了,但是一些需要模擬登陸或者需要權(quán)限的網(wǎng)站,就需要我們處理cookies后才能順利抓取上面的信息,這時候就需要Cookielib模塊了。cookielib 模塊就是專門用來處理cookie相關(guān)了,其中比較常用的方法就是能夠自動處理cookie的CookieJar()了,它可以自動存儲HTTP請求生成的cookie,并向傳出HTTP的請求中自動添加cookie。正如我前文所提到的,想要使用它的話,需要創(chuàng)建一個新的opener:
import cookielib, urllib2 cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
經(jīng)過這樣的處理后,cookie的問題就解決了~
而想要將cookies輸出出來的話,使用print cj._cookies.values()命令后就可以了~
抓取豆瓣同城、登陸圖書館查詢圖書歸還
在掌握了urllib幾個模塊的相關(guān)用法后,接下來就是進入實戰(zhàn)步驟了~
(一)抓取豆瓣網(wǎng)站同城活動
豆瓣北京同城活動 該鏈接指向豆瓣同城活動的列表,向該鏈接發(fā)起request:
# encoding=utf-8 import urllib import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) url="http://beijing.douban.com/events/future-all?start=0" req=urllib2.Request(url) event=urllib2.urlopen(req) str1=event.read()
我們會發(fā)現(xiàn)返回的html代碼中,除了我們需要的信息之外,還夾雜了大量的頁面布局代碼:
")
如上圖所示,我們只需要中間那些關(guān)于活動的信息。而為了提取信息,我們就需要正則表達式了~
正則表達式是一種跨平臺的字符串處理工具/方法,通過正則表達式,我們可以比較輕松的提取字符串中我們想要的內(nèi)容~
這里不做詳細介紹了,個人推薦余晟老師的正則指引,挺適合新手入門的。下面給出正則表達式的大致語法:
")
這里我使用捕獲分組,將活動四要素(名稱,時間,地點,費用)為標(biāo)準(zhǔn)進行分組,得到的表達式如下:
regex=re.compile(r'summary">([/d/D]*?)</span>[/d/D]*?class="hidden-xs">([/d/D]*?)<time[/d/D]*?<li style="margin: 0px; padding: 0px; width: 660px; overflow: hidden; clear: both;"> 這樣就可以將幾個部分提取出來了。
總體代碼如下:
# -*- coding: utf-8 -*- #--------------------------------------- # program:豆瓣同城爬蟲 # author:GisLu # data:2014-02-08 #--------------------------------------- import urllib import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) #正則提取 def search(str1): regex=re.compile(r'summary">([/d/D]*?)</span>[/d/D]*?class="hidden-xs">([/d/D]*?)<time[/d/D]*?<li for i in regex.finditer(str1): print "活動名稱:",i.group(1) a=i.group(2) b=a.replace('</span>','') print b.replace('/n','') print '活動地點:',i.group(3) c=i.group(4).decode('utf-8') print '費用:',c #獲取url for i in range(0,5): url="http://beijing.douban.com/events/future-all?start=" url=url+str(i*10) req=urllib2.Request(url) event=urllib2.urlopen(req) str1=event.read() search(str1) 在這里需要注意一下編碼的問題,因為我使用的版本還是python2.X,所以在內(nèi)部漢字字符串傳遞的時候需要來回轉(zhuǎn)換,比如在最后打印“費用“這一項的時候,必須使用
i.group(4).decode('utf-8') 將group(4元組中的ASCII碼轉(zhuǎn)換為utf8格式才行,否則會發(fā)現(xiàn)輸出的是亂碼。
而在python中,正則模塊re提供了兩種常用的全局查找方式:findall 和 finditer,其中findall是一次性處理完畢,比較消耗資源;而finditer則是迭代進行搜索,個人比較推薦使用這一方法。
最后得到的結(jié)果如下,大功告成~
")
(二)模擬登陸圖書館系統(tǒng)查詢書籍歸還情況
既然我們能夠通過python向指定網(wǎng)站發(fā)出請求獲取信息,那么自然也能通過python模擬瀏覽器進行登陸等操作~
而模擬的關(guān)鍵,就在于我們向指定網(wǎng)站服務(wù)器發(fā)送的信息需要和瀏覽器的格式一模一樣才行~
這就需要分析出我們想要登陸的那個網(wǎng)站接受信息的方式。通常我們需要對瀏覽器的信息交換進行抓包~
抓包軟件中,目前比較流行的是wireshark,相當(dāng)強大~不過對于我們新手來說,IE、Foxfire或者chrome自帶的工具就足夠我們使用了~
這里就以本人學(xué)校的圖書館系統(tǒng)為例子~
")
我們可以通過模擬登陸,最后進入圖書管理系統(tǒng)查詢我們借閱的圖書歸還情況。首先要進行抓包分析我們需要發(fā)送哪些信息才能成功模擬瀏覽器進行登陸操作。
")
我使用的是chrome瀏覽器,在登陸頁面按F12調(diào)出chrome自帶的開發(fā)工具,選擇network項就可以輸入學(xué)號密碼選擇登陸了。
觀察登陸過程中的網(wǎng)絡(luò)活動,果然發(fā)現(xiàn)可疑分子了:
")
分析這個post指令后,可以確認其就是發(fā)送登陸信息(賬號、密碼等)的關(guān)鍵命令。
還好我們學(xué)校比較窮,網(wǎng)站做的一般,這個包完全沒有加密~那么剩下的就很簡單了~記下headers跟post data就OK了~
其中headers中有很多實用的信息,一些網(wǎng)站可能會根據(jù)user-Agent來判斷你是否是爬蟲程序從而決定是否允許你訪問,而Referer則是很多網(wǎng)站常常用來反盜鏈的,如果服務(wù)器接收到的請求中referer與管理員設(shè)定的規(guī)則不符,那么服務(wù)器也會拒絕發(fā)送資源。
而post data就是我們在登錄過程中瀏覽器向登陸服務(wù)器post的信息了,通常賬戶、密碼之類的數(shù)據(jù)都包含在里面。這里往往還有一些其他的數(shù)據(jù)如布局等信息也要發(fā)送出去,這些信息通常我們在操作瀏覽器的時候沒有任何存在感,但沒了他們服務(wù)器是不會響應(yīng)我們滴。
")
")
現(xiàn)在postdata 跟headers的格式我們?nèi)恐懒藒模擬登陸就很簡單了:
import urllib #--------------------------------------- # @program:圖書借閱查詢 # @author:GisLu # @data:2014-02-08 #--------------------------------------- import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')] urllib2.install_opener(opener) #登陸獲取cookies postdata=urllib.urlencode({ 'user':'X1234564', 'pw':'demacialalala', 'imageField.x':'0', 'imageField.y':'0'}) rep=urllib2.Request( url='http://210.45.210.6/dzjs/login.asp', data=postdata ) result=urllib2.urlopen(rep) print result.geturl()
其中urllib.urlencode負責(zé)將postdata自動進行格式轉(zhuǎn)換,而opener.addheaders則是在我們的opener處理器中為后續(xù)請求添加我們預(yù)設(shè)的headers。
測試后發(fā)現(xiàn),登陸成功~~
那么剩下的就是找出圖書借還查詢所在頁面的url,再用正則表達式提取出我們需要的信息了~~
整體代碼如下:
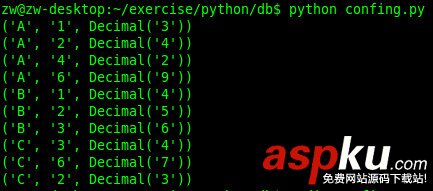
import urllib #--------------------------------------- # @program:圖書借閱查詢 # @author:GisLu # @data:2014-02-08 #--------------------------------------- import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')] urllib2.install_opener(opener) #登陸獲取cookies postdata=urllib.urlencode({ 'user':'X11134564', 'pw':'demacialalala', 'imageField.x':'0', 'imageField.y':'0'}) rep=urllib2.Request( url='http://210.45.210.6/dzjs/login.asp', data=postdata ) result=urllib2.urlopen(rep) print result.geturl() #獲取賬目表 Postdata=urllib.urlencode({ 'nCxfs':'1', 'submit1':'檢索'}) aa=urllib2.Request( url='http://210.45.210.6/dzjs/jhcx.asp', data=Postdata ) bb=urllib2.urlopen(aa) cc=bb.read() zhangmu=re.findall('tdborder4 >(.*?)</td>',cc) for i in zhangmu: i=i.decode('gb2312') i=i.encode('gb2312') print i.strip(' ') 下面是程序運行結(jié)果~
")