以前寫過一個(gè)刷校內(nèi)網(wǎng)的人氣的工具,Java的(以后再也不行Java程序了),里面用到了驗(yàn)證碼識(shí)別,那段代碼不是我自己寫的:-) 校內(nèi)的驗(yàn)證是完全單色沒有任何干撓的驗(yàn)證碼,識(shí)別起來比較容易,不過從那段代碼中可以看到基本的驗(yàn)證碼識(shí)別方式。這幾天在寫一個(gè)程序的時(shí)候需要識(shí)別驗(yàn)證碼,因?yàn)槌绦蚴荘ython寫的自然打算用Python進(jìn)行驗(yàn)證碼的識(shí)別。
以前沒用Python處理過圖像,不太了解PIL(Python Image Library)的用法,這幾天看了看PIL,發(fā)現(xiàn)它太強(qiáng)大了,簡(jiǎn)直和ImageMagic,PS可以相比了。(這里有PIL不錯(cuò)的文檔)
由于上面的驗(yàn)證碼是24位的jpeg圖像,并且包含了噪點(diǎn),所以我們要做的就是去噪和去色,我拿PS找了張驗(yàn)證碼試了試,使用PS濾鏡中的去噪效果還行, 但是沒有在PIL找到去噪的函數(shù),后來發(fā)現(xiàn)中值過濾后可以去掉大部分的噪點(diǎn),而且PIL里有現(xiàn)成的函數(shù),接下來我試著直接把圖像轉(zhuǎn)換為單色,結(jié)果發(fā)現(xiàn)還是 會(huì)有不過的噪點(diǎn)留了下來,因?yàn)橹兄颠^濾時(shí)把不少噪點(diǎn)淡化了,但轉(zhuǎn)換為音色時(shí)這些噪點(diǎn)又被強(qiáng)化顯示了,于是在中值過濾后對(duì)圖像亮度進(jìn)行加強(qiáng)處理,然后再轉(zhuǎn)換 為單色,這樣驗(yàn)證碼圖片就變得比較容易識(shí)別了:
上面這些處理使用Python才幾行:
im = Image.open(image_name)im = im.filter(ImageFilter.MedianFilter())enhancer = ImageEnhance.Contrast(im)im = enhancer.enhance(2)im = im.convert('1')im.show() 接下來就是提取這些數(shù)字的字模,使用shell腳本下載100幅圖片,抽出三張圖片獲取字模:
#!/usr/bin/env python#encoding=utf-8import Image,ImageEnhance,ImageFilterimport sysimage_name = "./images/81.jpeg"im = Image.open(image_name)im = im.filter(ImageFilter.MedianFilter())enhancer = ImageEnhance.Contrast(im)im = enhancer.enhance(2)im = im.convert('1')#im.show()#all by pixels = 12 #start postion of first numberw = 10 #width of each numberh = 15 #end postion from topt = 2 #start postion of topim_new = []#split four numbers in the picturefor i in range(4):im1 = im.crop((s+w*i+i*2,t,s+w*(i+1)+i*2,h))im_new.append(im1)f = file("data.txt","a")for k in range(4):l = []#im_new[k].show()for i in range(13):for j in range(10):if (im_new[k].getpixel((j,i)) == 255):l.append(0)else:l.append(1)f.write("l=[")n = 0for i in l:if (n%10==0):f.write("/n")f.write(str(i)+",")n+=1f.write("]/n") 把字模保存為list,用于接下來的匹配;
提取完字模后剩下來的就是對(duì)需要處理的圖片進(jìn)行與數(shù)據(jù)庫中的字模進(jìn)行匹配了,基本的思路就是看相應(yīng)點(diǎn)的重合率,但是由于噪點(diǎn)的影響在對(duì)(6,8) (8,3)(5,9)的匹配時(shí)容易出錯(cuò),俺自己針對(duì)已有的100幅圖片數(shù)據(jù)采集進(jìn)行分析,采用了雙向匹配(圖片與字模分別作為基點(diǎn)),做了半天的測(cè)試終于 可以實(shí)現(xiàn)100%的識(shí)別率。
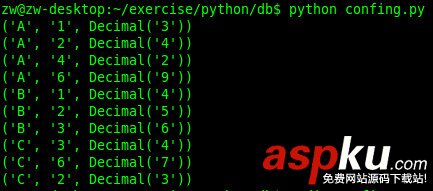
#!/usr/bin/env python#encoding=utf-8import Image,ImageEnhance,ImageFilterimport DataDEBUG = Falsedef d_print(*msg):global DEBUGif DEBUG:for i in msg:print i,printelse:passdef Get_Num(l=[]):min1 = []min2 = []for n in Data.N:count1=count2=count3=count4=0if (len(l) != len(n)):print "Wrong pic"exit()for i in range(len(l)):if (l[i] == 1):count1+=1if (n[i] == 1):count2+=1for i in range(len(l)):if (n[i] == 1):count3+=1if (l[i] == 1):count4+=1d_print(count1,count2,count3,count4)min1.append(count1-count2)min2.append(count3-count4)d_print(min1,"/n",min2)for i in range(10):if (min1[i] <= 2 or min2[i] <= 2):if ((abs(min1[i] - min2[i])) <10):return ifor i in range(10): if (min1[i] <= 4 or min2[i] <= 4):if (abs(min1[i] - min2[i]) <= 2):return ifor i in range(10):flag = Falseif (min1[i] <= 3 or min2[i] <= 3):for j in range(10):if (j != i and (min1[j] <5 or min2[j] <5)):flag = Trueelse:passif (not flag):return ifor i in range(10): if (min1[i] <= 5 or min2[i] <= 5):if (abs(min1[i] - min2[i]) <= 10):return ifor i in range(10):if (min1[i] <= 10 or min2[i] <= 10):if (abs(min1[i] - min2[i]) <= 3):return i#end of function Get_Numdef Pic_Reg(image_name=None):im = Image.open(image_name)im = im.filter(ImageFilter.MedianFilter())enhancer = ImageEnhance.Contrast(im)im = enhancer.enhance(2)im = im.convert('1')im.show()#all by pixels = 12 #start postion of first numberw = 10 #width of each numberh = 15 #end postion from topt = 2 #start postion of topim_new = []#split four numbers in the picturefor i in range(4):im1 = im.crop((s+w*i+i*2,t,s+w*(i+1)+i*2,h))im_new.append(im1)s = ""for k in range(4):l = []#im_new[k].show()for i in range(13):for j in range(10):if (im_new[k].getpixel((j,i)) == 255):l.append(0)else:l.append(1)s+=str(Get_Num(l))return sprint Pic_Reg("./images/22.jpeg") 這里再提一下驗(yàn)證碼識(shí)別的基本方法:截圖,二值化、中值濾波去噪、分割、緊縮重排(讓高矮統(tǒng)一)、字庫特征匹配識(shí)別。
這里只是針對(duì)一般的驗(yàn)證碼,高級(jí)驗(yàn)證碼的識(shí)別這里有篇不錯(cuò)的文章,太復(fù)雜的話涉及的東西就多了,那俺就沒興趣了,人工智能(好恐怖),俺只喜歡簡(jiǎn)單的東西。