 王小龍數(shù)學話題優(yōu)秀回答者 數(shù)學,計算機視覺,圖形圖像處理收錄于 知乎周刊 、 編輯推薦 ?4320 人贊同神經(jīng)網(wǎng)絡很萌的!0. 分類神經(jīng)網(wǎng)絡最重要的用途是分類,為了讓大家對分類有個直觀的認識,咱們先看幾個例子:垃圾郵件識別:現(xiàn)在有一封電子郵件,把出現(xiàn)在里面的所有詞匯提取出來,送進一個機器里,機器需要判斷這封郵件是否是垃圾郵件。疾病判斷:病人到醫(yī)院去做了一大堆肝功、尿檢測驗,把測驗結(jié)果送進一個機器里,機器需要判斷這個病人是否得病,得的什么病。貓狗分類:有一大堆貓、狗照片,把每一張照片送進一個機器里,機器需要判斷這幅照片里的東西是貓還是狗。這種能自動對輸入的東西進行分類的機器,就叫做分類器。分類器的輸入是一個數(shù)值向量,叫做特征(向量)。在第一個例子里,分類器的輸入是一堆0、1值,表示字典里的每一個詞是否在郵件中出現(xiàn),比如向量(1,1,0,0,0......)就表示這封郵件里只出現(xiàn)了兩個詞abandon和abnormal;第二個例子里,分類器的輸入是一堆化驗指標;第三個例子里,分類器的輸入是照片,假如每一張照片都是320*240像素的紅綠藍三通道彩色照片,那么分類器的輸入就是一個長度為320*240*3=230400的向量。分類器的輸出也是數(shù)值。第一個例子中,輸出1表示郵件是垃圾郵件,輸出0則說明郵件是正常郵件;第二個例子中,輸出0表示健康,輸出1表示有甲肝,輸出2表示有乙肝,輸出3表示有餅干等等;第三個例子中,輸出0表示圖片中是狗,輸出1表示是貓。分類器的目標就是讓正確分類的比例盡可能高。一般我們需要首先收集一些樣本,人為標記上正確分類結(jié)果,然后用這些標記好的數(shù)據(jù)訓練分類器,訓練好的分類器就可以在新來的特征向量上工作了。1. 神經(jīng)元咱們假設分類器的輸入是通過某種途徑獲得的兩個值,輸出是0和1,比如分別代表貓和狗。現(xiàn)在有一些樣本:大家想想,最簡單地把這兩組特征向量分開的方法是啥?當然是在兩組數(shù)據(jù)中間畫一條豎直線,直線左邊是狗,右邊是貓,分類器就完成了。以后來了新的向量,凡是落在直線左邊的都是狗,落在右邊的都是貓。一條直線把平面一分為二,一個平面把三維空間一分為二,一個n-1維超平面把n維空間一分為二,兩邊分屬不同的兩類,這種分類器就叫做神經(jīng)元。大家都知道平面上的直線方程是
王小龍數(shù)學話題優(yōu)秀回答者 數(shù)學,計算機視覺,圖形圖像處理收錄于 知乎周刊 、 編輯推薦 ?4320 人贊同神經(jīng)網(wǎng)絡很萌的!0. 分類神經(jīng)網(wǎng)絡最重要的用途是分類,為了讓大家對分類有個直觀的認識,咱們先看幾個例子:垃圾郵件識別:現(xiàn)在有一封電子郵件,把出現(xiàn)在里面的所有詞匯提取出來,送進一個機器里,機器需要判斷這封郵件是否是垃圾郵件。疾病判斷:病人到醫(yī)院去做了一大堆肝功、尿檢測驗,把測驗結(jié)果送進一個機器里,機器需要判斷這個病人是否得病,得的什么病。貓狗分類:有一大堆貓、狗照片,把每一張照片送進一個機器里,機器需要判斷這幅照片里的東西是貓還是狗。這種能自動對輸入的東西進行分類的機器,就叫做分類器。分類器的輸入是一個數(shù)值向量,叫做特征(向量)。在第一個例子里,分類器的輸入是一堆0、1值,表示字典里的每一個詞是否在郵件中出現(xiàn),比如向量(1,1,0,0,0......)就表示這封郵件里只出現(xiàn)了兩個詞abandon和abnormal;第二個例子里,分類器的輸入是一堆化驗指標;第三個例子里,分類器的輸入是照片,假如每一張照片都是320*240像素的紅綠藍三通道彩色照片,那么分類器的輸入就是一個長度為320*240*3=230400的向量。分類器的輸出也是數(shù)值。第一個例子中,輸出1表示郵件是垃圾郵件,輸出0則說明郵件是正常郵件;第二個例子中,輸出0表示健康,輸出1表示有甲肝,輸出2表示有乙肝,輸出3表示有餅干等等;第三個例子中,輸出0表示圖片中是狗,輸出1表示是貓。分類器的目標就是讓正確分類的比例盡可能高。一般我們需要首先收集一些樣本,人為標記上正確分類結(jié)果,然后用這些標記好的數(shù)據(jù)訓練分類器,訓練好的分類器就可以在新來的特征向量上工作了。1. 神經(jīng)元咱們假設分類器的輸入是通過某種途徑獲得的兩個值,輸出是0和1,比如分別代表貓和狗。現(xiàn)在有一些樣本:大家想想,最簡單地把這兩組特征向量分開的方法是啥?當然是在兩組數(shù)據(jù)中間畫一條豎直線,直線左邊是狗,右邊是貓,分類器就完成了。以后來了新的向量,凡是落在直線左邊的都是狗,落在右邊的都是貓。一條直線把平面一分為二,一個平面把三維空間一分為二,一個n-1維超平面把n維空間一分為二,兩邊分屬不同的兩類,這種分類器就叫做神經(jīng)元。大家都知道平面上的直線方程是 ,等式左邊大于零和小于零分別表示點
,等式左邊大于零和小于零分別表示點 在直線的一側(cè)還是另一側(cè),把這個式子推廣到n維空間里,直線的高維形式稱為超平面,它的方程是:
在直線的一側(cè)還是另一側(cè),把這個式子推廣到n維空間里,直線的高維形式稱為超平面,它的方程是: 神經(jīng)元就是當h大于0時輸出1,h小于0時輸出0這么一個模型,它的實質(zhì)就是把特征空間一切兩半,認為兩瓣分別屬兩個類。你恐怕再也想不到比這更簡單的分類器了,它是McCulloch和Pitts在1943年想出來了。這個模型有點像人腦中的神經(jīng)元:從多個感受器接受電信號
神經(jīng)元就是當h大于0時輸出1,h小于0時輸出0這么一個模型,它的實質(zhì)就是把特征空間一切兩半,認為兩瓣分別屬兩個類。你恐怕再也想不到比這更簡單的分類器了,它是McCulloch和Pitts在1943年想出來了。這個模型有點像人腦中的神經(jīng)元:從多個感受器接受電信號 ,進行處理(加權(quán)相加再偏移一點,即判斷輸入是否在某條直線
,進行處理(加權(quán)相加再偏移一點,即判斷輸入是否在某條直線 的一側(cè)),發(fā)出電信號(在正確的那側(cè)發(fā)出1,否則不發(fā)信號,可以認為是發(fā)出0),這就是它叫神經(jīng)元的原因。當然,上面那幅圖我們是開了上帝視角才知道“一條豎直線能分開兩類”,在實際訓練神經(jīng)元時,我們并不知道特征是怎么抱團的。神經(jīng)元模型的一種學習方法稱為Hebb算法:先隨機選一條直線/平面/超平面,然后把樣本一個個拿過來,如果這條直線分錯了,說明這個點分錯邊了,就稍微把直線移動一點,讓它靠近這個樣本,爭取跨過這個樣本,讓它跑到直線正確的一側(cè);如果直線分對了,它就暫時停下不動。因此訓練神經(jīng)元的過程就是這條直線不斷在跳舞,最終跳到兩個類之間的豎直線位置。2. 神經(jīng)網(wǎng)絡MP神經(jīng)元有幾個顯著缺點。首先它把直線一側(cè)變?yōu)?,另一側(cè)變?yōu)?,這東西不可微,不利于數(shù)學分析。人們用一個和0-1階躍函數(shù)類似但是更平滑的函數(shù)Sigmoid函數(shù)來代替它(Sigmoid函數(shù)自帶一個尺度參數(shù),可以控制神經(jīng)元對離超平面距離不同的點的響應,這里忽略它),從此神經(jīng)網(wǎng)絡的訓練就可以用梯度下降法來構(gòu)造了,這就是有名的反向傳播算法。神經(jīng)元的另一個缺點是:它只能切一刀!你給我說說一刀怎么能把下面這兩類分開吧。解決辦法是多層神經(jīng)網(wǎng)絡,底層神經(jīng)元的輸出是高層神經(jīng)元的輸入。我們可以在中間橫著砍一刀,豎著砍一刀,然后把左上和右下的部分合在一起,與右上的左下部分分開;也可以圍著左上角的邊沿砍10刀把這一部分先挖出來,然后和右下角合并。每砍一刀,其實就是使用了一個神經(jīng)元,把不同砍下的半平面做交、并等運算,就是把這些神經(jīng)元的輸出當作輸入,后面再連接一個神經(jīng)元。這個例子中特征的形狀稱為異或,這種情況一個神經(jīng)元搞不定,但是兩層神經(jīng)元就能正確對其進行分類。只要你能砍足夠多刀,把結(jié)果拼在一起,什么奇怪形狀的邊界神經(jīng)網(wǎng)絡都能夠表示,所以說神經(jīng)網(wǎng)絡在理論上可以表示很復雜的函數(shù)/空間分布。但是真實的神經(jīng)網(wǎng)絡是否能擺動到正確的位置還要看網(wǎng)絡初始值設置、樣本容量和分布。神經(jīng)網(wǎng)絡神奇的地方在于它的每一個組件非常簡單——把空間切一刀+某種激活函數(shù)(0-1階躍、sigmoid、max-pooling),但是可以一層一層級聯(lián)。輸入向量連到許多神經(jīng)元上,這些神經(jīng)元的輸出又連到一堆神經(jīng)元上,這一過程可以重復很多次。這和人腦中的神經(jīng)元很相似:每一個神經(jīng)元都有一些神經(jīng)元作為其輸入,又是另一些神經(jīng)元的輸入,數(shù)值向量就像是電信號,在不同神經(jīng)元之間傳導,每一個神經(jīng)元只有滿足了某種條件才會發(fā)射信號到下一層神經(jīng)元。當然,人腦比神經(jīng)網(wǎng)絡模型復雜很多:人工神經(jīng)網(wǎng)絡一般不存在環(huán)狀結(jié)構(gòu);人腦神經(jīng)元的電信號不僅有強弱,還有時間緩急之分,就像莫爾斯電碼,在人工神經(jīng)網(wǎng)絡里沒有這種復雜的信號模式。神經(jīng)網(wǎng)絡的訓練依靠反向傳播算法:最開始輸入層輸入特征向量,網(wǎng)絡層層計算獲得輸出,輸出層發(fā)現(xiàn)輸出和正確的類號不一樣,這時它就讓最后一層神經(jīng)元進行參數(shù)調(diào)整,最后一層神經(jīng)元不僅自己調(diào)整參數(shù),還會勒令連接它的倒數(shù)第二層神經(jīng)元調(diào)整,層層往回退著調(diào)整。經(jīng)過調(diào)整的網(wǎng)絡會在樣本上繼續(xù)測試,如果輸出還是老分錯,繼續(xù)來一輪回退調(diào)整,直到網(wǎng)絡輸出滿意為止。這很像中國的文藝體制,武媚娘傳奇劇組就是網(wǎng)絡中的一個神經(jīng)元,最近剛剛調(diào)整了參數(shù)。3. 大型神經(jīng)網(wǎng)絡我們不禁要想了,假如我們的這個網(wǎng)絡有10層神經(jīng)元,第8層第2015個神經(jīng)元,它有什么含義呢?我們知道它把第七層的一大堆神經(jīng)元的輸出作為輸入,第七層的神經(jīng)元又是以第六層的一大堆神經(jīng)元做為輸入,那么這個特殊第八層的神經(jīng)元,它會不會代表了某種抽象的概念?就好比你的大腦里有一大堆負責處理聲音、視覺、觸覺信號的神經(jīng)元,它們對于不同的信息會發(fā)出不同的信號,那么會不會有這么一個神經(jīng)元(或者神經(jīng)元小集團),它收集這些信號,分析其是否符合某個抽象的概念,和其他負責更具體和更抽象概念的神經(jīng)元進行交互。2012年多倫多大學的Krizhevsky等人構(gòu)造了一個超大型卷積神經(jīng)網(wǎng)絡[1],有9層,共65萬個神經(jīng)元,6千萬個參數(shù)。網(wǎng)絡的輸入是圖片,輸出是1000個類,比如小蟲、美洲豹、救生船等等。這個模型的訓練需要海量圖片,它的分類準確率也完爆先前所有分類器。紐約大學的Zeiler和Fergusi[2]把這個網(wǎng)絡中某些神經(jīng)元挑出來,把在其上響應特別大的那些輸入圖像放在一起,看它們有什么共同點。他們發(fā)現(xiàn)中間層的神經(jīng)元響應了某些十分抽象的特征。第一層神經(jīng)元主要負責識別顏色和簡單紋理第二層的一些神經(jīng)元可以識別更加細化的紋理,比如布紋、刻度、葉紋。第三層的一些神經(jīng)元負責感受黑夜里的黃色燭光、雞蛋黃、高光。第四層的一些神經(jīng)元負責識別萌狗的臉、七星瓢蟲和一堆圓形物體的存在。第五層的一些神經(jīng)元可以識別出花、圓形屋頂、鍵盤、鳥、黑眼圈動物。這里面的概念并不是整個網(wǎng)絡的輸出,是網(wǎng)絡中間層神經(jīng)元的偏好,它們?yōu)楹竺娴纳窠?jīng)元服務。雖然每一個神經(jīng)元都傻不拉幾的(只會切一刀),但是65萬個神經(jīng)元能學到的東西還真是深邃呢。[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information PRocessing systems (pp. 1097-1105).[2] Zeiler, M. D., & Fergus, R. (2013). Visualizing and understanding convolutional neural networks.arXiv preprint arXiv:1311.2901.編輯于 2015-01-05 215 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
的一側(cè)),發(fā)出電信號(在正確的那側(cè)發(fā)出1,否則不發(fā)信號,可以認為是發(fā)出0),這就是它叫神經(jīng)元的原因。當然,上面那幅圖我們是開了上帝視角才知道“一條豎直線能分開兩類”,在實際訓練神經(jīng)元時,我們并不知道特征是怎么抱團的。神經(jīng)元模型的一種學習方法稱為Hebb算法:先隨機選一條直線/平面/超平面,然后把樣本一個個拿過來,如果這條直線分錯了,說明這個點分錯邊了,就稍微把直線移動一點,讓它靠近這個樣本,爭取跨過這個樣本,讓它跑到直線正確的一側(cè);如果直線分對了,它就暫時停下不動。因此訓練神經(jīng)元的過程就是這條直線不斷在跳舞,最終跳到兩個類之間的豎直線位置。2. 神經(jīng)網(wǎng)絡MP神經(jīng)元有幾個顯著缺點。首先它把直線一側(cè)變?yōu)?,另一側(cè)變?yōu)?,這東西不可微,不利于數(shù)學分析。人們用一個和0-1階躍函數(shù)類似但是更平滑的函數(shù)Sigmoid函數(shù)來代替它(Sigmoid函數(shù)自帶一個尺度參數(shù),可以控制神經(jīng)元對離超平面距離不同的點的響應,這里忽略它),從此神經(jīng)網(wǎng)絡的訓練就可以用梯度下降法來構(gòu)造了,這就是有名的反向傳播算法。神經(jīng)元的另一個缺點是:它只能切一刀!你給我說說一刀怎么能把下面這兩類分開吧。解決辦法是多層神經(jīng)網(wǎng)絡,底層神經(jīng)元的輸出是高層神經(jīng)元的輸入。我們可以在中間橫著砍一刀,豎著砍一刀,然后把左上和右下的部分合在一起,與右上的左下部分分開;也可以圍著左上角的邊沿砍10刀把這一部分先挖出來,然后和右下角合并。每砍一刀,其實就是使用了一個神經(jīng)元,把不同砍下的半平面做交、并等運算,就是把這些神經(jīng)元的輸出當作輸入,后面再連接一個神經(jīng)元。這個例子中特征的形狀稱為異或,這種情況一個神經(jīng)元搞不定,但是兩層神經(jīng)元就能正確對其進行分類。只要你能砍足夠多刀,把結(jié)果拼在一起,什么奇怪形狀的邊界神經(jīng)網(wǎng)絡都能夠表示,所以說神經(jīng)網(wǎng)絡在理論上可以表示很復雜的函數(shù)/空間分布。但是真實的神經(jīng)網(wǎng)絡是否能擺動到正確的位置還要看網(wǎng)絡初始值設置、樣本容量和分布。神經(jīng)網(wǎng)絡神奇的地方在于它的每一個組件非常簡單——把空間切一刀+某種激活函數(shù)(0-1階躍、sigmoid、max-pooling),但是可以一層一層級聯(lián)。輸入向量連到許多神經(jīng)元上,這些神經(jīng)元的輸出又連到一堆神經(jīng)元上,這一過程可以重復很多次。這和人腦中的神經(jīng)元很相似:每一個神經(jīng)元都有一些神經(jīng)元作為其輸入,又是另一些神經(jīng)元的輸入,數(shù)值向量就像是電信號,在不同神經(jīng)元之間傳導,每一個神經(jīng)元只有滿足了某種條件才會發(fā)射信號到下一層神經(jīng)元。當然,人腦比神經(jīng)網(wǎng)絡模型復雜很多:人工神經(jīng)網(wǎng)絡一般不存在環(huán)狀結(jié)構(gòu);人腦神經(jīng)元的電信號不僅有強弱,還有時間緩急之分,就像莫爾斯電碼,在人工神經(jīng)網(wǎng)絡里沒有這種復雜的信號模式。神經(jīng)網(wǎng)絡的訓練依靠反向傳播算法:最開始輸入層輸入特征向量,網(wǎng)絡層層計算獲得輸出,輸出層發(fā)現(xiàn)輸出和正確的類號不一樣,這時它就讓最后一層神經(jīng)元進行參數(shù)調(diào)整,最后一層神經(jīng)元不僅自己調(diào)整參數(shù),還會勒令連接它的倒數(shù)第二層神經(jīng)元調(diào)整,層層往回退著調(diào)整。經(jīng)過調(diào)整的網(wǎng)絡會在樣本上繼續(xù)測試,如果輸出還是老分錯,繼續(xù)來一輪回退調(diào)整,直到網(wǎng)絡輸出滿意為止。這很像中國的文藝體制,武媚娘傳奇劇組就是網(wǎng)絡中的一個神經(jīng)元,最近剛剛調(diào)整了參數(shù)。3. 大型神經(jīng)網(wǎng)絡我們不禁要想了,假如我們的這個網(wǎng)絡有10層神經(jīng)元,第8層第2015個神經(jīng)元,它有什么含義呢?我們知道它把第七層的一大堆神經(jīng)元的輸出作為輸入,第七層的神經(jīng)元又是以第六層的一大堆神經(jīng)元做為輸入,那么這個特殊第八層的神經(jīng)元,它會不會代表了某種抽象的概念?就好比你的大腦里有一大堆負責處理聲音、視覺、觸覺信號的神經(jīng)元,它們對于不同的信息會發(fā)出不同的信號,那么會不會有這么一個神經(jīng)元(或者神經(jīng)元小集團),它收集這些信號,分析其是否符合某個抽象的概念,和其他負責更具體和更抽象概念的神經(jīng)元進行交互。2012年多倫多大學的Krizhevsky等人構(gòu)造了一個超大型卷積神經(jīng)網(wǎng)絡[1],有9層,共65萬個神經(jīng)元,6千萬個參數(shù)。網(wǎng)絡的輸入是圖片,輸出是1000個類,比如小蟲、美洲豹、救生船等等。這個模型的訓練需要海量圖片,它的分類準確率也完爆先前所有分類器。紐約大學的Zeiler和Fergusi[2]把這個網(wǎng)絡中某些神經(jīng)元挑出來,把在其上響應特別大的那些輸入圖像放在一起,看它們有什么共同點。他們發(fā)現(xiàn)中間層的神經(jīng)元響應了某些十分抽象的特征。第一層神經(jīng)元主要負責識別顏色和簡單紋理第二層的一些神經(jīng)元可以識別更加細化的紋理,比如布紋、刻度、葉紋。第三層的一些神經(jīng)元負責感受黑夜里的黃色燭光、雞蛋黃、高光。第四層的一些神經(jīng)元負責識別萌狗的臉、七星瓢蟲和一堆圓形物體的存在。第五層的一些神經(jīng)元可以識別出花、圓形屋頂、鍵盤、鳥、黑眼圈動物。這里面的概念并不是整個網(wǎng)絡的輸出,是網(wǎng)絡中間層神經(jīng)元的偏好,它們?yōu)楹竺娴纳窠?jīng)元服務。雖然每一個神經(jīng)元都傻不拉幾的(只會切一刀),但是65萬個神經(jīng)元能學到的東西還真是深邃呢。[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information PRocessing systems (pp. 1097-1105).[2] Zeiler, M. D., & Fergus, R. (2013). Visualizing and understanding convolutional neural networks.arXiv preprint arXiv:1311.2901.編輯于 2015-01-05 215 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利 YJango日本會津大學人機界面實驗室 博士在讀 語音識別/強…523 人贊同作者:YJango鏈接:超智能體專欄來源:知乎著作權(quán)歸作者所有。商業(yè)轉(zhuǎn)載請聯(lián)系作者獲得授權(quán),非商業(yè)轉(zhuǎn)載請注明出處。YJango 的 Live -- 深層學習入門誤區(qū)gitbook閱讀請到:后面也有tensorflow的代碼部分。人工神經(jīng)網(wǎng)絡 · 超智能體深層神經(jīng)網(wǎng)絡 · 超智能體csdn閱讀請到:暫無代碼深層學習為何要“Deep”(上)深層學習為何要“Deep”(下)更新2017年1月4日文章Recurrent Layers——介紹
YJango日本會津大學人機界面實驗室 博士在讀 語音識別/強…523 人贊同作者:YJango鏈接:超智能體專欄來源:知乎著作權(quán)歸作者所有。商業(yè)轉(zhuǎn)載請聯(lián)系作者獲得授權(quán),非商業(yè)轉(zhuǎn)載請注明出處。YJango 的 Live -- 深層學習入門誤區(qū)gitbook閱讀請到:后面也有tensorflow的代碼部分。人工神經(jīng)網(wǎng)絡 · 超智能體深層神經(jīng)網(wǎng)絡 · 超智能體csdn閱讀請到:暫無代碼深層學習為何要“Deep”(上)深層學習為何要“Deep”(下)更新2017年1月4日文章Recurrent Layers——介紹1、神經(jīng)網(wǎng)絡為什么可以用于識別 (已回答)深層學習為何要“Deep”(上)
2、神經(jīng)網(wǎng)絡變深后我們獲得了什么 (已回答)深層學習為何要“Deep”(下)
深層學習開啟了人工智能的新時代。不論任何行業(yè)都害怕錯過這一時代浪潮,因而大批資金和人才爭相涌入。但深層學習卻以“黑箱”而聞名,不僅調(diào)參難,訓練難,“新型”網(wǎng)絡結(jié)構(gòu)的論文又如雨后春筍般地涌現(xiàn),使得對所有結(jié)構(gòu)的掌握變成了不現(xiàn)實。我們?nèi)鄙僖粋€對深層學習合理的認識。本文就是通過對深層神經(jīng)網(wǎng)絡驚人表現(xiàn)背后原因的思考,揭示設計一個神經(jīng)網(wǎng)絡的本質(zhì),從而獲得一個對“如何設計網(wǎng)絡”的全局指導。
深層學習為何要“Deep”(上)一、基本變換:層神經(jīng)網(wǎng)絡是由一層一層構(gòu)建的,那么每層究竟在做什么?
數(shù)學式子: ,其中
,其中 是輸入向量,
是輸入向量, 是輸出向量,
是輸出向量, 是偏移向量,
是偏移向量, 是權(quán)重矩陣,
是權(quán)重矩陣, 是激活函數(shù)。每一層僅僅是把輸入
是激活函數(shù)。每一層僅僅是把輸入 經(jīng)過如此簡單的操作得到
經(jīng)過如此簡單的操作得到 。數(shù)學理解:通過如下5種對輸入空間(輸入向量的集合)的操作,完成 輸入空間 ——> 輸出空間的變換 (矩陣的行空間到列空間)。 注:用“空間”二字的原因是被分類的并不是單個事物,而是一類事物。空間是指這類事物所有個體的集合。1. 升維/降維2. 放大/縮小3. 旋轉(zhuǎn)4. 平移5. “彎曲” 這5種操作中,1,2,3的操作由
。數(shù)學理解:通過如下5種對輸入空間(輸入向量的集合)的操作,完成 輸入空間 ——> 輸出空間的變換 (矩陣的行空間到列空間)。 注:用“空間”二字的原因是被分類的并不是單個事物,而是一類事物。空間是指這類事物所有個體的集合。1. 升維/降維2. 放大/縮小3. 旋轉(zhuǎn)4. 平移5. “彎曲” 這5種操作中,1,2,3的操作由 完成,4的操作是由
完成,4的操作是由 完成,5的操作則是由來實現(xiàn)。 (此處有動態(tài)圖5種空間操作,幫助理解)
完成,5的操作則是由來實現(xiàn)。 (此處有動態(tài)圖5種空間操作,幫助理解)每層神經(jīng)網(wǎng)絡的數(shù)學理解:用線性變換跟隨著非線性變化,將輸入空間投向另一個空間。
物理理解:對
情景:又符合了我們所處的世界都是非線性的特點。
,數(shù)值且定為
,若確定
(1)2.也可以減少右側(cè)的一個節(jié)點,并改變權(quán)重W至(2),那么輸出
。
(2)3.如果希望通過層網(wǎng)絡能夠從[C, O]空間轉(zhuǎn)變到
空間的話,那么網(wǎng)絡的學習過程就是將W的數(shù)值變成盡可能接近(1)的過程 。如果再加一層,就是通過組合
每層神經(jīng)網(wǎng)絡的物理理解:通過現(xiàn)有的不同物質(zhì)的組合形成新物質(zhì)。
二、理解視角:現(xiàn)在我們知道了每一層的行為,但這種行為又是如何完成識別任務的呢?
數(shù)學視角:“線性可分”一維情景:以分類為例,當要分類正數(shù)、負數(shù)、零,三類的時候,一維空間的直線可以找到兩個超平面(比當前空間低一維的子空間。當前空間是直線的話,超平面就是點)分割這三類。但面對像分類奇數(shù)和偶數(shù)無法找到可以區(qū)分它們的點的時候,我們借助 x % 2(取余)的轉(zhuǎn)變,把x變換到另一個空間下來比較,從而分割。二維情景:平面的四個象限也是線性可分。但下圖的紅藍兩條線就無法找到一超平面去分割。 神經(jīng)網(wǎng)絡的解決方法依舊是轉(zhuǎn)換到另外一個空間下,用的是所說的5種空間變換操作。比如下圖就是經(jīng)過放大、平移、旋轉(zhuǎn)、扭曲原二維空間后,在三維空間下就可以成功找到一個超平面分割紅藍兩線 (同SVM的思路一樣)。 上面是一層神經(jīng)網(wǎng)絡可以做到的,如果把。 設想網(wǎng)絡擁有很多層時,對原始輸入空間的“扭曲力”會大幅增加,如下圖,最終我們可以輕松找到一個超平面分割空間。當然也有如下圖失敗的時候,關鍵在于“如何扭曲空間”。所謂監(jiān)督學習就是給予神經(jīng)網(wǎng)絡網(wǎng)絡大量的訓練例子,讓網(wǎng)絡從訓練例子中學會如何變換空間。每一層的權(quán)重W就控制著如何變換空間,我們最終需要的也就是訓練好的神經(jīng)網(wǎng)絡的所有層的權(quán)重矩陣。。這里有非常棒的可視化空間變換demo,一定要打開嘗試并感受這種扭曲過程。更多內(nèi)容請看Neural Networks, Manifolds, and Topology。
上面的內(nèi)容有三張動態(tài)圖,對于理解這種空間變化非常有幫助。由于知乎不支持動態(tài)圖,可以在gitbook深層學習為何要“deep”上感受那三張圖。一定一定要感受。
線性可分視角:神經(jīng)網(wǎng)絡的學習就是學習如何利用矩陣的線性變換加激活函數(shù)的非線性變換,將原始輸入空間投向線性可分/稀疏的空間去分類/回歸。
增加節(jié)點數(shù):增加維度,即增加線性轉(zhuǎn)換能力。增加層數(shù):增加激活函數(shù)的次數(shù),即增加非線性轉(zhuǎn)換次數(shù)。
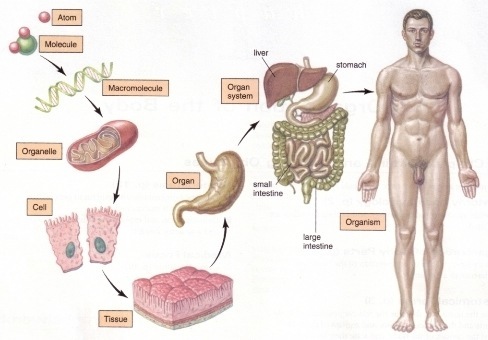
物理視角:“物質(zhì)組成”類比:回想上文由碳氧原子通過不同組合形成若干分子的例子。從分子層面繼續(xù)迭代這種組合思想,可以形成DNA,細胞,組織,器官,最終可以形成一個完整的人。繼續(xù)迭代還會有家庭,公司,國家等。這種現(xiàn)象在身邊隨處可見。并且原子的內(nèi)部結(jié)構(gòu)與太陽系又驚人的相似。不同層級之間都是以類似的幾種規(guī)則再不斷形成新物質(zhì)。你也可能聽過分形學這三個字。可通過觀看從1米到150億光年來感受自然界這種層級現(xiàn)象的普遍性。人臉識別情景:我們可以模擬這種思想并應用在畫面識別上。由像素組成菱角再組成五官最后到不同的人臉。每一層代表不同的不同的物質(zhì)層面 (如分子層)。而每層的W存儲著如何組合上一層的物質(zhì)從而形成新物質(zhì)。 如果我們完全掌握一架飛機是如何從分子開始一層一層形成的,拿到一堆分子后,我們就可以判斷他們是否可以以此形成方式,形成一架飛機。 附:Tensorflow playground展示了數(shù)據(jù)是如何“流動”的。物質(zhì)組成視角:神經(jīng)網(wǎng)絡的學習過程就是學習物質(zhì)組成方式的過程。
增加節(jié)點數(shù):增加同一層物質(zhì)的種類,比如118個元素的原子層就有118個節(jié)點。增加層數(shù):增加更多層級,比如分子層,原子層,器官層,并通過判斷更抽象的概念來識別物體。
按照上文在理解視角中所述的觀點,可以想出下面兩條理由關于為什么更深的網(wǎng)絡會更加容易識別,增加容納變異體(variation)(紅蘋果、綠蘋果)的能力、魯棒性(robust)。
數(shù)學視角:變異體(variation)很多的分類的任務需要高度非線性的分割曲線。不斷的利用那5種空間變換操作將原始輸入空間像“捏橡皮泥一樣”在高維空間下捏成更為線性可分/稀疏的形狀。 物理視角:通過對“抽象概念”的判斷來識別物體,而非細節(jié)。比如對“飛機”的判斷,即便人類自己也無法用語言或者若干條規(guī)則來解釋自己如何判斷一個飛機。因為人腦中真正判斷的不是是否“有機翼”、“能飛行”等細節(jié)現(xiàn)象,而是一個抽象概念。層數(shù)越深,這種概念就越抽象,所能涵蓋的變異體就越多,就可以容納戰(zhàn)斗機,客機等很多種不同種類的飛機。
三、神經(jīng)網(wǎng)絡的訓練知道了神經(jīng)網(wǎng)絡的學習過程就是學習控制著空間變換方式(物質(zhì)組成方式)的權(quán)重矩陣后,接下來的問題就是如何學習每一層的權(quán)重矩陣W。
如何訓練:既然我們希望網(wǎng)絡的輸出盡可能的接近真正想要預測的值。那么就可以通過比較當前網(wǎng)絡的預測值和我們真正想要的目標值,再根據(jù)兩者的差異情況來更新每一層的權(quán)重矩陣(比如,如果網(wǎng)絡的預測值高了,就調(diào)整權(quán)重讓它預測低一些,不斷調(diào)整,直到能夠預測出目標值)。因此就需要先定義“如何比較預測值和目標值的差異”,這便是損失函數(shù)或目標函數(shù)(loss function or objective function),用于衡量預測值和目標值的差異的方程。loss function的輸出值(loss)越高表示差異性越大。那神經(jīng)網(wǎng)絡的訓練就變成了盡可能的縮小loss的過程。 所用的方法是梯度下降(Gradient descent):通過使loss值向當前點對應梯度的反方向不斷移動,來降低loss。一次移動多少是由學習速率(learning rate)來控制的。
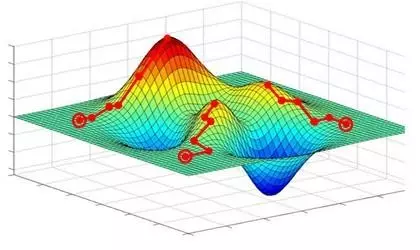
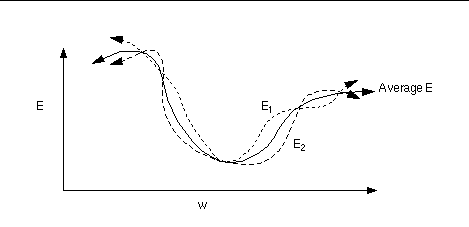
梯度下降的問題:然而使用梯度下降訓練神經(jīng)網(wǎng)絡擁有兩個主要難題。
1、局部極小值梯度下降尋找的是loss function的局部極小值,而我們想要全局最小值。如下圖所示,我們希望loss值可以降低到右側(cè)深藍色的最低點,但loss有可能“卡”在左側(cè)的局部極小值中。 試圖解決“卡在局部極小值”問題的方法分兩大類:
調(diào)節(jié)步伐:調(diào)節(jié)學習速率,使每一次的更新“步伐”不同。常用方法有:
隨機梯度下降(Stochastic Gradient Descent (SGD):每次只更新一個樣本所計算的梯度
小批量梯度下降(Mini-batch gradient descent):每次更新若干樣本所計算的梯度的平均值動量(Momentum):不僅僅考慮當前樣本所計算的梯度;Nesterov動量(Nesterov Momentum):Momentum的改進Adagrad、RMSProp、Adadelta、Adam:這些方法都是訓練過程中依照規(guī)則降低學習速率,部分也綜合動量
優(yōu)化起點:合理初始化權(quán)重(weights initialization)、預訓練網(wǎng)絡(pre-train),使網(wǎng)絡獲得一個較好的“起始點”,如最右側(cè)的起始點就比最左側(cè)的起始點要好。常用方法有:高斯分布初始權(quán)重(Gaussian distribution)、均勻分布初始權(quán)重(Uniform distribution)、Glorot 初始權(quán)重、He初始權(quán)、稀疏矩陣初始權(quán)重(sparse matrix)
2、梯度的計算機器學習所處理的數(shù)據(jù)都是高維數(shù)據(jù),該如何快速計算梯度、而不是以年來計算。 其次如何更新隱藏層的權(quán)重? 解決方法是:計算圖:反向傳播算法這里的解釋留給非常棒的Computational Graphs: Backpropagation需要知道的是,反向傳播算法是求梯度的一種方法。如同快速傅里葉變換(FFT)的貢獻。 而計算圖的概念又使梯度的計算更加合理方便。
基本流程圖:下面就結(jié)合圖簡單瀏覽一下訓練和識別過程,并描述各個部分的作用。要結(jié)合圖解閱讀以下內(nèi)容。但手機顯示的圖過小,最好用電腦打開。
收集訓練集(train data):也就是同時有input以及對應label的數(shù)據(jù)。每個數(shù)據(jù)叫做訓練樣本(sample)。label也叫target,也是機器學習中最貴的部分。上圖表示的是我的數(shù)據(jù)庫。假設input本別是x的維度是39,label的維度是48。設計網(wǎng)絡結(jié)構(gòu)(architecture):確定層數(shù)、每一隱藏層的節(jié)點數(shù)和激活函數(shù),以及輸出層的激活函數(shù)和損失函數(shù)。上圖用的是兩層隱藏層(最后一層是輸出層)。隱藏層所用激活函數(shù)a( )是ReLu,輸出層的激活函數(shù)是線性linear(也可看成是沒有激活函數(shù))。隱藏層都是1000節(jié)點。損失函數(shù)L( )是用于比較距離MSE:mean((output - target)^2)。MSE越小表示預測效果越好。訓練過程就是不斷減小MSE的過程。到此所有數(shù)據(jù)的維度都已確定:
訓練數(shù)據(jù):權(quán)重矩陣:
偏移向量:
網(wǎng)絡輸出:
數(shù)據(jù)預處理(preprocessing):將所有樣本的input和label處理成能夠使用神經(jīng)網(wǎng)絡的數(shù)據(jù),label的值域符合激活函數(shù)的值域。并簡單優(yōu)化數(shù)據(jù)以便讓訓練易于收斂。比如中心化(mean subtraction)、歸一化(normlization)、主成分分析(PCA)、白化(whitening)。假設上圖的input和output全都經(jīng)過了中心化和歸一化。
權(quán)重初始化(weights initialization):在訓練前不能為空,要初始化才能夠計算loss從而來降低。
訓練網(wǎng)絡(training):訓練過程就是用訓練數(shù)據(jù)的input經(jīng)過網(wǎng)絡計算出output,再和label計算出loss,再計算出gradients來更新weights的過程。
正向傳遞:,算當前網(wǎng)絡的預測值計算loss:
計算梯度:從loss開始反向傳播計算每個參數(shù)(parameters)對應的梯度(gradients)。這里用Stochastic Gradient Descent (SGD) 來計算梯度,即每次更新所計算的梯度都是從一個樣本計算出來的。傳統(tǒng)的方法Gradient Descent是正向傳遞所有樣本來計算梯度。SGD的方法來計算梯度的話,loss function的形狀如下圖所示會有變化,這樣在更新中就有可能“跳出”局部最小值。更新權(quán)重:這里用最簡單的方法來更新,即所有參數(shù)都
預測新值:訓練過所有樣本后,打亂樣本順序再次訓練若干次。訓練完畢后,當再來新的數(shù)據(jù)input,就可以利用訓練的網(wǎng)絡來預測了。這時的output就是效果很好的預測值了。下圖是一張實際值和預測值的三組對比圖。輸出數(shù)據(jù)是48維,這里只取1個維度來畫圖。藍色的是實際值,綠色的是實際值。最上方的是訓練數(shù)據(jù)的對比圖,而下方的兩行是神經(jīng)網(wǎng)絡模型從未見過的數(shù)據(jù)預測對比圖。(不過這里用的是RNN,主要是為了讓大家感受一下效果)
注:此部分內(nèi)容不是這篇文章的重點,但為了理解深層神經(jīng)網(wǎng)絡,需要明白最基本的訓練過程。 若能理解訓練過程是通過梯度下降盡可能縮小loss的過程即可。 若有理解障礙,可以用python實踐一下從零開始訓練一個神經(jīng)網(wǎng)絡,體會整個訓練過程。若有時間則可以再體會一下計算圖自動求梯度的方便利用TensorFlow。
四、結(jié)合Tensorflow playground理解5種空間操作和物質(zhì)組成視角打開網(wǎng)頁后,總體來說,藍色代表正值,黃色代表負值。拿分類任務來分析。
數(shù)據(jù):在二維平面內(nèi),若干點被標記成了兩種顏色。黃色,藍色,表示想要區(qū)分的兩類。你可以把平面內(nèi)的任意點標記成任意顏色。網(wǎng)頁給你提供了4種規(guī)律。神經(jīng)網(wǎng)絡會根據(jù)你給的數(shù)據(jù)訓練,再分類相同規(guī)律的點。輸入:在二維平面內(nèi),你想給網(wǎng)絡多少關于“點”的信息。從顏色就可以看出來,左邊是負,右邊是正,
表示此點的縱坐標值。
是關于橫坐標值的“拋物線”信息。你也可以給更多關于這個點的信息。給的越多,越容易被分開。連接線:表示權(quán)重,藍色表示用神經(jīng)元的原始輸出,黃色表示用負輸出。深淺表示權(quán)重的絕對值大小。鼠標放在線上可以看到具體值。也可以更改。在(1)中,當把
雖然在gitbook上已有為何深層學習,但還是發(fā)一下照顧那些關注了超智能體,又只希望在知乎上看文章的小伙伴。近期由于期刊論文deadline將至(Winter is Coming),變體神經(jīng)網(wǎng)絡(RNN,CNN等不同變體的統(tǒng)一理解)部分會在17號開始繼續(xù)寫。
神經(jīng)網(wǎng)絡并不缺少新結(jié)構(gòu),但缺少一個該領域的
很多人在做神經(jīng)網(wǎng)絡的實驗時會發(fā)現(xiàn)調(diào)節(jié)某些方式和結(jié)構(gòu)會產(chǎn)生意想不到的結(jié)果。但就我個人而言,這些發(fā)現(xiàn)并不會讓我感到滿足。我更關心這些新發(fā)現(xiàn)到底告訴我們了什么,造成這些現(xiàn)象的背后原因是什么。我會更想要將新的網(wǎng)絡結(jié)構(gòu)歸納到已有的體系當中。這也是我更多思考“為何深層學習有效”的原因。下面便是目前YJango關于這方面的見解。
深層神經(jīng)網(wǎng)絡相比一般的統(tǒng)計學習擁有從數(shù)學的嚴謹中不會得出的關于物理世界的先驗知識(非貝葉斯先驗)。該內(nèi)容也在Bengio大神的論文和演講中多次強調(diào)。大神也在Bay Area Deep Learning School 2016的Founda’ons and Challenges of Deep Learning pdf(這里也有視頻,需翻墻)中提到的distributed representations和compositionality兩點就是神經(jīng)網(wǎng)絡和深層神經(jīng)網(wǎng)絡高效的原因(若有時間,強烈建議看完演講再看該文)。雖然與大神的思考起點可能不同,但結(jié)論完全一致(看到Bengio大神的視頻時特別興奮)。下面就是結(jié)合例子分析: 1. 為什么神經(jīng)網(wǎng)絡高效 2. 學習的本質(zhì)是什么 3. 為什么深層神經(jīng)網(wǎng)絡比淺層神經(jīng)網(wǎng)絡更高效 4. 神經(jīng)網(wǎng)絡在什么問題上不具備優(yōu)勢
其他推薦讀物
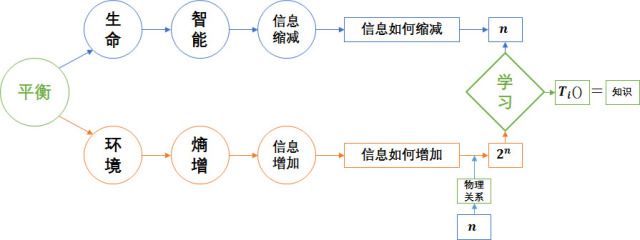
Bengio Y. Learning deep architectures for AI[J]. Foundations and trends? in Machine Learning, 2009, 2(1): 1-127.Brahma P P, Wu D, She Y. Why Deep Learning Works: A Manifold Disentanglement Perspective[J]. 2015.Lin H W, Tegmark M. Why does deep and cheap learning work so well?[J]. arXiv preprint arXiv:1608.08225, 2016.Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(8): 1798-1828.Deep Learning textbook by Ian Goodfellow and Yoshua Bengio and Aaron CourvilleYJango的整個思考流程都圍繞減熵二字進行。之前在《熵與生命》和《生物學習》中討論過,生物要做的是降低環(huán)境的熵,將不確定狀態(tài)變?yōu)榇_定狀態(tài)。通常機器學習是優(yōu)化損失函數(shù),并用概率來衡量模型優(yōu)劣。然而概率正是由于無法確定狀態(tài)才不得不用的衡量手段。生物真正想要的是沒有絲毫不確定性。
深層神經(jīng)網(wǎng)絡在自然問題上更具優(yōu)勢,因為它和生物學習一樣,是找回使熵增加的“物理關系”(知識,并非完全一樣),將變體(
)轉(zhuǎn)化回因素(
)附帶物理關系的形式,從源頭消除熵(假設每個因素只有兩種可能狀態(tài))。這樣所有狀態(tài)間的關系可以被確定,要么肯定發(fā)生,要么絕不發(fā)生,也就無需用概率來衡量。因此下面定義的學習目標并非單純降低損失函數(shù),而從確定關系的角度考慮。一個完美訓練好的模型就是兩個狀態(tài)空間內(nèi)所有可能取值間的關系都被確定的模型。
學習目標:是確定(determine)兩個狀態(tài)空間內(nèi)所有可能取值之間的關系,使得熵盡可能最低。
注:對熵不了解的朋友可以簡單記住,事件的狀態(tài)越確定,熵越小。如絕不發(fā)生(概率0)或肯定發(fā)生(概率為1)的事件熵小。而50%可能性事件的熵反而大。
為舉例說明,下面就一起考慮用神經(jīng)網(wǎng)絡學習以下兩個集合的不同關聯(lián)(OR gate 和 XOR gate)。看看隨著網(wǎng)絡結(jié)構(gòu)和關聯(lián)的改變,會產(chǎn)生什么不同情況。尤其是最后網(wǎng)絡變深時與淺層神經(jīng)網(wǎng)絡的區(qū)別。
注:選擇這種XOR這種簡單關聯(lián)的初衷是輸入和輸出空間狀態(tài)的個數(shù)有限,易于分析變體個數(shù)和熵增的關系。
注:用“變體(variation)”是指同一類事物的不同形態(tài),比如10張狗的圖片,雖然外貌各異,但都是狗。
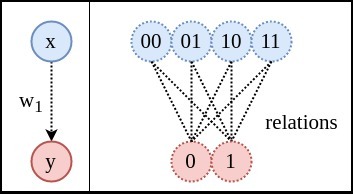
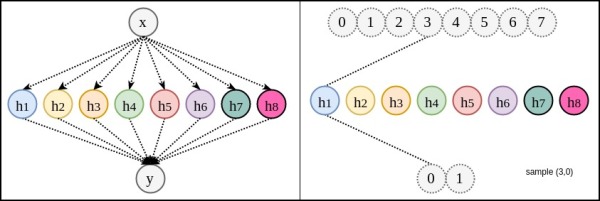
問題描述:集合A有4個狀態(tài),集合B有2個狀態(tài)。0和1只是用于表示不同狀態(tài)的符號,也可以用0,1,2,3表示。狀態(tài)也并不一定表示數(shù)字,可以表示任何物理意義。
方式1:記憶隨機變量X:可能取值是
隨機變量Y:可能取值是
注:隨機變量(大寫X)是將事件投射到實數(shù)的函數(shù)。用對應的實數(shù)表示事件。而小寫字母x表示對應該實數(shù)的事件發(fā)生了,是一個具體實例。
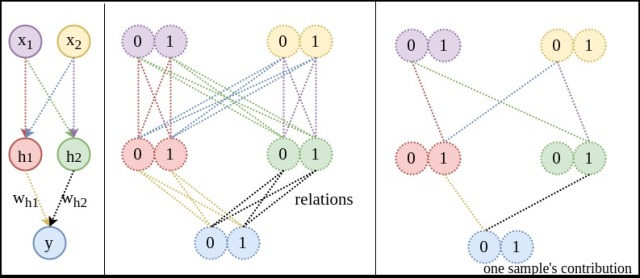
網(wǎng)絡結(jié)構(gòu):暫且不規(guī)定要學習的關聯(lián)是OR還是XOR,先建立一個沒有隱藏層,僅有一個輸入節(jié)點,一個輸出節(jié)點的神經(jīng)網(wǎng)絡。表達式:,
表示sigmoid函數(shù)。(只要是非線性即可,relu是目前的主流)說明:下圖右側(cè)中的虛線表示的既不是神經(jīng)網(wǎng)絡的鏈接,也不是函數(shù)中的映射,而是兩個空間中,所有可能值之間的關系(relation)。學習的目的是確定這些狀態(tài)的關系。比如當輸入00時,模型要嘗試告訴我們00到1的概率為0,00到0的概率為1,這樣熵
才會為零。
關系圖:左側(cè)是網(wǎng)絡結(jié)構(gòu),右側(cè)是狀態(tài)關系圖。輸入和輸出空間之間共有8個關系(非箭頭虛線表示關系)。除非這8個關系對模型來說都是相同的,否則用
表示
時的熵
就會增加。(
注:這里YJango是
的縮寫。
數(shù)據(jù)量:極端假設,若用查找表來表示關系:需要用8個不同的
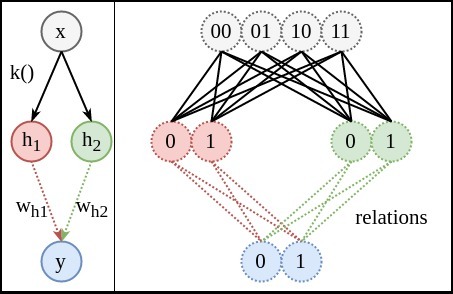
方式2:手工特征特征:空間A的4個狀態(tài)是由兩個0或1的狀態(tài)共同組成。我們可以觀察出來(計算機并不能),我們利用這種知識把A中的狀態(tài)分解開(disentangle)。分解成兩個獨立的子隨機變量
和
。也就是用二維向量表示輸入。
網(wǎng)絡結(jié)構(gòu):由于分成了二維特征,這次網(wǎng)絡結(jié)構(gòu)的輸入需改成兩個節(jié)點。下圖中的上半部分是,利用人工知識
無損轉(zhuǎn)變?yōu)?img src="http://s1.VeVb.com/20170206/vykon0gwr3z48.png" alt="H_{1}" style="border:0px; max-width:100%; vertical-align:middle; display:inline-block; margin:0px 3px">和
的共同表達(representation)。這時
和
注:k()旁邊的黑線(實線表示確定關系)并非是真正的神經(jīng)網(wǎng)絡結(jié)構(gòu),只是方便理解,可以簡單想象成神經(jīng)網(wǎng)絡轉(zhuǎn)變的。
表達式:
注:方便起見,
寫成了矩陣的表達形式
,其中
是標量,而
,
關系圖:由于
來共同對應關系。原本需要擬合的8個關系,現(xiàn)在變成了4個(兩個節(jié)點平攤)。同樣,除非右圖的4條紅色關系線對
注:下圖中左側(cè)是網(wǎng)絡結(jié)構(gòu)圖。右側(cè)關系圖中,接觸的圓圈表示同一個節(jié)點的不同變體。分開的、并標注為不同顏色的圓圈表示不同節(jié)點,左右兩圖連線的顏色相互對應,如紅色的
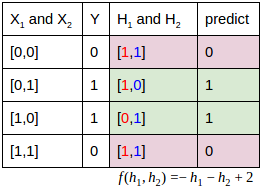
關聯(lián)1:下面和YJango確定想要學習的關聯(lián)(函數(shù))。如果想學習的關聯(lián)是只取
或者
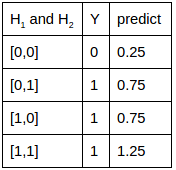
關聯(lián)2:如果想學習的關聯(lián)是或門,真值表和實際訓練完的預測值對照如下。很接近,但有誤差。不過若要是分類的話,可以找到0.5這個超平面來分割。大于0.5的就是1,小于0.5的就是0,可以完美分開。
注:第一列是輸入,第二列是真實想要學習的輸出,第三列是訓練后的網(wǎng)絡預測值。
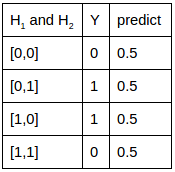
關聯(lián)3:如果想學習的關聯(lián)是異或門(XOR),真值表和實際訓練完的預測值對照如下。由于4條關系線無法用單個
表達,該網(wǎng)絡結(jié)構(gòu)連XOR關聯(lián)的分類都無法分開。
數(shù)據(jù)量:學習這種關聯(lián)至少需4個不同的
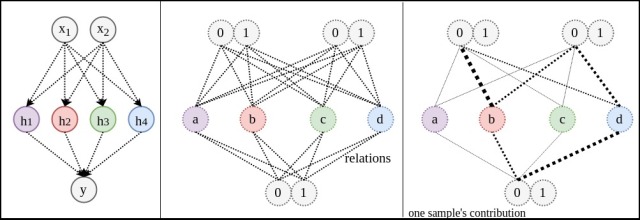
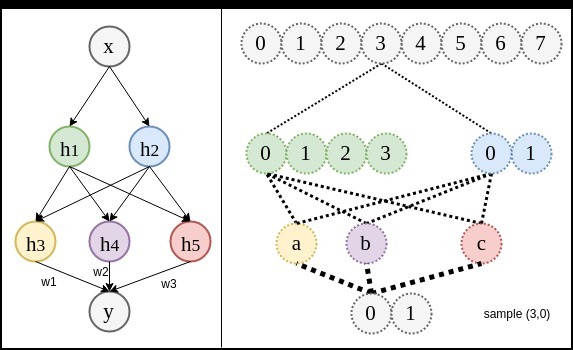
方式3:加入隱藏層網(wǎng)絡結(jié)構(gòu)1:現(xiàn)在直接把來擬合
。其中每個數(shù)據(jù)可以用于確定2條關系線。
作為輸入(用
表示),不考慮
關系圖1:乍一看感覺關系更難確定了。原來還是只有8條關系線,現(xiàn)在又多了16條。但實際上所需要的數(shù)據(jù)量絲毫沒有改變。因為以下兩條先驗知識的成立。
注:下圖最右側(cè)是表示:當一個樣本進入網(wǎng)絡后,能對學習哪些關系線起到作用。
1. 并行:
和
的學習完全是獨立并行。這就是神經(jīng)網(wǎng)絡的兩條固有先驗知識中的:并行:網(wǎng)絡可以同時確定
和
的關聯(lián)。也是Bengio大神所指的distributed representation。
注:有效的前提是所要學習的狀態(tài)空間的關聯(lián)是可以被拆分成并行的因素(factor)。
注:
就沒有并行一說,因為
是一個節(jié)點擁有兩個變體,而不是兩個獨立的因素。但是也可以把
迭代:第二個先驗知識是:在學習
注:有效的前提是所要學習的空間的關聯(lián)是由上一級迭代形成的。所幸的是,我們所生活的世界幾乎都符合這個前提(有特殊反例)。
關聯(lián):如果想學習的關聯(lián)是異或門(XOR),真值表和實際訓練完的預測值對照如下。
的16個關系可能,那么熵會很高。但用兩條線表示
的8個關系,模型的熵可以降到很低。下圖中
數(shù)據(jù)量:如關系圖1中最右側(cè)圖所示,一個輸入[0,0]會被關聯(lián)到0。而這個數(shù)據(jù)可用于學習2+4個關系。也就是說網(wǎng)絡變深并不需要更多數(shù)據(jù)。
:這時再看
的關系,完全就是線性的。光靠觀察就能得出
的一個表達。
模型的熵
所要擬合的關系數(shù)量有關。也就是說,
變體(variation)越少,擬合難度越低,熵越低。
網(wǎng)絡結(jié)構(gòu)2:既然這樣,關系圖2:與網(wǎng)絡結(jié)構(gòu)1不同,增加到4個節(jié)點后,每個節(jié)點都可以完全沒有變體,只取一個值。想法很合理,但實際訓練時,模型不按照該方式工作。
注:太多顏色容易眼花。這里不再用顏色標注不同線之間的對應關系,但對應關系依然存在。
問題:因為會出現(xiàn)右圖的情況:只有兩個節(jié)點在工作(線的粗細表示權(quán)重大小)。和
的節(jié)點在濫竽充數(shù)。這就跟只有兩個節(jié)點時沒有太大別。原因是神經(jīng)網(wǎng)絡的權(quán)重的初始化是隨機的,數(shù)據(jù)的輸入順序也是隨機的。這些隨機性使得權(quán)重更新的方向無法確定。
討論:網(wǎng)絡既然選擇這種方式來更新權(quán)重,是否一定程度上說明,用較少的節(jié)點就可以表示該關聯(lián)?并不是,原因在于日常生活中的關聯(lián),我們無法獲得所有變體的數(shù)據(jù)。所得數(shù)據(jù)往往是很小的一部分。較少的節(jié)點可以表示這一小部分數(shù)據(jù)的關聯(lián),但卻無法涵蓋所有變體情況。造成實際應用時效果不理想。
緩解:緩解的方式有L2正則化(L2 regularization):將每層權(quán)重矩陣的平方和作為懲罰。表達式:,
是懲罰的強弱,可以調(diào)節(jié)。除以2是為了求導方便(與后邊的平方抵消)。意義:當同一層的權(quán)重有個別值過高時,平方和就會增加。而模型在訓練中會降低該懲罰。產(chǎn)生的作用是使所有權(quán)重平攤?cè)蝿眨?img src="http://s1.VeVb.com/20170206/3yougjpdyop51.png%2Cb%2Cc%2Cd" alt="a,b,c,d" style="border:0px; max-width:100%; vertical-align:middle; display:inline-block; margin:0px 3px">都有值。以這樣的方式來使每個節(jié)點都工作,從而消除變體,可以緩解過擬合(overfitting)。例如:
具有一個隱藏層的神經(jīng)網(wǎng)絡可以模擬任何函數(shù),最糟的情況需要
個節(jié)點。
也叫Universal Approximation Theorem。但最糟的情況是輸入空間有多少個變體,就需要多少個節(jié)點。k表示獨立因素的變體個數(shù),n表示獨立因素的個數(shù)。上述的例子中最糟的情況需要
個隱藏節(jié)點。而代價也是需要
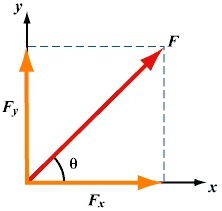
使用條件:淺層神經(jīng)網(wǎng)絡可以分開幾乎所有自然界的關聯(lián)。因為神經(jīng)網(wǎng)絡最初就是由于可移動的生物需要預測未來事件所進化而來的。所學習的關聯(lián)是過去狀態(tài)到未來狀態(tài)。如下圖,物理中的力也可以分離成兩個獨立的分力來研究。
但有一種不適用的情況:非函數(shù)。
實例:函數(shù)的定義是:每個輸入值對應唯一輸出值的對應關系。為什么這么定義函數(shù)?對應兩個以上的輸出值在數(shù)學上完全可以。但是在宏觀的世界發(fā)展中卻不常見。如下圖:
時間順流:不管從哪個起點開始,相同的一個狀態(tài)(不是維度)可以獨立發(fā)展到多個不同狀態(tài)(如氧原子可演變成氧分子和臭氧分子)。也就熱力學第二定律的自發(fā)性熵增:原始狀態(tài)通過物理關系,形成更多變體。
時間倒流:宏觀自然界中難以找到兩個以上的不同狀態(tài)共同收回到一個狀態(tài)的例子(如氧分子和臭氧分子無法合并成氧原子)。如果這個可以實現(xiàn),熵就會自發(fā)性減少。也就不需要生物來消耗能量減熵。我們的房間會向整齊的狀態(tài)發(fā)展。但這違背熱力學第二定律。至少在我們的宏觀世界中,這種現(xiàn)象不常見。所以進化而來的神經(jīng)網(wǎng)絡可以擬合任何函數(shù),但在非函數(shù)上就沒有什么優(yōu)勢。畢竟生物的預測是從過去狀態(tài)到未來狀態(tài)。也說明神經(jīng)網(wǎng)絡并不違背無免費午餐定理。
實例:XOR門的輸入空間和輸出空間若互換位置,則神經(jīng)網(wǎng)絡擬合出來的可能性就非常低(并非絕對無法擬合)。方式4:繼續(xù)加深淺層神經(jīng)網(wǎng)絡可以模擬任何函數(shù),但數(shù)據(jù)量的代價是無法接受的。深層解決了這個問題。相比淺層神經(jīng)網(wǎng)絡,深層神經(jīng)網(wǎng)絡可以用更少的數(shù)據(jù)量來學到更好的擬合。上面的例子很特殊。因為
,
,比較不出來。下面YJango就換一個例子,并比較深層神經(jīng)網(wǎng)絡和淺層神經(jīng)網(wǎng)絡的區(qū)別。
問題描述:空間
有8個可能狀態(tài),空間
有2個可能狀態(tài):
網(wǎng)絡結(jié)構(gòu):
淺層神經(jīng)網(wǎng)絡:8節(jié)點隱藏層深層神經(jīng)網(wǎng)絡:2節(jié)點隱藏層 + 3節(jié)點隱藏層深淺對比:
淺層神經(jīng)網(wǎng)絡:假如說輸入3和輸出0對應。數(shù)據(jù)
只能用于學習一個節(jié)點(如
)前后的兩條關系線。完美學習該關聯(lián)需要所有8個變體。然而當變體數(shù)為
時,我們不可能獲得
深層神經(jīng)網(wǎng)絡:如果只觀察輸入和輸出,看起來同樣需要8個不同的
連接的其他變體進行確定。這樣就使得原本需要8個不同數(shù)據(jù)才能訓練好的關聯(lián)變成只需要3,4不同數(shù)據(jù)個就可以訓練好。(下圖關系線的粗細并非表示權(quán)重絕對值,而是共用度)
深層的前提:使用淺層神經(jīng)網(wǎng)絡好比是用
解
,需要2個不同數(shù)據(jù)。而深層神經(jīng)網(wǎng)絡好比用
解
的關聯(lián)時,搜索效果只會更差。所以深層的前提是:
我們的物理世界:幸運的是,我們的物理世界幾乎都滿足迭代的先驗知識。
實例:比如進化。不同動物都是變體,雖然大家現(xiàn)在的狀態(tài)各異,但在過去都有共同的祖先。實例:又如細胞分裂。八卦中的8個變體是由四象中4個變體的基礎上發(fā)展而來,而四象又是由太極的2個變體演變而來。很難不回想起“無極生太極,太極生兩儀,兩儀生四象,四象生八卦”。(向中國古人致敬,雖然不知道他們的原意)學習的過程是因素間的關系的拆分,關系的拆分是信息的回卷,信息的回卷是變體的消除,變體的消除是不確定性的縮減。
自然界兩個固有的先驗知識:
并行:新狀態(tài)是由若干舊狀態(tài)并行組合形成。
迭代:新狀態(tài)由已形成的狀態(tài)再次迭代形成。
為何深層學習:深層學習比淺層學習在解決結(jié)構(gòu)問題上可用更少的數(shù)據(jù)學習到更好的關聯(lián)。
隨后的三篇文章正是用tensorflow實現(xiàn)上述討論的內(nèi)容,以此作為零基礎實現(xiàn)深層學習的起點。
TensorFlow基本用法代碼演示LV1代碼演示LV2最后總結(jié)一下開篇的問題: 1. 為什么神經(jīng)網(wǎng)絡高效:并行的先驗知識使得模型可用線性級數(shù)量的樣本學習指數(shù)級數(shù)量的變體 2. 學習的本質(zhì)是什么:將變體拆分成因素和知識(Disentangle Factors of Variation)
稀疏表達:一個矩陣被拆分成了稀疏表達和字典。one hot vector:將因素用不同維度分開,避免彼此糾纏。 3. 為什么深層神經(jīng)網(wǎng)絡比淺層神經(jīng)網(wǎng)絡更高效:迭代組成的先驗知識使得樣本可用于幫助訓練其他共用同樣底層結(jié)構(gòu)的樣本。 4. 神經(jīng)網(wǎng)絡在什么問題上不具備優(yōu)勢:不滿足并行與迭代先驗的任務 非函數(shù):需要想辦法將問題轉(zhuǎn)化。非迭代(非結(jié)構(gòu)):該層狀態(tài)不是由上層狀態(tài)構(gòu)成的任務(如:很深的CNN因為有max pooling,信息會逐漸丟失。而residual network再次使得迭代的先驗滿足)到此我們討論完了神經(jīng)網(wǎng)絡最基礎的,也是最重要的知識。在實際應用中仍會遇到很多問題(尤其是神經(jīng)網(wǎng)絡對noise的克服更加巧妙)。隨后YJango會再和大家一起分析過深后會產(chǎn)生什么效果,并一步步引出設計神經(jīng)網(wǎng)絡的本質(zhì)。
編輯于 2017-01-05 31 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 申請轉(zhuǎn)載Peng Bo 稟臨科技 http://withablink.taobao.com 聯(lián)合創(chuàng)始人1046 人贊同最近 Google Tensorflow 做了一個非常直觀的神經(jīng)網(wǎng)絡 playground。不夸張地說,現(xiàn)在每個人都可以在自己的瀏覽器里面直接“玩深度神經(jīng)網(wǎng)絡”了。什么都不用說,自己玩玩就明白。地址是: A Neural Network Playground (可能要翻墻)如果不明白里面的 ReLU,L1 等等是什么,沒關系,在搜索引擎查一下都可以查到答案。代碼在 Github 上,有興趣的朋友可以去給它加 Dropout,Convolution,Pooling 之類。【UPDATE:對 AlphaGo 和圍棋人工智能有興趣的朋友,我最近在寫一個系列,介紹如何自制你的"AlphaGo",請點擊:知乎專欄】編輯于 2017-01-10 44 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
知乎用戶 謹言慎行!280 人贊同首先把題主給的鏈接看了一下,大致內(nèi)容如下:你需要挑選芒果,你不知道什么樣的芒果最好吃,所以你就嘗遍了所有的芒果,然后自己總結(jié)出個大深黃色的比較好吃,以后再去買的時候,就可以直接挑選這種。那什么是機器學習呢,就是你讓機器“嘗”一遍所有芒果,當然,也假設它知道哪些好吃,讓機器去總結(jié)一套規(guī)律(個大深黃色),這就是機器學習。具體操作,就是你描述給機器每一個芒果的特征(顏色,大小,軟硬……),描述給機器其輸出(味道如何,是否好吃),剩下的就等機器去學習出一套規(guī)則。等等,那機器是怎么學習到這個規(guī)則(個大深黃色的好吃)的?沒錯,是通過機器學習算法。而題主所問的神經(jīng)網(wǎng)絡,恰好就是一種機器學習算法!近些年來,由于深度學習概念的興起,神經(jīng)網(wǎng)絡又成為了機器學習領域最熱門的研究方法。我相信當明確神經(jīng)網(wǎng)絡是一種機器學習算法之后,就可以很輕易的給一個外行講清楚神經(jīng)網(wǎng)絡到底是用來做什么的。可是神經(jīng)網(wǎng)絡為什么可以完成這個功能呢?神經(jīng)網(wǎng)絡就像一個剛開始學習東西的小孩子,開始認東西,作為一個大人(監(jiān)督者),第一天,他看見一只京巴狗,你告訴他這是狗;第二天他看見一只波斯貓,他開心地說,這是狗,糾正他,這是貓;第三天,他看見一只蝴蝶犬,他又迷惑了,你告訴他這是狗……直到有一天,他可以分清任何一只貓或者狗。其實神經(jīng)網(wǎng)絡最初得名,就是其在模擬人的大腦,把每一個節(jié)點當作一個神經(jīng)元,這些“神經(jīng)元”組成的網(wǎng)絡就是神經(jīng)網(wǎng)絡。而由于計算機出色的計算能力和細節(jié)把握能力,在大數(shù)據(jù)的基礎上,神經(jīng)網(wǎng)絡往往有比人更出色的表現(xiàn)。當然了,也可以把神經(jīng)網(wǎng)絡當作一個黑箱子,只要告訴它輸入,輸出,他可以學到輸入與輸出的函數(shù)關系。神經(jīng)網(wǎng)絡的理論基礎之一是三層的神經(jīng)網(wǎng)絡可以逼近任意的函數(shù),所以理論上,只要數(shù)據(jù)量夠大,“箱子容量”夠大(神經(jīng)元數(shù)量),神經(jīng)網(wǎng)絡就可以學到你要的東西。第一次回答問題,什么都想說,可能比較亂,有不對的地方,歡迎大家批評指正。發(fā)布于 2014-02-13 36 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
沈晟 心動網(wǎng)絡CTO,射手影音|射手網(wǎng)創(chuàng)始人,品…27 人贊同還好問題只是怎樣盡量簡單的解釋什么是神經(jīng)網(wǎng)絡,否則還真不敢回答。學術(shù)圈比較喜歡用一些名詞術(shù)語,很容易對理解造成更多困惑。我只說一下個人的粗淺理解,希望對初入門的同學有幫助。可能存在疏漏和誤導,只能請大家充分利用自己的判斷力。----先放輕松態(tài)度,應該更便于理解神經(jīng)網(wǎng)絡。神經(jīng)網(wǎng)絡+深度學習中的很多理論方法已經(jīng)存在很多年(大于10),并不是突然之間像魔術(shù)那樣出現(xiàn)而不可思議。最近開始吸引焦點,主要是因為可用的計算能力(CPU、GPU)的快速發(fā)展,讓海量矩陣乘法運算更容易被實驗、測試和驗證。例如,TensorFlow的出現(xiàn),最大的意義,就是AI for everybody,讓「舊時王謝堂前燕,飛入尋常百姓家」。----如果嘗試強行一句話解釋深度學習神經(jīng)網(wǎng)絡,我會這么總結(jié):「通過堆積大量且多樣計算方法的函數(shù)計算式的計算單元(有關名詞:node/activation function/ReLU/...),并嘗試為這些計算單元建立大量的相互連接,同時為了有序有效我們通過分層使連接有次序并避免需要嘗試的連接數(shù)成冪指數(shù)上升,之后制定一個策略幫助整個神經(jīng)網(wǎng)絡的計算評價嘗試的結(jié)果更好更可用或更壞更不可用(有關名詞:lose/cost/objective funtion/softmax/cross entropy), 在提供大量數(shù)據(jù)訓練神經(jīng)網(wǎng)絡之后,神經(jīng)網(wǎng)絡通過計算結(jié)果的評價策略,決定以什么樣的次序連接哪些計算單元的計算結(jié)果更值得被使用(有關名詞:強化連接),通過大量循環(huán)不同的連接方式找到評價最好的一些的連接計算單元的次序和權(quán)值,就此建立模型(計算式組合)可用于解決更多同類問題。」堆積大量計算單元(神經(jīng)元)的最大的好處是什么呢。就是減輕設計(或者說supervise)的壓力。可以更少考慮應該怎樣去針對一個個很具體的feature細節(jié)(carefully engineered function)去解決,而是通過訓練來強化或弱化它們直接的連接,以一種自然選擇的方式淘汰和篩選,留下可用的解題模型。那么上面說的大量是多大呢。一個昨天看的一個論文,是用了65萬個。不過雖然訓練時需要很大的計算量,但是訓練的結(jié)果在使用時,就只需要很小的運算量了。就像迷宮有力地圖,再走一次時,就不會走那么多彎路了。----其實通過嘗試組合大量不同的算法,找到最適合解決問題的算法組合,訓練+強化理論,是機器學習一直都在做的。那么深度學習神經(jīng)網(wǎng)絡的核心突破是什么,我認為主要是兩點:1、分層。這個最大的好處,是將計算單元之間需要嘗試的連接(組合)數(shù)量,控制可控的范圍。2、一些被發(fā)現(xiàn)很適合用來作為深度學習組件的計算單元函數(shù),例如ReLU(When in doubt, ReLU)----最后推薦一個我覺得很好的入門資源:https://github.com/jtoy/awesome-tensorflow編輯于 2016-10-19 3 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
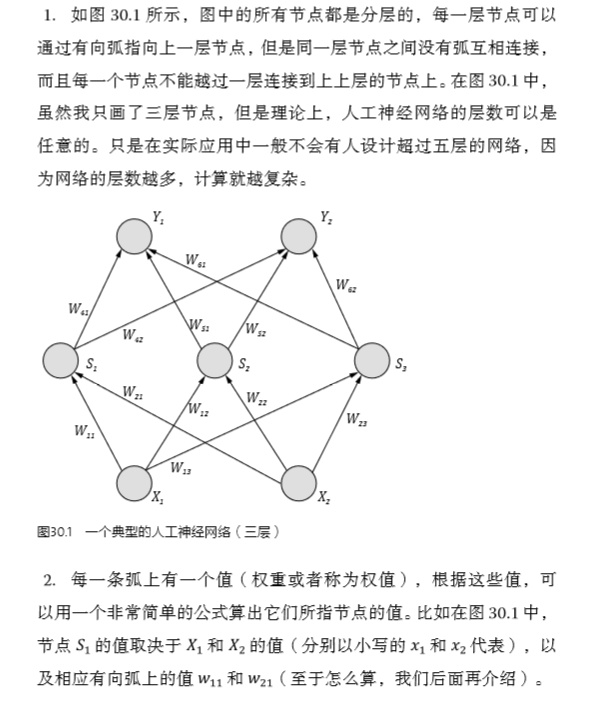
周筠兒童教育話題優(yōu)秀回答者 虛晃一槍。535 人贊同早年讀電信系在職碩士時,選修了一門《人工神經(jīng)網(wǎng)絡》課程,老師講得云山霧罩,我們聽得如夢似幻。雖然最后也考了80多分,但同學們相互間吐槽,都覺得這門課把人給學神經(jīng)了!別人怎么樣我不知道,我反正是稀里糊涂的,沒弄清楚概念。今年,審讀吳軍老師的《數(shù)學之美》第二版,讀到這兩段話時,我笑了,原來我并不孤獨——
【 有不少專業(yè)術(shù)語乍一聽很唬人,“人工神經(jīng)網(wǎng)絡”就屬于這一類,至少我第一次聽到這個詞就被唬住了。你想啊,在大家的印象當中,人們對人腦的結(jié)構(gòu)都還根本沒有搞清楚,這就冒出來一個“人工的”神經(jīng)網(wǎng)絡,似乎是在用計算機來模擬人腦。想到人腦的結(jié)構(gòu)那么復雜,大家的第一反應一定是人工神經(jīng)網(wǎng)絡肯定非常高深。如果我們有幸遇到一個好心同時又善于表達的科學家或教授,他愿意花一兩個小時的時間,深入淺出地把人工神經(jīng)網(wǎng)絡的底細告訴你,你便會發(fā)現(xiàn),“哦,原來是這么回事”。如果我們不幸遇到一個愛賣弄的人,他會很鄭重地告訴你“我在使用人工神經(jīng)網(wǎng)絡”或者“我研究的課題是人工神經(jīng)網(wǎng)絡”,然后就沒有下文了,如此,你除了對他肅然起敬外,不由得可能還會感到自卑。當然還有好心卻不善于表達的人試圖將這個概念給你講清楚,但是他用了一些更難懂的名詞,講得云山霧罩,最后你發(fā)現(xiàn)聽他講了好幾個小時,結(jié)果是更加糊涂了,你除了浪費時間外一無所獲,于是你得出一個結(jié)論:反正我這輩子不需要搞懂它了。
大家可別以為我是在說笑話,這些都是我的親身經(jīng)歷。首先,我沒有遇到過一兩小時給我講懂的好心人,其次我遇到了一批在我前面賣弄的人,作為年輕人,總是希望把自己不明白的東西搞懂,于是我決定去旁聽一門課。不過,我聽了大約兩三次便不再去了,因為除了浪費時間,似乎我并沒得到什么收獲。好在我自己做研究暫時用不到它,也就不再關心了。后來在美國讀博士期間,我喜歡在睡覺前躺著看書,沒事兒就捧著幾本關于人工神經(jīng)網(wǎng)絡的教科書在床上看,居然也看懂了。然后再用它做了兩三個項目,算是學會了。到這時回過頭來再看“人工神經(jīng)網(wǎng)絡”,其實并不復雜,入門也不難,只是我走了彎路。——吳軍】
君子報仇,三十年不晚。大學畢業(yè)三十年后,吳老師在數(shù)學之美 (第二版) 里,單獨用一章講Google大腦和人工神經(jīng)網(wǎng)絡,一抒當年的郁悶,也順便幫我解了氣:)
我把這一章的內(nèi)容貼一部分在這里,希望對大家理解神經(jīng)網(wǎng)絡的概念有幫助:
發(fā)布于 2015-01-05 55 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 申請轉(zhuǎn)載許鐵-巡洋艦科技 微信公眾號請關注chaoscruiser ,鐵哥個人…13 人贊同作者:許鐵-巡洋艦科技鏈接:知乎專欄來源:知乎著作權(quán)歸作者所有。商業(yè)轉(zhuǎn)載請聯(lián)系作者獲得授權(quán),非商業(yè)轉(zhuǎn)載請注明出處。
人工神經(jīng)網(wǎng)絡的第一個里程碑是感知機perceptron, 這個名字其實有點誤導, 因為它根本上是做決策的。 一個感知機其實是對神經(jīng)元最基本概念的模擬 ,都未必有多少網(wǎng)絡概念,他就是一個自動做決策的機器。
比如說你要決定今天出不出去看電影, 你要考慮3個因素, 一個是女朋友在不在, 一個是電影好不好看, 另一個是今天有沒有工作, 這三個因素每個人的權(quán)重都不同,有的人看重女朋友, 有的人看重工作,所以權(quán)重就不等, 最后每個人根據(jù)自己的權(quán)重做出0或1,去或不去, to be or not to be的決策。那么你怎么做呢? 你把三個要素按照它們需要的權(quán)重加和在一起, 在把這個分數(shù)送到一個叫sigmoid的門面前得到去或不去的決定, 工作原理如上圖。
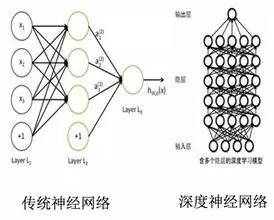
比單層感知機更復雜的多層感知機-或者我們常說的深度網(wǎng)絡, 是進行數(shù)據(jù)處理和模式識別的利器。 深度神經(jīng)網(wǎng)絡之所以能夠處理這些數(shù)據(jù)類型,主要是因為這些數(shù)據(jù)本身具有的復雜結(jié)構(gòu)很適合被NN識別, 而人類不需要預先設計識別這些結(jié)構(gòu)的函數(shù)而是任由網(wǎng)絡學習, D-CNN 深度卷積網(wǎng)絡能夠同時看到一個圖像從細節(jié)到抽象的結(jié)構(gòu),所以能夠抓住一些我們?nèi)祟惗颊f不出的細節(jié)。
DCNN 深度卷積網(wǎng)絡,信號在多級網(wǎng)絡里一級級傳遞, 從而使得從微觀到宏觀的特征都得到分辨 。 每一層神經(jīng)元之間沒有相互連接。
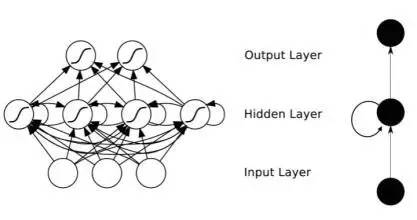
而RNN- 反饋式神經(jīng)網(wǎng)絡(每一層神經(jīng)元之間有相互連接)則適合處理sequnce序列類的數(shù)據(jù), 發(fā)現(xiàn)序列內(nèi)部的時間結(jié)構(gòu)。
RNN 之所以具有這個能力,就是因為網(wǎng)絡內(nèi)部通過自反饋, 具有之前各個時間點的輸入信息, 因此它可以從無限久遠的歷史里推測系統(tǒng)的未來,RNN與之前的卷積網(wǎng)絡相比最大的特點是它包含了動力學特性,如果說卷積網(wǎng)絡是任意函數(shù)逼近器,那么RNN就是任意程序逼近器。 猶如包含某種工作記憶。用一個比喻來說, 就是RNN猶如一個寬闊的池塘寧靜的水面, 當你投入一個石子, 激起的漣漪會在水池里不停反射傳播, 這是對石頭進入那一時刻信息的保存, 如果之后在落入一個石頭, 那么它再度激起的漣漪會和之前的水波疊加作用, 形成更復雜的相互作用和紋樣。
RNN示意圖, 同層神經(jīng)元之間有相互連接,從而使得歷史信息在網(wǎng)絡里向回聲一般交替?zhèn)鬟f
RNN 具有相互連接的反饋式神經(jīng)網(wǎng)絡也是最接近生物組織神經(jīng)網(wǎng)絡的人工神經(jīng)網(wǎng)絡, 具有更多的未來潛力,只是它的訓練比feed forward network更復雜。
人工神經(jīng)網(wǎng)絡的訓練就如同生物神經(jīng)網(wǎng)絡的學習, 都是一個不停試錯并減少錯誤的原理, 不過人工神經(jīng)網(wǎng)絡的方法更加簡單化, 比如gradient descent,就是說在參數(shù)空間里尋找使得錯誤減少最快的方法改進。
人工神經(jīng)網(wǎng)絡對于生物神經(jīng)網(wǎng)絡的奇妙之處在于, 它反過來啟迪了生物神經(jīng)網(wǎng)絡是在干什么的,就好像費曼的那句話“ 你要想真正理解一個東西, 就造出一臺”。
發(fā)布于 2016-11-29 1 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利vczh 專業(yè)造輪子,拉黑搶前排。…637 人贊同1+1是多少?10!傻逼,是21+2是多少?37!傻逼,是31+3是多少?-5!傻逼,是4……1+1是多少?5!傻逼,是21+2是多少?14!傻逼,是31+3是多少?25!傻逼,是4……1+1是多少?2!傻逼,是21+2是多少?5!傻逼,是31+3是多少?8!傻逼,是4……1+1是多少?2!傻逼,是21+2是多少?3!傻逼,是31+3是多少?4!傻逼,是4……1+1是多少?2!傻逼,是21+2是多少?3!傻逼,是31+3是多少?4!傻逼,是4……========3年后========100+200是多少?300!發(fā)布于 2016-06-21 94 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
lee philip 神經(jīng)網(wǎng)絡/自然語言處理55 人贊同補充一下@賈偉的答案訓練過程的那段,寫得比較像強化學習,神經(jīng)網(wǎng)絡用到的方法大部分是有監(jiān)督學習。我覺得故事應該是這樣。。。。你想讓神經(jīng)網(wǎng)絡(簡稱神經(jīng))辨認貓和狗(算法類型為分類)。于是給它看一百萬只狗,和一百萬只貓,每只狗的腦門上都貼著“我是狗”的字條,貓則貼“我是貓”(使用標注數(shù)據(jù))。神經(jīng)同時看五十萬只禽獸,分四批看,并作出判斷(實現(xiàn)時用并行處理,使用mini-batch)。每個看到的貓或狗,如果判斷錯了,就修正自己的判斷標準(優(yōu)化)。每看完這二百萬只禽獸算一輪,每學十輪就看一些之前完全沒見過的貓貓狗狗做出判斷(推廣性測試)。當神經(jīng)刻苦學習貓狗知識的時候,你正在睡覺,一覺睡醒,發(fā)現(xiàn)神經(jīng)一小時前判斷貓和狗比較準(次最優(yōu)解),現(xiàn)在學太多反而判斷不準了(過擬合),于是你讓神經(jīng)使用一小時前的標準(防止過擬合技巧之early-stopping)。這樣訓練過程就結(jié)束了。編輯于 2014-02-15 9 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
苗加加16 人贊同簡單:神經(jīng)網(wǎng)絡就是通過模擬神經(jīng)元的運動,獲得一個可以變形為任意形狀的任意維函數(shù)函數(shù)的形狀取決于你告訴他哪些點應該是這個函數(shù)應該盡量經(jīng)過的關于形象和有趣。。實在是不擅長。。發(fā)布于 2014-02-13 2 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
毛毛林 選擇自己真正喜歡的12 人贊同曾經(jīng)做過一個計算機識別美女的程序,效果渣到可以把鳳姐當作美女。 不過還是說說吧找二十個女性圖片正面照,做成標準格式(此處不展開)編程測量眼睛大小,寬度,鼻子大小,高度,寬度等等你認為可以衡量美女的特點作為自變量。然后自己給這二十個女性的美貌打分0至100。把自變量和因變量一一對應輸入計算機,讓計算機學習之后只要把未判定的圖片給計算機,計算機就會根據(jù)你的審美打分了(一秒鐘在一百個頭像中找到鳳姐發(fā)送約嗎我會亂說?)那么如何才能避開鳳姐找到范冰冰呢?1,增加學習樣本量,上萬為佳,越大越好2,換個算法,這也是神經(jīng)網(wǎng)絡最核心的部分,或選擇合適的層數(shù),做非線性變換等發(fā)布于 2015-01-05 8 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
馮某某 認識了一幫敢愛敢恨的人61 人贊同最近學習不確定優(yōu)化攢了一些筆記,連著說一說也算總結(jié)一下。零基礎慎讀。結(jié)論:神經(jīng)網(wǎng)絡是一個參數(shù)數(shù)量突破天際的回歸分析。%突然發(fā)現(xiàn)在做算法的眼睛里神經(jīng)網(wǎng)絡就是模式識別。。----------------Part1 這些名字很帥的統(tǒng)計和優(yōu)化方法是“粗暴的”通常來說,現(xiàn)在解決不確定優(yōu)化問題。都會使用隨機模擬、神經(jīng)元網(wǎng)絡和遺傳算法聯(lián)立的混合智能算法來求解。比如使目標變量的數(shù)學期望達到最優(yōu)值的期望值模型,概率最優(yōu)的可靠度模型(機會約束),還有我校Liu老師常提的隨即相關機會,就是你前幾個優(yōu)化組合一下。其中隨機模擬是一個不確定問題不可少的輸入,遺傳算法用來調(diào)神經(jīng)網(wǎng)絡的參數(shù),神經(jīng)網(wǎng)絡用來逼近現(xiàn)實。互相配合,解決問題。在我看來是及其簡單粗暴,不得已而為之的。只是用它們最干脆的思路,優(yōu)化了最粗暴的方法。比方說,你能寫出一個事物期望值的顯示表達,那么對參變量求導就可以找到極大值點。當然有的時候不是很方便求出全局導數(shù),那么梯度遞降、可行方向等規(guī)劃學方法和數(shù)值方法也大有可為。離散的最優(yōu)值問題在凸區(qū)域上的解也是很方便就可以求出的,此所謂整數(shù)優(yōu)化。這樣一看這個混合算法真是毫無必要呀,那我們?yōu)槭裁催€要用它們呢?原因是因為這是通用方法。我來舉一個例子。整數(shù)優(yōu)化,我們選取適當?shù)暮瘮?shù)把兩種變量聚為兩類。圖中有圈圈的是我們想?yún)^(qū)分的訓練集。這個時候我們需要找一個合適的評價使得他們分開。最方便的是取機器學習里常用的gauss核函數(shù)(數(shù)值隨距離中心點距離單調(diào)遞減的光滑函數(shù)RBF),那么有九個參數(shù)。(均值協(xié)方差)優(yōu)化目標是對幾千個數(shù)聚類之后聚類結(jié)果中訓練集被識別的個數(shù)的兩倍與分出的非訓練集的元素的個數(shù)的差值。我們知道這個值兼顧一二類錯誤的重要性,又是一個明確的目標,當然它越大越好。這個時候常規(guī)的優(yōu)化算法就很難找出這九個參數(shù)的最優(yōu)值了。結(jié)果:畢竟經(jīng)過一次聚類算法之后,中心點的位置是迭代的結(jié)果而完全不確定的。如果能在聚類之前就知道中心點的位置,那么還聚類干嘛呢?這個時候聚類這個操作就像黑盒子,是傳統(tǒng)優(yōu)化問題極度依賴,卻表達不出的優(yōu)化過程。輸入是幾千個點,輸出只是我之前說的評價函數(shù),參數(shù)有九個,這時候不太好把他們看做神經(jīng)元,因為我并沒有顯式的給出其激活函數(shù),或者這里的激活函數(shù)實際上是相互耦合的,或者我沒有將每一個輸入都看做是均等的,所以不太好做一個典型的例子。我選取6個染色體(開始是對訓練集主成分分析的參數(shù)加上白噪聲),迭代一萬次之后,其9個參數(shù)依舊沒有收斂。而且對于參數(shù)極度敏感,gauss核的均值稍做變化,聚類結(jié)果可能就會均分整個樣本集,從而導致失敗。在這種情況下,我覺得,可能沒有比遺傳算法更好的調(diào)參數(shù)方法了。雖然其毫無道理,但由于其根基是遍歷,只是加了稍許隨機性,合理的選擇解,來使得收斂變快。所以不失為一個好方法。也許有人分析其收斂速度,但我覺得并不太必要。因為它并不好看。當我們開始考慮用遍歷求解一個問題的時候,我猜我們對其難度,對其解的形式,對其收斂性也不會有太好的判斷。這樣我們評估遺傳算法的復雜度時,肯定也是要因地制宜的。有些絕大部分信息我們都知道的問題,也許遺傳算法也不慢;有些從頭到尾都在拍腦袋的問題,遺傳算法也能用。Part2 神經(jīng)網(wǎng)絡就是一個“超多參數(shù)的回歸分析”那么神經(jīng)網(wǎng)絡到底是什么呢?【扯了那么多遺傳算法還沒有說正題】正如遺傳算法是遍歷所有參數(shù)選最優(yōu)的過程,神經(jīng)網(wǎng)絡大致也就是遍歷全部函數(shù)選最優(yōu)的過程。盜圖:我們知道一些輸入和輸出的數(shù)據(jù),想找出其中的數(shù)量關系。但又不是那么容易看出來,比如我們不像開普勒那樣一眼就能看出行星運動時半徑的立方和時間平方成反比。有時我們也不太在意具體的顯式表達,這個時候我們就說:你們看好了,這是一張已經(jīng)訓練好的神經(jīng)網(wǎng),你想要知道你想求的函數(shù)值,那么你把輸入丟進去,然后把輸出抱走就好。雖然有的時候【絕大部分時候】,單論神經(jīng)網(wǎng)絡,我們是可以把我們想求得函數(shù)展開成為顯式表達的,但是太難看了我們就不這么做。當然也許你會說這不就是擬合嗎? Indeed . 一般來說我們用來評價神經(jīng)網(wǎng)絡的函數(shù)也就是用和擬合一樣的最小二乘和。神經(jīng)網(wǎng)絡的參數(shù)(權(quán)重)也就可以看做一般回歸分析的參數(shù)。好,我們來看一下一般的線性回歸。
,一共兩個參數(shù)。我們把他們調(diào)到最優(yōu),可惜
還是只有0.3,不work。這個時候我們就想,會不會是
呢?一共三個參數(shù),
Liu B, Theory and Practice of Uncertain Programming, 3rd ed., http://orsc.edu.cn/
-----
pretty good...
有個答主舉了個例子拿20個樣本進去跑:-D
所以數(shù)學背景還是很重要
編輯于 2016-02-03 12 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利百得 對世界好奇6 人贊同建議提煉或者修改一下問題。我無法回答。LS各位的回答都不是簡單形象又有趣的,對于題目來說都是費力不討好的。題主對于“神經(jīng)網(wǎng)絡是什么”這個命題舉出那個選芒果的例子,我認為又是文不對題的,后者應該是問題歸集和算法思路,雖然是研究神經(jīng)網(wǎng)絡當中的必要基礎之一,但是它不是神經(jīng)網(wǎng)絡的特異性問題,跟“神經(jīng)網(wǎng)絡”以及“是什么”還是有非常大的距離。例如數(shù)學也是研究神經(jīng)網(wǎng)絡當中的必要基礎之一……發(fā)布于 2014-05-07 添加評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
江何 燕山風雨覆紫禁 百萬雄師入北京7 人贊同1 大多數(shù)情況下,神經(jīng)網(wǎng)絡的目的就是把多維的輸入,經(jīng)過處理以一維進行輸出。比如輸入一個28*28的圖像,輸出一個表示該圖像的類別的數(shù)字。2 單層神經(jīng)網(wǎng)絡只能應付線性可分的情景; 多層神經(jīng)網(wǎng)絡則可以任意擬合復雜的函數(shù)。3 神經(jīng)網(wǎng)絡需要先進行訓練,再進行識別。相比其他的分類算法,神經(jīng)網(wǎng)絡的特點就是訓練時間長而識別時間短。發(fā)布于 2015-09-05 1 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
陳丹 理工男+偽文青10 人贊同我也來試試講一講:神經(jīng)網(wǎng)絡:文藝女vs理工男 - Candela - 知乎專欄發(fā)布于 2015-10-13 1 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
新聞熱點






疑難解答
 大家想想,最簡單地把這兩組特征向量分開的方法是啥?當然是在兩組數(shù)據(jù)中間畫一條豎直線,直線左邊是狗,右邊是貓,分類器就完成了。以后來了新的向量,凡是落在直線左邊的都是狗,落在右邊的都是貓。一條直線把平面一分為二,一個平面把三維空間一分為二,一個n-1維超平面把n維空間一分為二,兩邊分屬不同的兩類,這種分類器就叫做神經(jīng)元。大家都知道平面上的直線方程是
大家想想,最簡單地把這兩組特征向量分開的方法是啥?當然是在兩組數(shù)據(jù)中間畫一條豎直線,直線左邊是狗,右邊是貓,分類器就完成了。以后來了新的向量,凡是落在直線左邊的都是狗,落在右邊的都是貓。一條直線把平面一分為二,一個平面把三維空間一分為二,一個n-1維超平面把n維空間一分為二,兩邊分屬不同的兩類,這種分類器就叫做神經(jīng)元。大家都知道平面上的直線方程是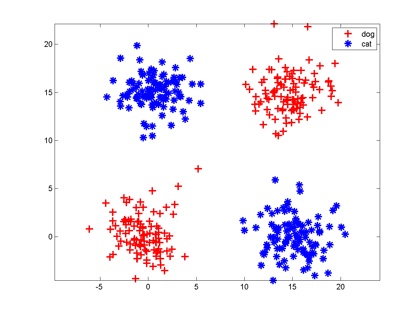 解決辦法是多層神經(jīng)網(wǎng)絡,底層神經(jīng)元的輸出是高層神經(jīng)元的輸入。我們可以在中間橫著砍一刀,豎著砍一刀,然后把左上和右下的部分合在一起,與右上的左下部分分開;也可以圍著左上角的邊沿砍10刀把這一部分先挖出來,然后和右下角合并。每砍一刀,其實就是使用了一個神經(jīng)元,把不同砍下的半平面做交、并等運算,就是把這些神經(jīng)元的輸出當作輸入,后面再連接一個神經(jīng)元。這個例子中特征的形狀稱為異或,這種情況一個神經(jīng)元搞不定,但是兩層神經(jīng)元就能正確對其進行分類。只要你能砍足夠多刀,把結(jié)果拼在一起,什么奇怪形狀的邊界神經(jīng)網(wǎng)絡都能夠表示,所以說神經(jīng)網(wǎng)絡在理論上可以表示很復雜的函數(shù)/空間分布。但是真實的神經(jīng)網(wǎng)絡是否能擺動到正確的位置還要看網(wǎng)絡初始值設置、樣本容量和分布。神經(jīng)網(wǎng)絡神奇的地方在于它的每一個
解決辦法是多層神經(jīng)網(wǎng)絡,底層神經(jīng)元的輸出是高層神經(jīng)元的輸入。我們可以在中間橫著砍一刀,豎著砍一刀,然后把左上和右下的部分合在一起,與右上的左下部分分開;也可以圍著左上角的邊沿砍10刀把這一部分先挖出來,然后和右下角合并。每砍一刀,其實就是使用了一個神經(jīng)元,把不同砍下的半平面做交、并等運算,就是把這些神經(jīng)元的輸出當作輸入,后面再連接一個神經(jīng)元。這個例子中特征的形狀稱為異或,這種情況一個神經(jīng)元搞不定,但是兩層神經(jīng)元就能正確對其進行分類。只要你能砍足夠多刀,把結(jié)果拼在一起,什么奇怪形狀的邊界神經(jīng)網(wǎng)絡都能夠表示,所以說神經(jīng)網(wǎng)絡在理論上可以表示很復雜的函數(shù)/空間分布。但是真實的神經(jīng)網(wǎng)絡是否能擺動到正確的位置還要看網(wǎng)絡初始值設置、樣本容量和分布。神經(jīng)網(wǎng)絡神奇的地方在于它的每一個 神經(jīng)網(wǎng)絡的訓練依靠反向傳播算法:最開始輸入層輸入特征向量,網(wǎng)絡層層計算獲得輸出,輸出層發(fā)現(xiàn)輸出和正確的類號不一樣,這時它就讓最后一層神經(jīng)元進行參數(shù)調(diào)整,最后一層神經(jīng)元不僅自己調(diào)整參數(shù),還會勒令連接它的倒數(shù)第二層神經(jīng)元調(diào)整,層層往回退著調(diào)整。經(jīng)過調(diào)整的網(wǎng)絡會在樣本上繼續(xù)測試,如果輸出還是老分錯,繼續(xù)來一輪回退調(diào)整,直到網(wǎng)絡輸出滿意為止。這很像中國的文藝體制,武媚娘傳奇劇組就是網(wǎng)絡中的一個神經(jīng)元,最近剛剛調(diào)整了參數(shù)。3. 大型神經(jīng)網(wǎng)絡我們不禁要想了,假如我們的這個網(wǎng)絡有10層神經(jīng)元,第8層第2015個神經(jīng)元,它有什么含義呢?我們知道它把第七層的一大堆神經(jīng)元的輸出作為輸入,第七層的神經(jīng)元又是以第六層的一大堆神經(jīng)元做為輸入,那么這個特殊第八層的神經(jīng)元,它會不會代表了某種抽象的概念?就好比你的大腦里有一大堆負責處理聲音、視覺、觸覺信號的神經(jīng)元,它們對于不同的信息會發(fā)出不同的信號,那么會不會有這么一個神經(jīng)元(或者神經(jīng)元小集團),它收集這些信號,分析其是否符合某個抽象的概念,和其他負責更具體和更抽象概念的神經(jīng)元進行交互。2012年多倫多大學的Krizhevsky等人構(gòu)造了一個超大型卷積神經(jīng)網(wǎng)絡[1],有9層,共65萬個神經(jīng)元,6千萬個參數(shù)。網(wǎng)絡的輸入是圖片,輸出是1000個類,比如小蟲、美洲豹、救生船等等。這個模型的訓練需要海量圖片,它的分類準確率也完爆先前所有分類器。紐約大學的Zeiler和Fergusi[2]把這個網(wǎng)絡中某些神經(jīng)元挑出來,把在其上響應特別大的那些輸入圖像放在一起,看它們有什么共同點。他們發(fā)現(xiàn)中間層的神經(jīng)元響應了某些十分抽象的特征。第一層神經(jīng)元主要負責識別顏色和簡單紋理
神經(jīng)網(wǎng)絡的訓練依靠反向傳播算法:最開始輸入層輸入特征向量,網(wǎng)絡層層計算獲得輸出,輸出層發(fā)現(xiàn)輸出和正確的類號不一樣,這時它就讓最后一層神經(jīng)元進行參數(shù)調(diào)整,最后一層神經(jīng)元不僅自己調(diào)整參數(shù),還會勒令連接它的倒數(shù)第二層神經(jīng)元調(diào)整,層層往回退著調(diào)整。經(jīng)過調(diào)整的網(wǎng)絡會在樣本上繼續(xù)測試,如果輸出還是老分錯,繼續(xù)來一輪回退調(diào)整,直到網(wǎng)絡輸出滿意為止。這很像中國的文藝體制,武媚娘傳奇劇組就是網(wǎng)絡中的一個神經(jīng)元,最近剛剛調(diào)整了參數(shù)。3. 大型神經(jīng)網(wǎng)絡我們不禁要想了,假如我們的這個網(wǎng)絡有10層神經(jīng)元,第8層第2015個神經(jīng)元,它有什么含義呢?我們知道它把第七層的一大堆神經(jīng)元的輸出作為輸入,第七層的神經(jīng)元又是以第六層的一大堆神經(jīng)元做為輸入,那么這個特殊第八層的神經(jīng)元,它會不會代表了某種抽象的概念?就好比你的大腦里有一大堆負責處理聲音、視覺、觸覺信號的神經(jīng)元,它們對于不同的信息會發(fā)出不同的信號,那么會不會有這么一個神經(jīng)元(或者神經(jīng)元小集團),它收集這些信號,分析其是否符合某個抽象的概念,和其他負責更具體和更抽象概念的神經(jīng)元進行交互。2012年多倫多大學的Krizhevsky等人構(gòu)造了一個超大型卷積神經(jīng)網(wǎng)絡[1],有9層,共65萬個神經(jīng)元,6千萬個參數(shù)。網(wǎng)絡的輸入是圖片,輸出是1000個類,比如小蟲、美洲豹、救生船等等。這個模型的訓練需要海量圖片,它的分類準確率也完爆先前所有分類器。紐約大學的Zeiler和Fergusi[2]把這個網(wǎng)絡中某些神經(jīng)元挑出來,把在其上響應特別大的那些輸入圖像放在一起,看它們有什么共同點。他們發(fā)現(xiàn)中間層的神經(jīng)元響應了某些十分抽象的特征。第一層神經(jīng)元主要負責識別顏色和簡單紋理 第二層的一些神經(jīng)元可以識別更加細化的紋理,比如布紋、刻度、葉紋。
第二層的一些神經(jīng)元可以識別更加細化的紋理,比如布紋、刻度、葉紋。 第三層的一些神經(jīng)元負責感受黑夜里的黃色燭光、雞蛋黃、高光。
第三層的一些神經(jīng)元負責感受黑夜里的黃色燭光、雞蛋黃、高光。 第四層的一些神經(jīng)元負責識別萌狗的臉、七星瓢蟲和一堆圓形物體的存在。
第四層的一些神經(jīng)元負責識別萌狗的臉、七星瓢蟲和一堆圓形物體的存在。 第五層的一些神經(jīng)元可以識別出花、圓形屋頂、鍵盤、鳥、黑眼圈動物。
第五層的一些神經(jīng)元可以識別出花、圓形屋頂、鍵盤、鳥、黑眼圈動物。 這里面的概念并不是整個網(wǎng)絡的輸出,是網(wǎng)絡中間層神經(jīng)元的偏好,它們?yōu)楹竺娴纳窠?jīng)元服務。雖然每一個神經(jīng)元都傻不拉幾的(只會切一刀),但是65萬個神經(jīng)元能學到的東西還真是深邃呢。[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information
這里面的概念并不是整個網(wǎng)絡的輸出,是網(wǎng)絡中間層神經(jīng)元的偏好,它們?yōu)楹竺娴纳窠?jīng)元服務。雖然每一個神經(jīng)元都傻不拉幾的(只會切一刀),但是65萬個神經(jīng)元能學到的東西還真是深邃呢。[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information 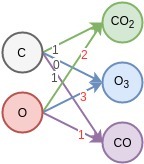 1.如果權(quán)重W的數(shù)值如(1),那么網(wǎng)絡的輸出y? 就會是三個新物質(zhì),[二氧化碳,臭氧,一氧化碳]。
1.如果權(quán)重W的數(shù)值如(1),那么網(wǎng)絡的輸出y? 就會是三個新物質(zhì),[二氧化碳,臭氧,一氧化碳]。  二維情景:平面的四個象限也是線性可分。但下圖的紅藍兩條線就無法找到一超平面去分割。
二維情景:平面的四個象限也是線性可分。但下圖的紅藍兩條線就無法找到一超平面去分割。 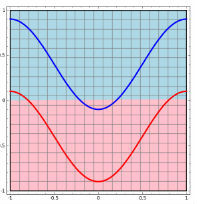 神經(jīng)網(wǎng)絡的解決方法依舊是轉(zhuǎn)換到另外一個空間下,用的是所說的5種空間變換操作。比如下圖就是經(jīng)過放大、平移、旋轉(zhuǎn)、扭曲原二維空間后,在三維空間下就可以成功找到一個超平面分割紅藍兩線 (同SVM的思路一樣)。
神經(jīng)網(wǎng)絡的解決方法依舊是轉(zhuǎn)換到另外一個空間下,用的是所說的5種空間變換操作。比如下圖就是經(jīng)過放大、平移、旋轉(zhuǎn)、扭曲原二維空間后,在三維空間下就可以成功找到一個超平面分割紅藍兩線 (同SVM的思路一樣)。 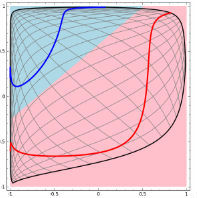 上面是一層神經(jīng)網(wǎng)絡可以做到的,如果把
上面是一層神經(jīng)網(wǎng)絡可以做到的,如果把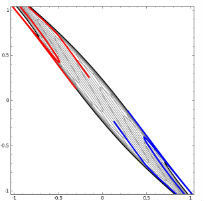 當然也有如下圖失敗的時候,關鍵在于“如何扭曲空間”。所謂監(jiān)督學習就是給予神經(jīng)網(wǎng)絡網(wǎng)絡大量的訓練例子,讓網(wǎng)絡從訓練例子中學會如何變換空間。每一層的權(quán)重W就控制著如何變換空間,我們最終需要的也就是訓練好的神經(jīng)網(wǎng)絡的所有層的權(quán)重矩陣。。這里有非常棒的可視化空間變換demo,一定要打開嘗試并感受這種扭曲過程。更多內(nèi)容請看Neural Networks, Manifolds, and Topology。
當然也有如下圖失敗的時候,關鍵在于“如何扭曲空間”。所謂監(jiān)督學習就是給予神經(jīng)網(wǎng)絡網(wǎng)絡大量的訓練例子,讓網(wǎng)絡從訓練例子中學會如何變換空間。每一層的權(quán)重W就控制著如何變換空間,我們最終需要的也就是訓練好的神經(jīng)網(wǎng)絡的所有層的權(quán)重矩陣。。這里有非常棒的可視化空間變換demo,一定要打開嘗試并感受這種扭曲過程。更多內(nèi)容請看Neural Networks, Manifolds, and Topology。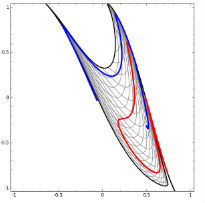
 人臉識別情景:我們可以模擬這種思想并應用在畫面識別上。由像素組成菱角再組成五官最后到不同的人臉。每一層代表不同的不同的物質(zhì)層面 (如分子層)。而每層的W存儲著如何組合上一層的物質(zhì)從而形成新物質(zhì)。 如果我們完全掌握一架飛機是如何從分子開始一層一層形成的,拿到一堆分子后,我們就可以判斷他們是否可以以此形成方式,形成一架飛機。 附:Tensorflow playground展示了數(shù)據(jù)是如何“流動”的。
人臉識別情景:我們可以模擬這種思想并應用在畫面識別上。由像素組成菱角再組成五官最后到不同的人臉。每一層代表不同的不同的物質(zhì)層面 (如分子層)。而每層的W存儲著如何組合上一層的物質(zhì)從而形成新物質(zhì)。 如果我們完全掌握一架飛機是如何從分子開始一層一層形成的,拿到一堆分子后,我們就可以判斷他們是否可以以此形成方式,形成一架飛機。 附:Tensorflow playground展示了數(shù)據(jù)是如何“流動”的。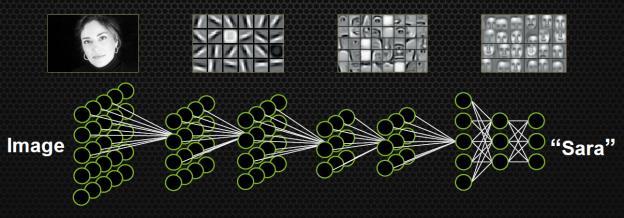
 試圖解決“卡在局部極小值”問題的方法分兩大類:
試圖解決“卡在局部極小值”問題的方法分兩大類: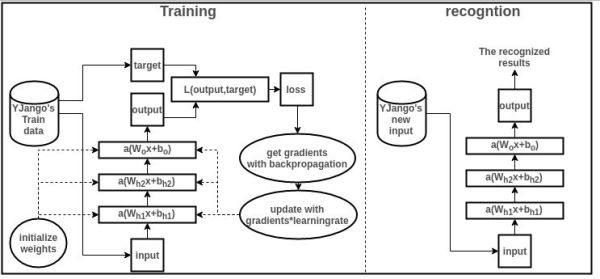

 更新權(quán)重:這里用最簡單的方法來更新,即所有參數(shù)都
更新權(quán)重:這里用最簡單的方法來更新,即所有參數(shù)都 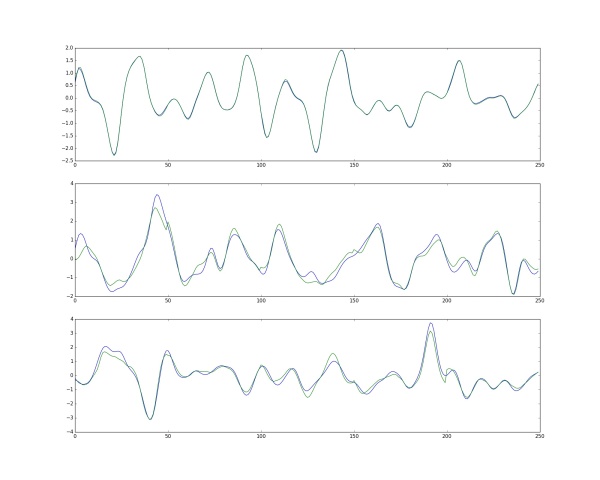
 輸入:在二維平面內(nèi),你想給網(wǎng)絡多少關于“點”的信息。從顏色就可以看出來,
輸入:在二維平面內(nèi),你想給網(wǎng)絡多少關于“點”的信息。從顏色就可以看出來,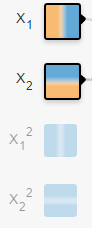 連接線:表示權(quán)重,藍色表示用神經(jīng)元的原始輸出,黃色表示用負輸出。深淺表示權(quán)重的絕對值大小。鼠標放在線上可以看到具體值。也可以更改。在(1)中,當把
連接線:表示權(quán)重,藍色表示用神經(jīng)元的原始輸出,黃色表示用負輸出。深淺表示權(quán)重的絕對值大小。鼠標放在線上可以看到具體值。也可以更改。在(1)中,當把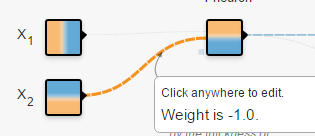 (1)
(1)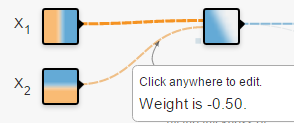 (2)輸出:黃色背景顏色都被歸為黃點類,藍色背景顏色都被歸為藍點類。深淺表示可能性的強弱。
(2)輸出:黃色背景顏色都被歸為黃點類,藍色背景顏色都被歸為藍點類。深淺表示可能性的強弱。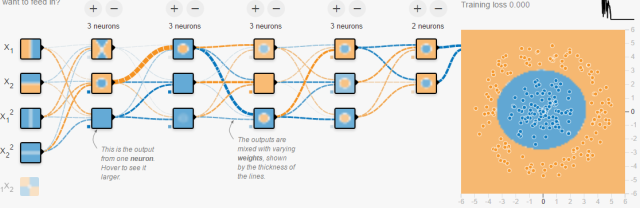 上圖中所有在黃色背景顏色的點都會被分類為“黃點“,同理,藍色區(qū)域被分成藍點。在上面的分類分布圖中你可以看到每一層通過上一層信息的組合所形成的。權(quán)重(那些連接線)控制了“如何組合”。神經(jīng)網(wǎng)絡的學習也就是從數(shù)據(jù)中學習那些權(quán)重。Tensorflow playground所表現(xiàn)出來的現(xiàn)象就是“在我文章里所寫的“物質(zhì)組成思想”,這也是為什么我把Tensorflow playground放在了那一部分。不過你要是把Tensorflow的個名字拆開來看的話,是tensor(張量)的flow(流動)。Tensorflow playground的作者想要闡述的側(cè)重點是“張量如何流動”的。5種空間變換的理解:Tensorflow playground下沒有體現(xiàn)5種空間變換的理解。需要打開這個網(wǎng)站嘗試:ConvNetJS demo: Classify toy 2D data
上圖中所有在黃色背景顏色的點都會被分類為“黃點“,同理,藍色區(qū)域被分成藍點。在上面的分類分布圖中你可以看到每一層通過上一層信息的組合所形成的。權(quán)重(那些連接線)控制了“如何組合”。神經(jīng)網(wǎng)絡的學習也就是從數(shù)據(jù)中學習那些權(quán)重。Tensorflow playground所表現(xiàn)出來的現(xiàn)象就是“在我文章里所寫的“物質(zhì)組成思想”,這也是為什么我把Tensorflow playground放在了那一部分。不過你要是把Tensorflow的個名字拆開來看的話,是tensor(張量)的flow(流動)。Tensorflow playground的作者想要闡述的側(cè)重點是“張量如何流動”的。5種空間變換的理解:Tensorflow playground下沒有體現(xiàn)5種空間變換的理解。需要打開這個網(wǎng)站嘗試:ConvNetJS demo: Classify toy 2D data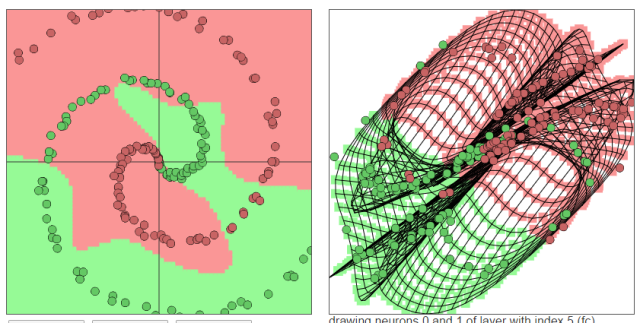 左側(cè)是原始輸入空間下的分類圖,右側(cè)是轉(zhuǎn)換后的高維空間下的扭曲圖。
左側(cè)是原始輸入空間下的分類圖,右側(cè)是轉(zhuǎn)換后的高維空間下的扭曲圖。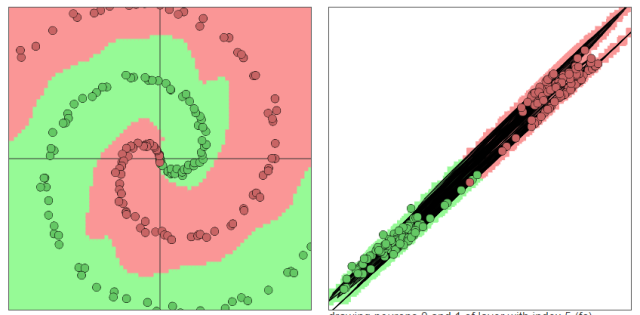 最終的扭曲效果是所有綠點都被扭曲到了一側(cè),而所有紅點都被扭曲到了另一側(cè)。這樣就可以線性分割(用超平面(這里是一個平面)在中間分開兩類)深層學習為何要“Deep”(下)
最終的扭曲效果是所有綠點都被扭曲到了一側(cè),而所有紅點都被扭曲到了另一側(cè)。這樣就可以線性分割(用超平面(這里是一個平面)在中間分開兩類)深層學習為何要“Deep”(下)




![/vec{h}=/left[/begin{matrix}h_{1}//h_{2}/end{matrix}/right]](http://s1.VeVb.com/20170206/v02gbrcxmoj49.png)



 實例:又如細胞分裂。八卦中的8個變體是由四象中4個變體的基礎上發(fā)展而來,而四象又是由太極的2個變體演變而來。很難不回想起“無極生太極,太極生兩儀,兩儀生四象,四象生八卦”。(向中國古人致敬,雖然不知道他們的原意)
實例:又如細胞分裂。八卦中的8個變體是由四象中4個變體的基礎上發(fā)展而來,而四象又是由太極的2個變體演變而來。很難不回想起“無極生太極,太極生兩儀,兩儀生四象,四象生八卦”。(向中國古人致敬,雖然不知道他們的原意)
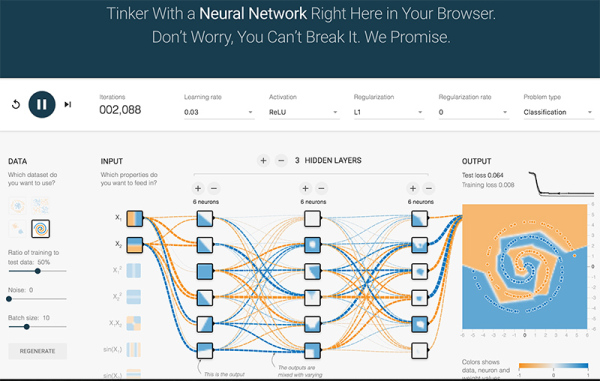 如果不明白里面的 ReLU,L1 等等是什么,沒關系,在搜索引擎查一下都可以查到答案。代碼在 Github 上,有興趣的朋友可以去給它加 Dropout,Convolution,Pooling 之類。【UPDATE:對 AlphaGo 和圍棋人工智能有興趣的朋友,我最近在寫一個系列,介紹如何自制你的"AlphaGo",請點擊:知乎專欄】編輯于 2017-01-10 44 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
如果不明白里面的 ReLU,L1 等等是什么,沒關系,在搜索引擎查一下都可以查到答案。代碼在 Github 上,有興趣的朋友可以去給它加 Dropout,Convolution,Pooling 之類。【UPDATE:對 AlphaGo 和圍棋人工智能有興趣的朋友,我最近在寫一個系列,介紹如何自制你的"AlphaGo",請點擊:知乎專欄】編輯于 2017-01-10 44 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利



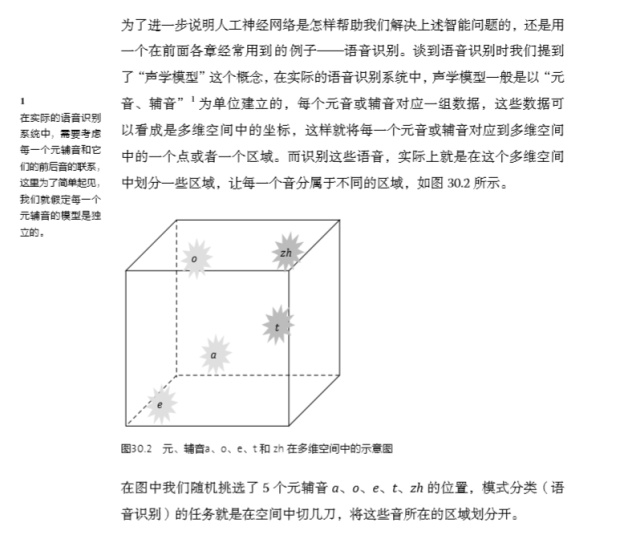
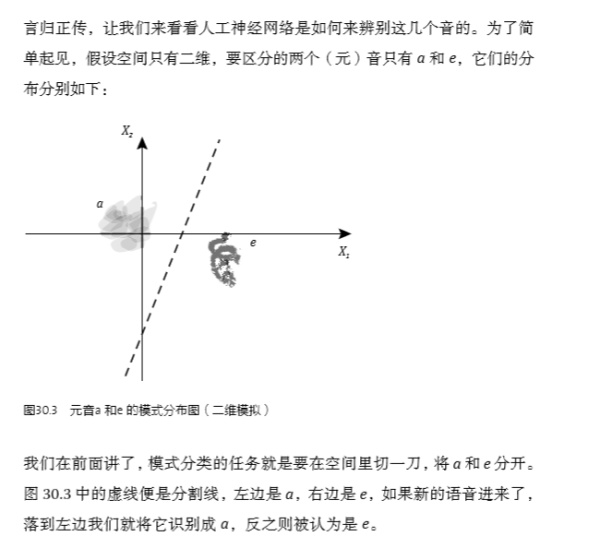
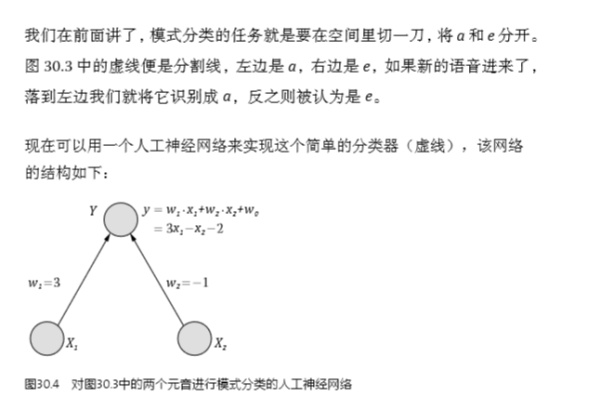

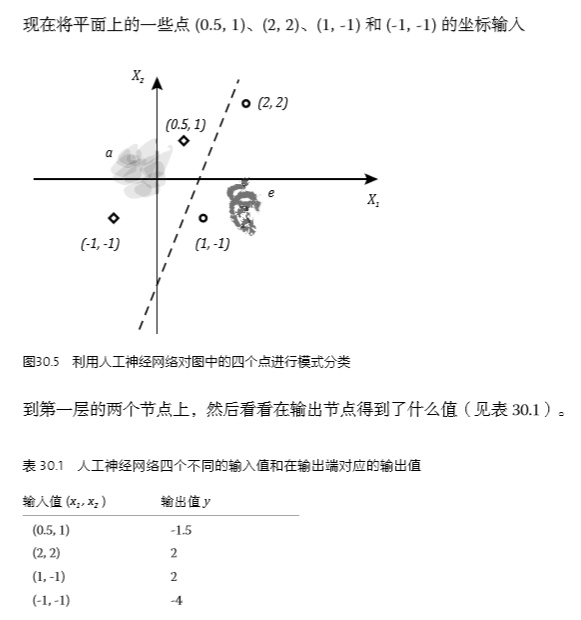

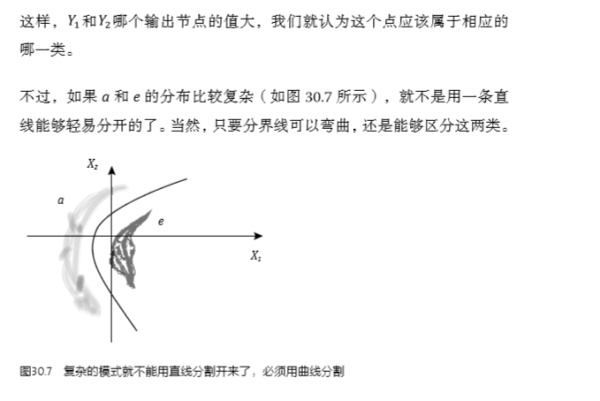
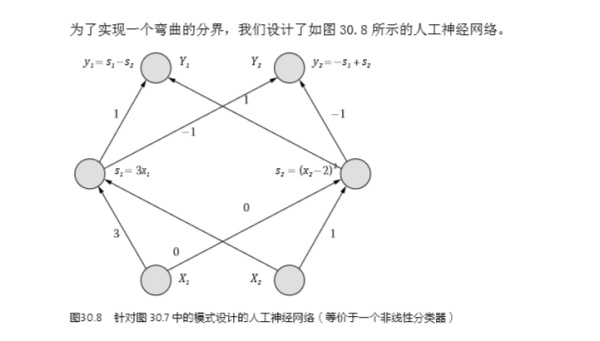
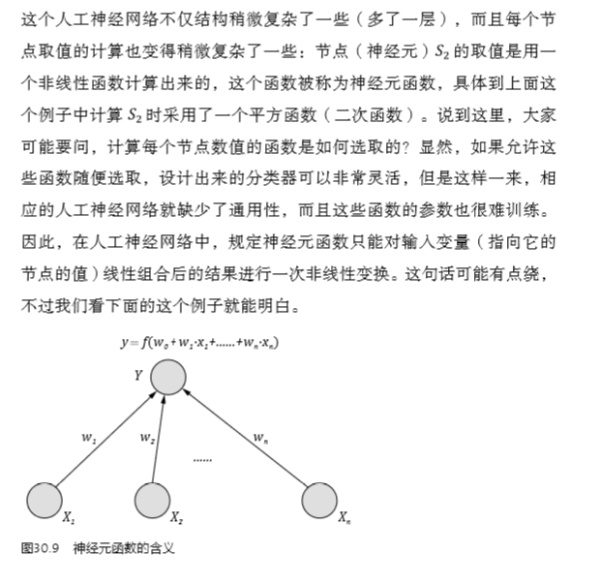


 發(fā)布于 2015-01-05 55 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 申請轉(zhuǎn)載
發(fā)布于 2015-01-05 55 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 申請轉(zhuǎn)載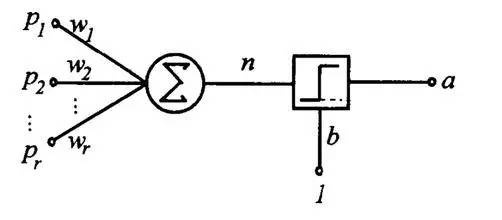
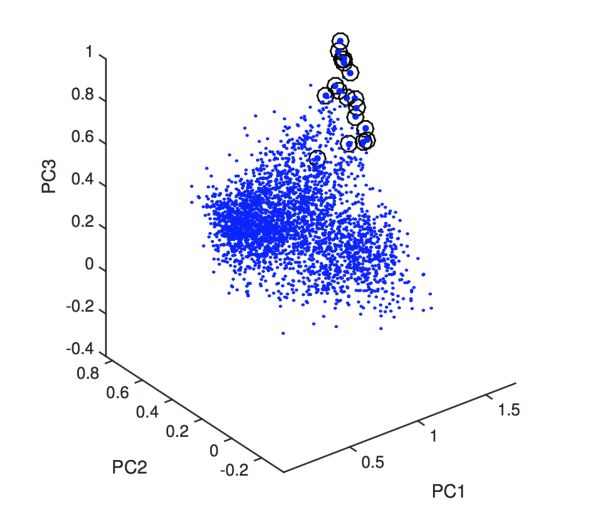 圖中有圈圈的是我們想?yún)^(qū)分的訓練集。這個時候我們需要找一個合適的評價使得他們分開。最方便的是取機器學習里常用的gauss核函數(shù)(數(shù)值隨距離中心點距離單調(diào)遞減的光滑函數(shù)RBF),那么有九個參數(shù)。(均值協(xié)方差)優(yōu)化目標是對幾千個數(shù)聚類之后聚類結(jié)果中訓練集被識別的個數(shù)的兩倍與分出的非訓練集的元素的個數(shù)的差值。我們知道這個值兼顧一二類錯誤的重要性,又是一個明確的目標,當然它越大越好。這個時候常規(guī)的優(yōu)化算法就很難找出這九個參數(shù)的最優(yōu)值了。結(jié)果:
圖中有圈圈的是我們想?yún)^(qū)分的訓練集。這個時候我們需要找一個合適的評價使得他們分開。最方便的是取機器學習里常用的gauss核函數(shù)(數(shù)值隨距離中心點距離單調(diào)遞減的光滑函數(shù)RBF),那么有九個參數(shù)。(均值協(xié)方差)優(yōu)化目標是對幾千個數(shù)聚類之后聚類結(jié)果中訓練集被識別的個數(shù)的兩倍與分出的非訓練集的元素的個數(shù)的差值。我們知道這個值兼顧一二類錯誤的重要性,又是一個明確的目標,當然它越大越好。這個時候常規(guī)的優(yōu)化算法就很難找出這九個參數(shù)的最優(yōu)值了。結(jié)果: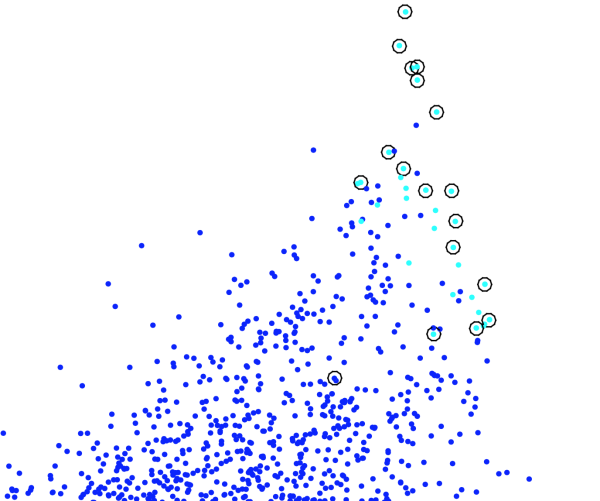 畢竟經(jīng)過一次聚類算法之后,中心點的位置是迭代的結(jié)果而完全不確定的。如果能在聚類之前就知道中心點的位置,那么還聚類干嘛呢?這個時候聚類這個操作就像黑盒子,是傳統(tǒng)優(yōu)化問題極度依賴,卻表達不出的優(yōu)化過程。輸入是幾千個點,輸出只是我之前說的評價函數(shù),參數(shù)有九個,這時候不太好把他們看做神經(jīng)元,因為我并沒有顯式的給出其激活函數(shù),或者這里的激活函數(shù)實際上是相互耦合的,或者我沒有將每一個輸入都看做是均等的,所以不太好做一個典型的例子。我選取6個染色體(開始是對訓練集主成分分析的參數(shù)加上白噪聲),迭代一萬次之后,其9個參數(shù)依舊沒有收斂。而且對于參數(shù)極度敏感,gauss核的均值稍做變化,聚類結(jié)果可能就會均分整個樣本集,從而導致失敗。在這種情況下,我覺得,可能沒有比遺傳算法更好的調(diào)參數(shù)方法了。雖然其毫無道理,但由于其根基是遍歷,只是加了稍許隨機性,合理的選擇解,來使得收斂變快。所以不失為一個好方法。也許有人分析其收斂速度,但我覺得并不太必要。因為它并不好看。當我們開始考慮用遍歷求解一個問題的時候,我猜我們對其難度,對其解的形式,對其收斂性也不會有太好的判斷。這樣我們評估遺傳算法的復雜度時,肯定也是要因地制宜的。有些絕大部分信息我們都知道的問題,也許遺傳算法也不慢;有些從頭到尾都在拍腦袋的問題,遺傳算法也能用。Part2 神經(jīng)網(wǎng)絡就是一個“超多參數(shù)的回歸分析”那么神經(jīng)網(wǎng)絡到底是什么呢?【扯了那么多遺傳算法還沒有說正題】正如遺傳算法是遍歷所有參數(shù)選最優(yōu)的過程,神經(jīng)網(wǎng)絡大致也就是遍歷全部函數(shù)選最優(yōu)的過程。盜圖:
畢竟經(jīng)過一次聚類算法之后,中心點的位置是迭代的結(jié)果而完全不確定的。如果能在聚類之前就知道中心點的位置,那么還聚類干嘛呢?這個時候聚類這個操作就像黑盒子,是傳統(tǒng)優(yōu)化問題極度依賴,卻表達不出的優(yōu)化過程。輸入是幾千個點,輸出只是我之前說的評價函數(shù),參數(shù)有九個,這時候不太好把他們看做神經(jīng)元,因為我并沒有顯式的給出其激活函數(shù),或者這里的激活函數(shù)實際上是相互耦合的,或者我沒有將每一個輸入都看做是均等的,所以不太好做一個典型的例子。我選取6個染色體(開始是對訓練集主成分分析的參數(shù)加上白噪聲),迭代一萬次之后,其9個參數(shù)依舊沒有收斂。而且對于參數(shù)極度敏感,gauss核的均值稍做變化,聚類結(jié)果可能就會均分整個樣本集,從而導致失敗。在這種情況下,我覺得,可能沒有比遺傳算法更好的調(diào)參數(shù)方法了。雖然其毫無道理,但由于其根基是遍歷,只是加了稍許隨機性,合理的選擇解,來使得收斂變快。所以不失為一個好方法。也許有人分析其收斂速度,但我覺得并不太必要。因為它并不好看。當我們開始考慮用遍歷求解一個問題的時候,我猜我們對其難度,對其解的形式,對其收斂性也不會有太好的判斷。這樣我們評估遺傳算法的復雜度時,肯定也是要因地制宜的。有些絕大部分信息我們都知道的問題,也許遺傳算法也不慢;有些從頭到尾都在拍腦袋的問題,遺傳算法也能用。Part2 神經(jīng)網(wǎng)絡就是一個“超多參數(shù)的回歸分析”那么神經(jīng)網(wǎng)絡到底是什么呢?【扯了那么多遺傳算法還沒有說正題】正如遺傳算法是遍歷所有參數(shù)選最優(yōu)的過程,神經(jīng)網(wǎng)絡大致也就是遍歷全部函數(shù)選最優(yōu)的過程。盜圖: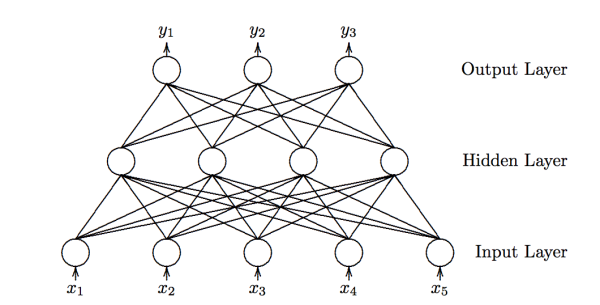 我們知道一些輸入和輸出的數(shù)據(jù),想找出其中的數(shù)量關系。但又不是那么容易看出來,比如我們不像開普勒那樣一眼就能看出行星運動時半徑的立方和時間平方成反比。有時我們也不太在意具體的顯式表達,這個時候我們就說:你們看好了,這是一張已經(jīng)訓練好的神經(jīng)網(wǎng),你想要知道你想求的函數(shù)值,那么你把輸入丟進去,然后把輸出抱走就好。雖然有的時候【絕大部分時候】,單論神經(jīng)網(wǎng)絡,我們是可以把我們想求得函數(shù)展開成為顯式表達的,但是太難看了我們就不這么做。當然也許你會說這不就是擬合嗎? Indeed . 一般來說我們用來評價神經(jīng)網(wǎng)絡的函數(shù)也就是用和擬合一樣的最小二乘和。神經(jīng)網(wǎng)絡的參數(shù)(權(quán)重)也就可以看做一般回歸分析的參數(shù)。好,我們來看一下一般的線性回歸。
我們知道一些輸入和輸出的數(shù)據(jù),想找出其中的數(shù)量關系。但又不是那么容易看出來,比如我們不像開普勒那樣一眼就能看出行星運動時半徑的立方和時間平方成反比。有時我們也不太在意具體的顯式表達,這個時候我們就說:你們看好了,這是一張已經(jīng)訓練好的神經(jīng)網(wǎng),你想要知道你想求的函數(shù)值,那么你把輸入丟進去,然后把輸出抱走就好。雖然有的時候【絕大部分時候】,單論神經(jīng)網(wǎng)絡,我們是可以把我們想求得函數(shù)展開成為顯式表達的,但是太難看了我們就不這么做。當然也許你會說這不就是擬合嗎? Indeed . 一般來說我們用來評價神經(jīng)網(wǎng)絡的函數(shù)也就是用和擬合一樣的最小二乘和。神經(jīng)網(wǎng)絡的參數(shù)(權(quán)重)也就可以看做一般回歸分析的參數(shù)。好,我們來看一下一般的線性回歸。 至于神經(jīng)網(wǎng)絡被一些人鼓吹的神奇特效,比如這里說的可以減小白噪聲。我只能表示我還需要學習一個。畢竟我沒有試過用153個參數(shù)去進行回歸分析,能不能消除白噪聲呀~對了,這里還要提一句,一般用153個參數(shù)回歸分析,總要用154個輸入對吧~但你看神經(jīng)網(wǎng)絡,其實只要隨機生成一個權(quán)重,然后調(diào)幾圈就可以了【現(xiàn)實中確實可以不讓這些參數(shù)都變化,但我不是做算法或者計算機的,所以不太清楚計算機業(yè)界怎么做。我只是做優(yōu)化的時候碰到了一些這樣的問題,自學了一下來吹牛而已】,感覺帥帥的呢~【不過這倒并不是黑點,只是說有些人亂用這些現(xiàn)代學習方法,拿來批判統(tǒng)計學;現(xiàn)代的這些學習方法,都是在大數(shù)據(jù)科學的要求下應運而生,也不是說其粗暴就是壞事,畢竟解決了很多新的以往無法解決的問題】不過搞機器學習的一天到晚過擬合過擬合。。我覺得這參數(shù)取多點還是有道理的。。不知道有沒有暴力增加神經(jīng)元防止過擬合的方法。前面的高贊有一點我不是很能理解,我覺得神經(jīng)網(wǎng)絡的多層隱層的含義可能確實有。。但是想分析其具體含義只能是看到啥說啥了。所以這樣將神經(jīng)網(wǎng)絡說的和玄學一樣感覺不太好。------Appendix:聚類原理
至于神經(jīng)網(wǎng)絡被一些人鼓吹的神奇特效,比如這里說的可以減小白噪聲。我只能表示我還需要學習一個。畢竟我沒有試過用153個參數(shù)去進行回歸分析,能不能消除白噪聲呀~對了,這里還要提一句,一般用153個參數(shù)回歸分析,總要用154個輸入對吧~但你看神經(jīng)網(wǎng)絡,其實只要隨機生成一個權(quán)重,然后調(diào)幾圈就可以了【現(xiàn)實中確實可以不讓這些參數(shù)都變化,但我不是做算法或者計算機的,所以不太清楚計算機業(yè)界怎么做。我只是做優(yōu)化的時候碰到了一些這樣的問題,自學了一下來吹牛而已】,感覺帥帥的呢~【不過這倒并不是黑點,只是說有些人亂用這些現(xiàn)代學習方法,拿來批判統(tǒng)計學;現(xiàn)代的這些學習方法,都是在大數(shù)據(jù)科學的要求下應運而生,也不是說其粗暴就是壞事,畢竟解決了很多新的以往無法解決的問題】不過搞機器學習的一天到晚過擬合過擬合。。我覺得這參數(shù)取多點還是有道理的。。不知道有沒有暴力增加神經(jīng)元防止過擬合的方法。前面的高贊有一點我不是很能理解,我覺得神經(jīng)網(wǎng)絡的多層隱層的含義可能確實有。。但是想分析其具體含義只能是看到啥說啥了。所以這樣將神經(jīng)網(wǎng)絡說的和玄學一樣感覺不太好。------Appendix:聚類原理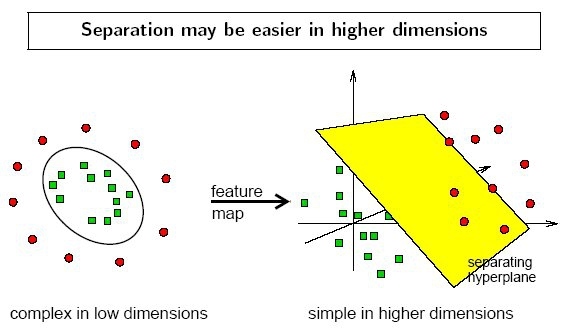 citation:
citation: 發(fā)布于 2015-10-13 1 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利
發(fā)布于 2015-10-13 1 條評論 感謝 分享 收藏 ? 沒有幫助 ? 舉報 ? 作者保留權(quán)利












