微信的熱修復(fù)框架Tinker已經(jīng)在國慶節(jié)之前開源了,成為了http://github.com/Tecent下第一個項(xiàng)目,刷爆了各位開發(fā)者的朋友圈。作為一個超級APP的HotFix庫,Tinker不僅值得我們compile,更值得我們read。
Tinker和以往的HotFix庫思路不太一樣,它更像是APP的增量更新,在服務(wù)器端通過差異性算法,計(jì)算出新舊dex之間的差異包,推送到客戶端,進(jìn)行合成。傳統(tǒng)的差異性算法有BsDiff,而Tinker的牛逼之處就在于它自己基于Dex的文件格式,研發(fā)出了DexDiff算法。
補(bǔ)丁生成是在編譯階段進(jìn)行的,當(dāng)我們在build.gradle中配置好tinkerOldApkPath后,調(diào)用tinkerPatchDebug,補(bǔ)丁就開始生成了。
調(diào)用鏈為:
TinkerPatchSchemaTask.tinkerPatch()->Runner.gradleRun()->Runner.run()->Runner.tinkerPatch()->ApkDecoder.patch()......->DexPatchGenerator.executeAndSaveTo()
executeAndSaveTo()方法是DexDiff算法的真正入口,DexDiff算法的特點(diǎn)在于它深入分析了Dex文件格式,深度利用Dex的格式來減少差異大小。
在了解DexDiff之前,我們需要對Dex文件有個初步了解,Dex的文件格式如下表。參考自這里:Dalvik可執(zhí)行格式(dex)上
數(shù)據(jù)名稱解釋headerdex文件頭部,記錄整個dex文件的相關(guān)屬性string_ids字符串標(biāo)識列表,涉及了文件中所用到的所有字符串,包括內(nèi)部名稱(比如類型描述符)或者代碼引用的常量對象。這個列表根據(jù)字符串內(nèi)容按照UTF-16(避免了各地區(qū)語言差異導(dǎo)致的不同)來進(jìn)行排序,不得包含重復(fù)條目type_ids類型標(biāo)識列表,涉及了文件中所有用到的類型(如類、數(shù)組或者原始類型),不論是否是在文件中定義。這個列表必須按照類型字符串在string_ids中的索引來排序,不得含有重復(fù)條目。PRoto_ids方法原型標(biāo)識列表涉及了文件中所有用到的方法原型。列表按返回值類型在typeids中的索引進(jìn)行排序,索引相同的話再按參數(shù)類型在typeids中的索引排序,不得含有重復(fù)條目。field_ids類屬性(類成員)標(biāo)識列表,涉及了文件中所有用到的類屬性,不論其是否在文件中定義。列表依次按照所在類的類型(按typeids索引)、屬性名(按stringids索引)、自身類型(按type_ids索引)進(jìn)行排序,不得含有重復(fù)條目。method_ids方法標(biāo)識列表,涉及了文件中所有用到的方法,不論是否在文件中定義。列表依次按照方法所在類的類型(按typeids索引)、方法名(按stringids索引)、方法原型(按proto_ids索引),不得含有重復(fù)條目。class_defs類定義列表,列表的順序必須符合一個類的基類以及其所實(shí)現(xiàn)的接口在這個類的前面這一規(guī)則。此外,列表中出現(xiàn)多個同名類的定義是無效的。data數(shù)據(jù)區(qū),包含上述各個結(jié)構(gòu)所需的所有支持?jǐn)?shù)據(jù)。不同的條目有不同的數(shù)據(jù)對齊要求,如果有需要,會在條目之前插入若干字節(jié)以滿足合適的對齊link_data用于靜態(tài)鏈接文件的數(shù)據(jù),數(shù)據(jù)的類型其實(shí)是不確定的,對于不存在鏈接的文件,這個區(qū)域是空的,此外不同的運(yùn)行時(shí)實(shí)現(xiàn)也會對這一區(qū)域的數(shù)據(jù)格式做相應(yīng)修改。想要深入了解Dex文件格式的可以看Google官方文檔:https://source.android.com/devices/tech/dalvik/dex-format.html,《Android軟件安全與逆向分析》這本書里關(guān)于Dex文件也有很詳細(xì)的講解。
了解了Dex的格式后,讓我們來看一下DexDiff的基本步驟。
DexDiff的主要步驟如下:
Step1:計(jì)算出new dex中每項(xiàng)Section的大小,比如string_ids在dex文件中所占大小。
int patchedStringIdsSize = newDex.getTableOfContents().stringIds.size * SizeOf.STRING_ID_ITEM;step2:根據(jù)表中前一項(xiàng)的偏移地址和大小,計(jì)算出每項(xiàng)Section的偏移地址。
this.patchedStringIdsOffset = patchedHeaderOffset + patchedheaderSize;step3:調(diào)用DexSectionDiffAlgorithm.execute(),將new dex與old dex中的每項(xiàng)section進(jìn)行對比,對于每項(xiàng)Section,遍歷其每一項(xiàng)Item,進(jìn)行新舊對比,記錄ADD,DEL標(biāo)識,存放于patchOperationList中。接著遍歷patchOperationList,添加REPLACE標(biāo)識,最后將ADD,DEL,REPLACE操作分別記錄到各自的List中。
這里面的新舊對比的算法很有趣,它是直接將oldItem.compareTo(newItem),結(jié)果小于0記為DEL,大于0記為ADD。為什么可以直接這樣比較呢?別忘啦,從上面Dex文件格式表中可知,Dex文件中的Section都是經(jīng)過排序的。
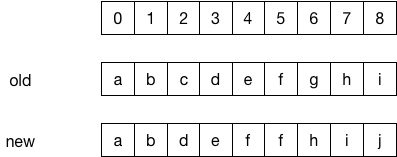
上圖中,old dex中下標(biāo)為2的item "c" 被DEL,c后面的元素前移,new dex中下標(biāo)5處ADD一個item "f",而在下標(biāo)8處又ADD一個item "j"。
下標(biāo)5的"f"在這里被記為ADD,但是它其實(shí)是REPLACE了"g"。在之后遍歷patchOperationList時(shí),算法會判斷operation前一個opearation(prevPatchOperation)的類型,若prevPatchOperation為DEL,而自己剛好為ADD,那么就將自己的類型改為REPLACE。
Iterator<PatchOperation<T>> patchOperationIt = this.patchOperationList.iterator();PatchOperation<T> prevPatchOperation = null;while (patchOperationIt.hasNext()) { PatchOperation<T> patchOperation = patchOperationIt.next(); if (prevPatchOperation != null && prevPatchOperation.op == PatchOperation.OP_DEL && patchOperation.op == PatchOperation.OP_ADD ) { if (prevPatchOperation.index == patchOperation.index) { prevPatchOperation.op = PatchOperation.OP_REPLACE; prevPatchOperation.newItem = patchOperation.newItem; patchOperationIt.remove(); prevPatchOperation = null; } else { prevPatchOperation = patchOperation; } } else { prevPatchOperation = patchOperation; } }step4:調(diào)用DexPatchGenerator.writePatchOperations(),將記錄寫入補(bǔ)丁。對于DEL: 開辟一塊DelOpIndexList大小的區(qū)域(DelOpIndexList中記錄了每塊要刪除部分的索引),遍歷記錄DelOpIndexList,對于每一個DEL索引,計(jì)算出其相對于前一個DEL索引的偏移,記錄偏移量。
buffer.writeUleb128(delOpIndexList.size()); int lastIndex = 0; for (Integer index : delOpIndexList) { buffer.writeSleb128(index - lastIndex); lastIndex = index; }對于ADD和REPLACE,也會進(jìn)行和DEL一樣的操作。
buffer.writeUleb128(addOpIndexList.size()); lastIndex = 0; for (Integer index : addOpIndexList) { buffer.writeSleb128(index - lastIndex); lastIndex = index; }buffer.writeUleb128(replaceOpIndexList.size()); lastIndex = 0; for (Integer index : replaceOpIndexList) { buffer.writeSleb128(index - lastIndex); lastIndex = index; }不同的一點(diǎn)是,ADD和REPALACE還會接著寫入新增和替換的item。
for (T newItem : newItemList) { if (newItem instanceof StringData) { buffer.writeStringData((StringData) newItem); } else if (newItem instanceof Integer) { // TypeId item. buffer.writeInt((Integer) newItem); } else if (newItem instanceof TypeList) { buffer.writeTypeList((TypeList) newItem); } ......}總結(jié)
這里只是簡單的介紹了DexDiff的簡要過程,中間其實(shí)省去了很多細(xì)節(jié),而這些細(xì)節(jié)與Dex文件格式聯(lián)系非常緊密,想要徹底的了解DexDiff原理,還需好好研究Dex文件。
(轉(zhuǎn)載請標(biāo)明ID:半棧工程師,個人博客:HalfStackDeveloper)
歡迎關(guān)注我的知乎專欄:半棧工程師
歡迎Follow我的github: HalfStackDeveloper
新聞熱點(diǎn)






疑難解答













