1.為什么要使用memcache由于網站的高并發讀寫需求,傳統的關系型數據庫開始出現瓶頸,例如:1)對數據庫的高并發讀寫:關系型數據庫本身就是個龐然大物,處理過程非常耗時(如解析SQL語句,事務處理等)。如果對關系型數據庫進行高并發讀寫(每秒上萬次的訪問),那么它是無法承受的。2)對海量數據的處理:對于大型的SNS網站,每天有上千萬次的蘇劇產生(如twitter, 新浪微博)。對于關系型數據庫,如果在一個有上億條數據的數據表種查找某條記錄,效率將非常低。使用memcache能很好的解決以上問題。在實際使用中,通常把數據庫查詢的結果保存到Memcache中,下次訪問時直接從memcache中讀取,而不再進行數據庫查詢操作,這樣就在很大程度上減少了數據庫的負擔。保存在memcache中的對象實際放置在內存中,這也是memcache如此高效的原因。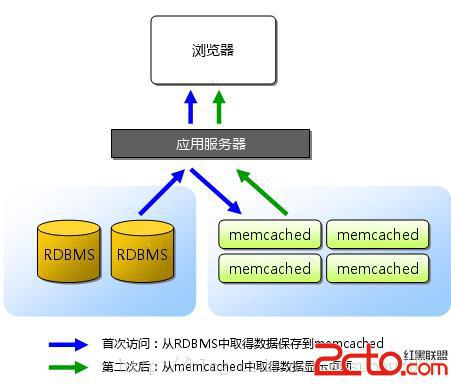 2.memcache的安裝和使用這個網上有太多教程了,不做贅言。
2.memcache的安裝和使用這個網上有太多教程了,不做贅言。
4.memcache使用實例:
<?php$mc = new Memcache();$mc->connect('127.0.0.1', 11211);$uid = (int)$_GET['uid'];$sql = "select * from users where uid='uid' ";$key = md5($sql);if(!($data = $mc->get($key))) { $conn = MySQL_connect('localhost', 'test', 'test'); mysql_select_db('test'); $result = mysql_fetch_object($result); while($row = mysql_fetch_object($result)) { $data[] = $row; } $mc->add($key, $datas);}var_dump($datas);?>5.memcache如何支持高并發(此處還需深入研究)
memcache使用多路復用I/O模型,如(epoll, select等),傳統I/O中,系統可能會因為某個用戶連接還沒做好I/O準備而一直等待,知道這個連接做好I/O準備。這時如果有其他用戶連接到服務器,很可能會因為系統阻塞而得不到響應。
而多路復用I/O是一種消息通知模式,用戶連接做好I/O準備后,系統會通知我們這個連接可以進行I/O操作,這樣就不會阻塞在某個用戶連接。因此,memcache才能支持高并發。
此外,memcache使用了多線程機制。可以同時處理多個請求。線程數一般設置為CPU核數,這研報告效率最高。
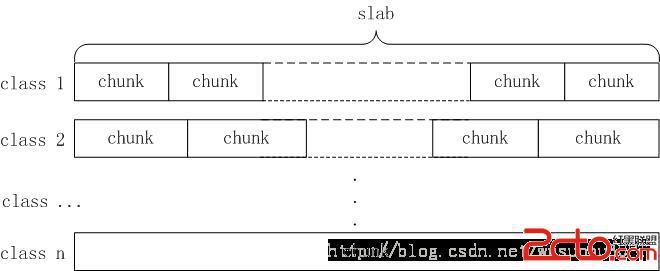
6.使用Slab分配算法保存數據
slab分配算法的原理是:把固定大小(1MB)的內存分為n小塊,如下圖所示:
slab分配算法把每1MB大小的內存稱為一個slab頁,每次向系統申請一個slab頁,然后再通過分隔算法把這個slab頁分割成若干個小塊的chunk
再總結MemCache的特性和限制
上面已經對于MemCache做了一個比較詳細的解讀,這里再次總結MemCache的限制和特性:
1、MemCache中可以保存的item數據量是沒有限制的,只要內存足夠
2、MemCache單進程在32位機中最大使用內存為2G,這個之前的文章提了多次了,64位機則沒有限制
3、Key最大為250個字節,超過該長度無法存儲
4、單個item最大數據是1MB,超過1MB的數據不予存儲
5、MemCache服務端是不安全的,比如已知某個MemCache節點,可以直接telnet過去,并通過flush_all讓已經存在的鍵值對立即失效
6、不能夠遍歷MemCache中所有的item,因為這個操作的速度相對緩慢且會阻塞其他的操作
7、MemCache的高性能源自于兩階段哈希結構:第一階段在客戶端,通過Hash算法根據Key值算出一個節點;第二階段在服務端,通過一個內部的Hash算法,查找真正的item并返回給客戶端。從實現的角度看,MemCache是一個非阻塞的、基于事件的服務器程序
8、MemCache設置添加某一個Key值的時候,傳入expiry為0表示這個Key值永久有效,這個Key值也會在30天之后失效,
新聞熱點






疑難解答