以下是最常用的機器學習算法,大部分數據問題都可以通過它們解決:
線性回歸 (Linear Regression)
邏輯回歸 (Logistic Regression)
決策樹 (Decision Tree)
支持向量機(SVM)
樸素貝葉斯 (Naive Bayes)
K鄰近算法(KNN)
K-均值算法(K-means)
隨機森林 (Random Forest)
降低維度算法(Dimensionality Reduction Algorithms)
Gradient Boost和Adaboost算法
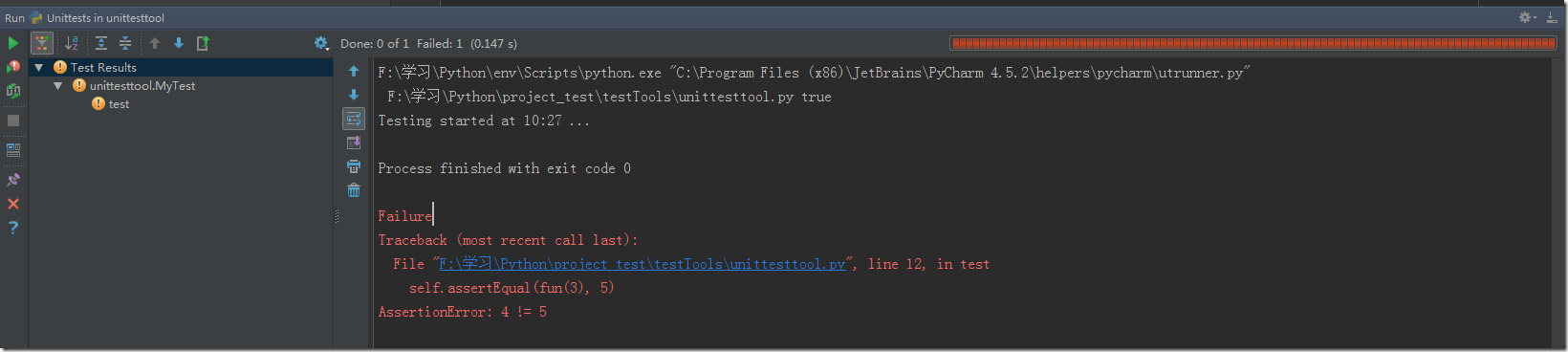
以下實例中predict數據時為了驗證其擬合度,采用的是訓練集數據作為參數,實際中應該采用的是測試集,不要被誤導了!!!
















 參考:http://blog.csdn.net/han_xiaoyang/article/details/51191386
參考:http://blog.csdn.net/han_xiaoyang/article/details/51191386
新聞熱點






疑難解答