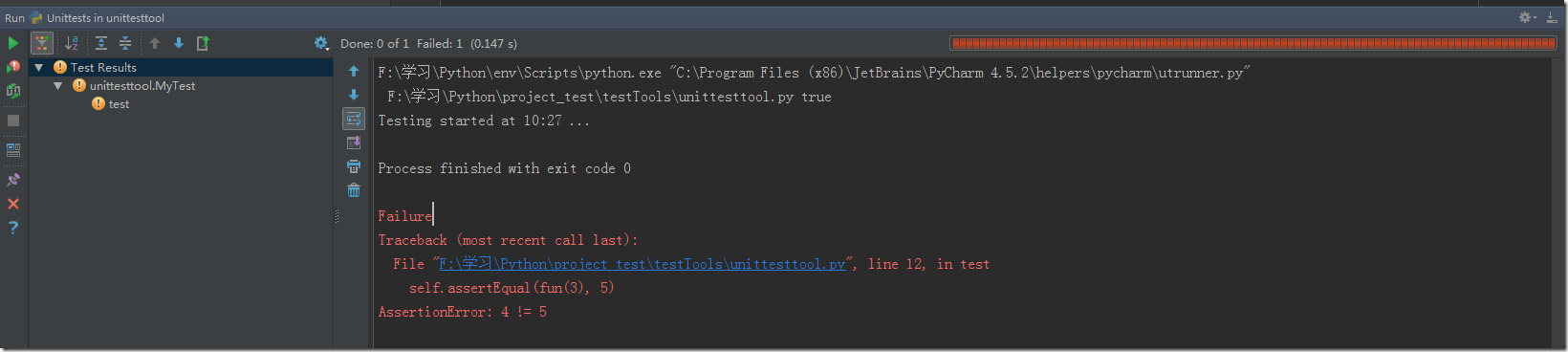
本文主要是使用中科院的分詞工具對于數據庫中的數據文本進行分詞 在電腦上安裝python,并導入python與數據庫的連接插件MySQLdb 以及中科院的分詞工具NLPIR
import pynlpirimport codecsimport math,MySQLdbfrom search import *pynlpir.open()#連接數據庫conn=MySQLdb.connect(host="127.0.0.1",user="root",passwd="123456",db="",charset="utf8") cursor = conn.cursor() n = cursor.execute("select * from test where id = 8 ")停用詞 st = codecs.open('E://testWord//stopwords.txt', 'rb',encoding='gbk') 讀取數據庫中的數據
過濾停用詞
#過濾停用詞 localtion = 0 for word in singletext_result: localtion = localtion + 1 if word not in stopwords: if word >= u'/u4e00' and word <= u'/u9fa5':#判斷是否是漢字 delstopwords_singletxt.append(word)構建詞表
#構建詞表 for item in delstopwords_singletxt: if(search(item)): if(savecount(item)): print 'success to add count' else: if(save(item)): print 'success to add keyword'新聞熱點






疑難解答