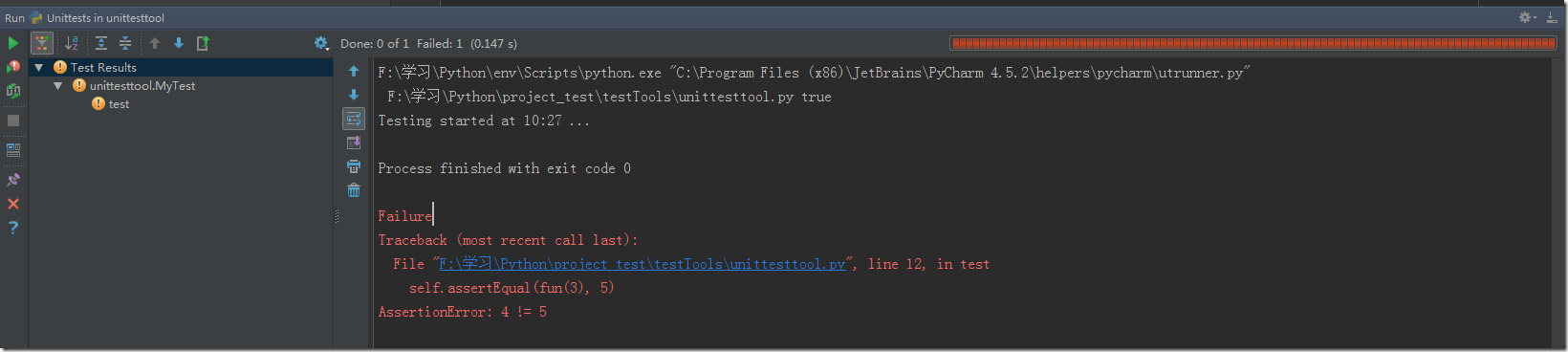
這兩天在machinelearningmastery.com上學習Python實現CART(Classify And Regression Tree),把分類樹從頭到尾學習實現了一遍,雖然不是什么難事,還是想記錄一下,就當增強增強記憶也好。
分類樹邏輯上即為一些連環判斷的組合,以Binary Tree的結構承載這個流程,以存在于非葉節點的數據的屬性+值為判斷條件,以存于各葉節點的值為判斷結果。下圖即為一個簡單的決策樹邏輯(圖片來源:machinelearningmastery.com)。 
算法實現分一下幾個部分: 1、Gini函數 2、樹內各節點的分割 3、樹的建立 4、預測結果
Gini函數: Gini指數作為loss function用來衡量分組后數據“純凈性”(原文用的purity)的指標,判斷數據正確分類的程度:
樹內各節點的分割: 要將數據分類,首先要知道根據什么指標進行分類,即對于每一步的判斷條件,應當找出最適合分類的屬性及該屬性下最適合的值——get_split()將來自要分割節點的所有數據的所有屬性和所有值進行遍歷分割,分別計算各擬分組的Gini指數,取能獲得最小Gini指數的分割方式對該節點進行分割;test_split()即為每次遍歷是根據給定的屬性和值對數據集進行分割。
#Split dataset into groups by specific attribute and valuedef test_split(dataset,index,value): left, right = [], [] for row in dataset: if row[index] < value: left.append(row) else: right.append(row) return left, right#Split dataset into groups for every splitable node def get_split(dataset): dimen = len(dataset[0])-1 b_index, b_value, b_gini, b_group = 999, 999, 999, None class_values = list(set([row[-1] for row in dataset])) for index in range(dimen): for row in dataset: group = test_split(dataset,index,row[index]) gini = gini_index(group,class_values) if gini < b_gini: b_index, b_value, b_gini, b_group = index, row[index], gini, group return {'index':b_index, 'value':b_value, 'gini':b_gini, 'groups':b_group}樹的建立: 在知道如何對每個節點進行合適分割之后,就要開始用遞歸的方式調用split()函數不斷分割節點來建立整棵樹。
考慮遞歸中的基本情況和需要遞歸的情況:
1、基本情況(節點分割結束,變為葉節點):分割后的節點沒有左子節點或右子節點,;當本次分割后樹的深度超出最大深度(max_depth,給定);當本次分割后子節點的數據量小于最小分類后數據量(min_size,給定)或子節點已經被完全正確分類(節點內的所有數據為同一類)。
2、需要遞歸的情況(子節點繼續作為下一個父節點調用分割函數)。
#Make a node a terminal def to_terminal(group): result = [row[-1] for row in group] return max(set(result),key=result.count)#Split the whole tree by iterationdef split(node,max_depth,min_size,depth): left, right = node['groups'] del(node['groups']) #check for no left or right if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return #check for max depth if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return #process the left if len(left) <= min_size or len(set(row[-1] for row in left)) <= 1: #check for min size and already splited correctly node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'],max_depth,min_size,depth+1) #process the right if len(right) <= min_size or len(set(row[-1] for row in right)) <= 1: #check for min size and already splited correctly node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'],max_depth,min_size,depth+1)#Build a whole decision treedef build_tree(dataset,max_depth,min_size): root = get_split(dataset) split(root,max_depth,min_size,1) return root其中的to_terminal()函數實現將該節點變為葉節點,邏輯為以該節點數據中最大比例的該類作為葉節點的值。build_tree()為封裝的建樹函數,返回樹的根節點。
預測結果: 在訓練數據建好決策樹之后,對測試數據利用決策樹進行預測分類,邏輯即為利用存儲在各非葉結點中的一系列判斷條件進行從根節點到葉節點的預測:
#Predict the results of a set of data by trained decision treedef predict(node,row): if row[node['index']] < node['value']: if isinstance(node['left'],dict): return predict(node['left'],row) else: return node['left'] else: if isinstance(node['right'],dict): return predict(node['right'],row) else: return node['right']最后將包括訓練和預測的函數全部封裝到一個decision_tree()函數中,實現算法。
#The (Classify) Decision Tree Algorithmdef decision_tree(train_data,test_data,max_depth,min_size): tree_root = build_tree(train_data,max_depth,min_size) predicted = [] for row in test_data: predicted.append(predict(tree_root,row)) return predicted學習與代碼參考:machinelearningmastery.com
新聞熱點






疑難解答