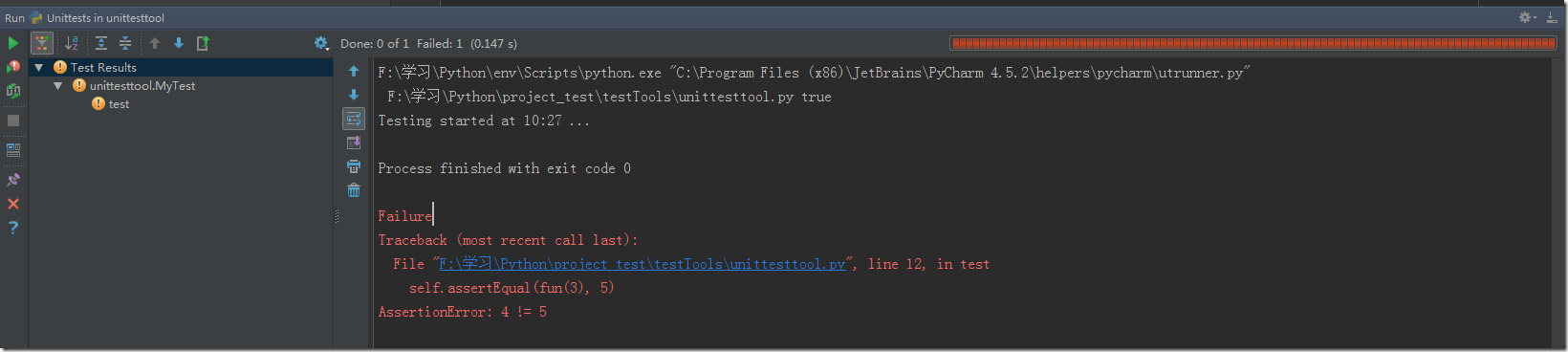
剛接觸python時,師兄就教導(dǎo)我們在每個py文件的第一行要加上# coding=utf-8這句話啦
在一開始的處理時并沒有遇到問題,可隨著處理的東西越來越多,各種各樣的問題就出現(xiàn)了,為了盡量避免這些問題首先是把Pycharm的編碼統(tǒng)一了,如圖 
如果是處理獲取到的網(wǎng)頁源代碼,不要偷懶,先看看源代碼的編碼,就像下圖中的charset=一般來說就是它的編碼了  如果網(wǎng)頁源代碼的編碼和自己編譯器的不同,會出現(xiàn)中文亂碼,那么該怎么解決呢?假設(shè)網(wǎng)頁源代碼是GB2312而想要的是utf-8,則可以用這句代碼
如果網(wǎng)頁源代碼的編碼和自己編譯器的不同,會出現(xiàn)中文亂碼,那么該怎么解決呢?假設(shè)網(wǎng)頁源代碼是GB2312而想要的是utf-8,則可以用這句代碼 s.decode('GB2312').encode('utf-8') 因為字符串在Python內(nèi)部的表示是unicode編碼. 因此,在做編碼轉(zhuǎn)換時,通常需要以unicode作為中間編碼,即先將其他編碼的字符串解碼(decode)成unicode,再從unicode編碼(encode)成另一種編碼。
可是!就是有些網(wǎng)頁啊~口不對心,charset顯示的編碼和實際編碼跟不一樣,怪不得有UnicodeEncodeError[捂臉] 這時候就可以用下面的代碼來查看字符串的真實編碼,然后再decode和encode就好啦
import chardetPRint chardet.detect(data) # data是未知編碼的字符串新聞熱點






疑難解答