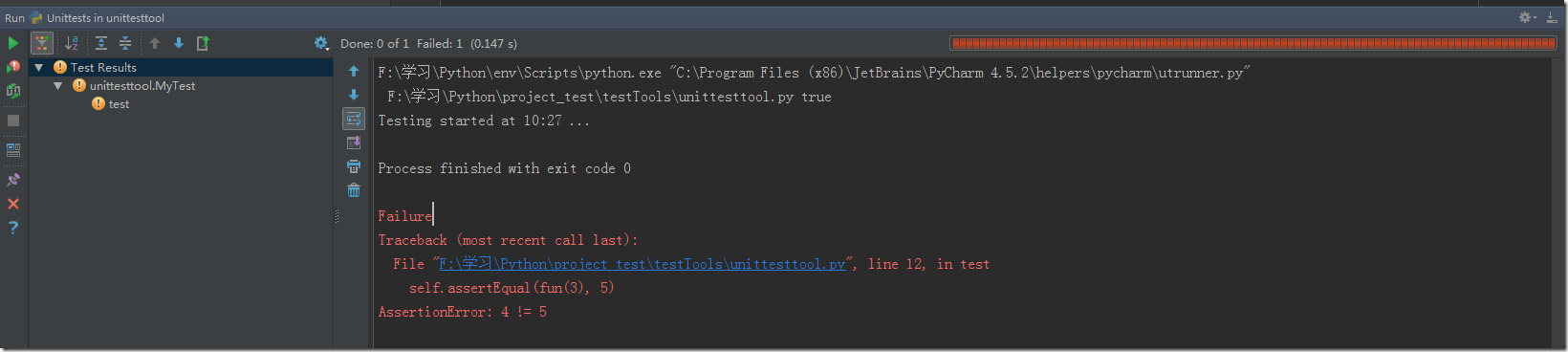
獲取信息
修改items.py如下:
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
city = scrapy.Field()
date = scrapy.Field()
dayDesc = scrapy.Field()
dayTemp = scrapy.Field()
爬蟲代碼
內容如下,采用的項目還是之前創建的Tutorial/weather.py
import scrapy
from tutorial.items import TutorialItem
from scrapy.selector import Selector
from scrapy.http import Request
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
class Douban(scrapy.Spider):
name = 'weather'
allowed_domains = ['sina.com.cn']
start_urls = ['http://weather.sina.com.cn/hangzhou']
def parse(self,response):
item = TutorialItem()
item['city'] = response.xpath("//*[@id='slider_ct_name']/text()").extract()
tenDay = response.xpath('//*[@id="blk_fc_c0_scroll"]');
item['date'] = tenDay.CSS('p.wt_fc_c0_i_date::text').extract()
item['dayDesc'] = tenDay.css('img.icons0_wt::attr(title)').extract()
item['dayTemp'] = tenDay.css('p.wt_fc_c0_i_temp::text').extract()
return item
說明:
name: 用于區別Spider。該名字必須是唯一的,您不可以為不同的Spider設定相同的名字。
start_urls: 包含了Spider在啟動時進行爬取的url列表。因此,第一個被獲取到的頁面將是其中之一。后續的URL則從初始的URL獲取到的數據中提取。
parse() 是spider的一個方法。 被調用時,每個初始URL完成下載后生成的 Response 對象將會作為唯一的參數傳遞給該函數。 該方法負責解析返回的數據(response data),提取數據(生成item)以及生成需要進一步處理的URL的 Request 對象。
分析源碼發現:
城市名可以通過獲取id為slider_ct_name的h4元素獲取日期可以通過獲取id為blk_fc_c0_scroll下的class為wt_fc_c0_i_date的p元素獲取天氣描述可以通過獲取id為blk_fc_c0_scroll下的class為icons0_wt的img元素獲取溫度可以通過獲取id為blk_fc_c0_scroll下的class為wt_fc_c0_i_temp的p元素獲取其中:
//*:選取文檔中的所有元素。@:選擇屬性 /:從節點選取 。extract():提取
Pipeline
當Item在Spider中被收集之后,它將會被傳遞到Item Pipeline,一些組件會按照一定的順序執行對Item的處理。
每個item pipeline組件(有時稱之為“Item Pipeline”)是實現了簡單方法的Python類。他們接收到Item并通過它執行一些行為,同時也決定此Item是否繼續通過pipeline,或是被丟棄而不再進行處理。
以下是item pipeline的一些典型應用:
清理HTML數據
驗證爬取的數據(檢查item包含某些字段)
查重(并丟棄)
將爬取結果保存到數據庫中
PRocess_item(self, item, spider)
每個item pipeline組件都需要調用該方法,這個方法必須返回一個 Item (或任何繼承類)對象, 或是拋出 DropItem 異常,被丟棄的item將不會被之后的pipeline組件所處理。
參數:
item (Item 對象) – 被爬取的item
spider (Spider 對象) – 爬取該item的spider
open_spider(self, spider)
當spider被開啟時,這個方法被調用。
參數: spider (Spider 對象) – 被開啟的spider
close_spider(spider)
當spider被關閉時,這個方法被調用
參數: spider (Spider 對象) – 被關閉的spider
from_crawler(cls, crawler)
PIPELINE代碼
編輯pipelines.py
class TutorialPipeline(object):
def __init__(self):
pass
def process_item(self, item, spider):
with open('wea.txt', 'w+') as file:
city = item['city'][0].encode('utf-8')
file.write('city:' + str(city) + '/n/n')
date = item['date']
desc = item['dayDesc']
dayDesc = desc[1::2]
nightDesc = desc[0::2]
dayTemp = item['dayTemp']
weaitem = zip(date, dayDesc, nightDesc, dayTemp)
for i in range(len(weaitem)):
item = weaitem[i]
d = item[0]
dd = item[1]
nd = item[2]
ta = item[3].split('/')
dt = ta[0]
nt = ta[1]
txt = 'date:{0}/t/tday:{1}({2})/t/tnight:{3}({4})/n/n'.format(
d,
dd.encode('utf-8'),
dt.encode('utf-8'),
nd.encode('utf-8'),
nt.encode('utf-8')
)
file.write(txt)
return item
寫好ITEM_PIPELINES后,還有很重要的一步,就是把 ITEM_PIPELINES 添加到設置文件 settings.py 中。
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 1
}
另外,有些網站對網絡爬蟲進行了阻止(注:本項目僅從技術角度處理此問題,個人強烈不建議您用爬蟲爬取有版權信息的數據),我們可以在設置中修改一下爬蟲的 USER_AGENT 和 Referer 信息,增加爬蟲請求的時間間隔。
DEBUG
顯示只有城市:
scrapy內置的html解析是基于lxml庫的,這個庫對html的解析的容錯性不是很好,通過檢查網頁源碼,發現有部分標簽是不匹配的(地區和瀏覽器不同取到的源碼可能不同)
換個html代碼解析器就可以了,這里建議用 BeautifulSoup
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.html
下載鏈接:
https://www.crummy.com/software/BeautifulSoup/bs4/download/4.5/
爬蟲代碼如下:
import scrapy
from tutorial.items import TutorialItem
from scrapy.selector import Selector
from scrapy.http import Request
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
class Douban(scrapy.Spider):
name = "weather"
allowed_domains = ["sina.com.cn"]
start_urls = ['http://weather.sina.com.cn']
def parse(self, response):
html_doc = response.body
#html_doc = html_doc.decode('utf-8')
soup = BeautifulSoup(html_doc)
itemTemp = {}
itemTemp['city'] = soup.find(id='slider_ct_name')
tenDay = soup.find(id='blk_fc_c0_scroll')
itemTemp['date'] = tenDay.findAll("p", {"class": 'wt_fc_c0_i_date'})
itemTemp['dayDesc'] = tenDay.findAll("img", {"class": 'icons0_wt'})
itemTemp['dayTemp'] = tenDay.findAll('p', {"class": 'wt_fc_c0_i_temp'})
item = TutorialItem()
for att in itemTemp:
item[att] = []
if att == 'city':
item[att] = itemTemp.get(att).text
continue
for obj in itemTemp.get(att):
if att == 'dayDesc':
item[att].append(obj['title'])
else:
item[att].append(obj.text)
return item
新聞熱點






疑難解答