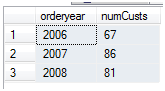
SQL Server 2005開始支持表分區,這種技術允許所有的表分區都保存在同一臺服務器上。每一個表分區都和在某個文件組(filegroup)中的單個文件關聯。同樣的一個文件/文件組可以容納多個分區表。在這種設計架構下,數據庫引擎能夠判定查詢過程中應該訪問哪個分區,而不用掃描整個表。如果查詢需要的數據行分散在多個分區中,SQL Server使用多個處理器對多個分區進行并行查詢。你可以為在創建表的時候就定義分區的索引。 對小索引的搜索或者掃描要比掃描整個表或者一張大表上的索引要快很多。因此,當對大表進行查詢,表分區可以產生相當大的性能提升