通過 1至10 階來擬合對比 均方誤差及R評分,可以確定最優的“最大階數”。
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegression,Perceptronfrom sklearn.metrics import mean_squared_error,r2_scorefrom sklearn.model_selection import train_test_split X = np.array([-4,-3,-2,-1,0,1,2,3,4,5,6,7,8,9,10]).reshape(-1, 1)y = np.array(2*(X**4) + X**2 + 9*X + 2)#y = np.array([300,500,0,-10,0,20,200,300,1000,800,4000,5000,10000,9000,22000]).reshape(-1, 1) x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3)rmses = []degrees = np.arange(1, 10)min_rmse, min_deg,score = 1e10, 0 ,0 for deg in degrees: # 生成多項式特征集(如根據degree=3 ,生成 [[x,x**2,x**3]] ) poly = PolynomialFeatures(degree=deg, include_bias=False) x_train_poly = poly.fit_transform(x_train) # 多項式擬合 poly_reg = LinearRegression() poly_reg.fit(x_train_poly, y_train) #print(poly_reg.coef_,poly_reg.intercept_) #系數及常數 # 測試集比較 x_test_poly = poly.fit_transform(x_test) y_test_pred = poly_reg.predict(x_test_poly) #mean_squared_error(y_true, y_pred) #均方誤差回歸損失,越小越好。 poly_rmse = np.sqrt(mean_squared_error(y_test, y_test_pred)) rmses.append(poly_rmse) # r2 范圍[0,1],R2越接近1擬合越好。 r2score = r2_score(y_test, y_test_pred) # degree交叉驗證 if min_rmse > poly_rmse: min_rmse = poly_rmse min_deg = deg score = r2score print('degree = %s, RMSE = %.2f ,r2_score = %.2f' % (deg, poly_rmse,r2score)) fig = plt.figure()ax = fig.add_subplot(111)ax.plot(degrees, rmses)ax.set_yscale('log')ax.set_xlabel('Degree')ax.set_ylabel('RMSE')ax.set_title('Best degree = %s, RMSE = %.2f, r2_score = %.2f' %(min_deg, min_rmse,score)) plt.show()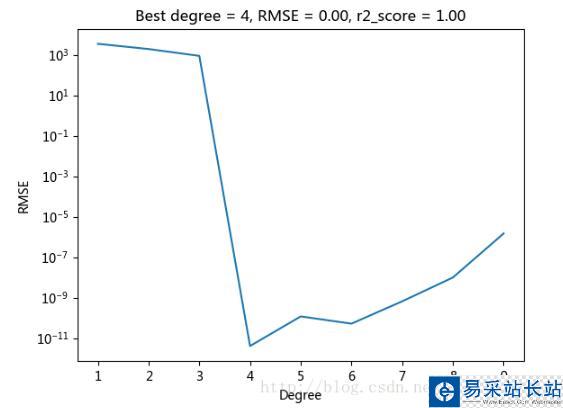
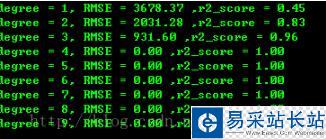
因為因變量 Y = 2*(X**4) + X**2 + 9*X + 2 ,自變量和因變量是完整的公式,看圖很明顯,degree >=4 的都符合,擬合函數都正確。(RMSE 最小,R平方非負且接近于1,則模型最好)
如果將 Y 值改為如下:
y = np.array([300,500,0,-10,0,20,200,300,1000,800,4000,5000,10000,9000,22000]).reshape(-1, 1)
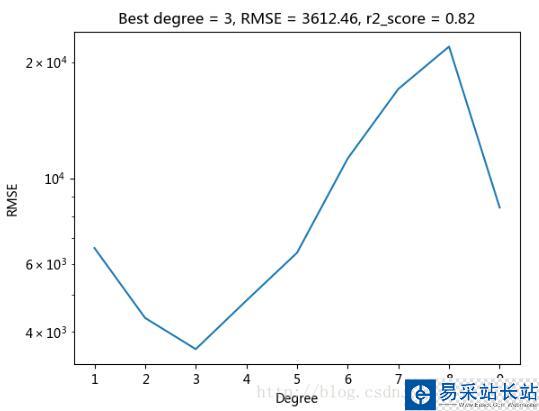
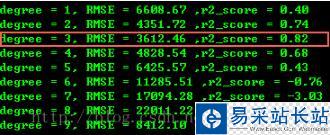
degree=3 是最好的,且 r 平方也最接近于1(注意:如果 R 平方為負數,則不準確,需再次測試。因樣本數據較少,可能也會判斷錯誤)。
以上這篇Python 確定多項式擬合/回歸的階數實例就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持武林站長站。
新聞熱點






疑難解答













